学界 | 超越何恺明等组归一化 Group Normalization,港中文团队提出自适配归一化取得突破

AI 科技评论:港中文最新论文研究表明目前的深度神经网络即使在人工标注的标准数据库中训练(例如 ImageNet),性能也会出现剧烈波动。这种情况在使用少批量数据更新神经网络的参数时更为严重。研究发现这是由于 BN(Batch Normalization)导致的。BN 是 Google 在 2015 年提出的归一化方法。至今已有 5000+次引用,在学术界和工业界均被广泛使用。港中文团队提出的 SN(Switchable Normalization)解决了 BN 的不足。SN 在 ImageNet 大规模图像识别数据集和 Microsoft COCO 大规模物体检测数据集的准确率,还超过了最近由 Facebook 何恺明等人提出的组归一化 GN(Group Normalization)。原论文请参考 arXiv:1806.10779 和代码 https://github.com/switchablenorms
背景解读:
*ImageNet 是大规模图像识别数据库。由斯坦福大学李飞飞教授在 2009 年建立。在 ImageNet 中识别率的竞赛,被称为计算机视觉的奥林匹克竞赛。
*Microsoft COCO 是目前使用最广泛的物体检测与分割数据集。每年举办的 COCO Challenge 吸引了大量国内外著名企业与实验室参与,包括 Google,Facebook,Berkely 等等。
*BN(批归一化)是由 Google 在 2015 年提出的一种归一化方法。至今已经被引用了 5000 余次,在学术界与工业界广泛使用。几乎所有主流神经网络结构都使用了BN,例如微软亚洲研究院提出的残差神经网络(ResNet,CVPR 2016 best paper)和由康奈尔大学提出的 DenseNet(CVPR 2017 best paper)。
*SN 是港中文团队最新提出的归一化方法。其在 ImageNet 的识别率超越了其它归一化方法。使用 SN 训练的 ResNet50 达到了 77.5% 的 top-1 识别率。这是目前在 ResNet50 模型上汇报的最高结果,超过了主流深度学习平台所提供的模型,例如 TensorFlow、PyTorch、Caffe 等。值得注意的是,这个结果甚至超过了 101 层的残差神经网络模型。该模型已经开源并提供下载 https://github.com/switchablenorms/Switchable-Normalization
我们先从一张图来看批归一化 BN 遇到的瓶颈。下图纵轴表示一个 ResNet 神经网络模型在 ImageNet 中的图像识别准确率(越高越好),横轴表示训练时更新网络的样本数量从大到小排列。蓝色线、红色线、和绿色线分别表示使用 Google 的 BN,Facebook 的 GN 和港中文提出的 SN 训练模型的准确率。可以看出,当用于更新网络的样本数量(又称「批量」)减小时,BN 模型的识别率急剧下降。例如批量等于 16 时,BN 模型相比 SN 模型识别率下降了 11%。当批量等于 8 时,BN 模型的图像识别率跌至 50% 以下。
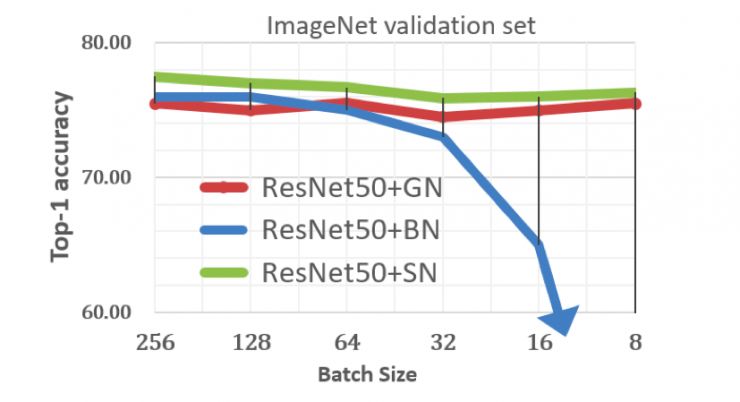
BN 导致性能下降?
BN(批归一化)是一种归一化方法。归一化一般指把数据的分布变成一个均值为 0 和方差为 1 的分布。要达到此目的,BN 在进行归一化操作时需要估计训练数据的均值和方差。由于训练数据量很大(ImageNet 有上百万数据),估计这些统计量需要大量的运算。因此,这两个统计量一般是利用一小批数据来估计的。然而,当批量较小时,例如上图的 32,这些统计量估计不准确,导致识别率开始明显下降。正如需要估计全校的平均分,只统计一个班级是不准确的。因此,BN 会导致性能损失。
既然 BN 在小批量当中效果变差,我们能否避免使用小批量进行训练呢?
为什么需要小批量学习?
原因有两点。首先,在深度神经网络的训练过程中,往往需要更新数亿级别的参数,而在很多实际应用中需要训练的图片大小又很大(例如 1000x1000 以上),使得能够放到 GPU 中的图片数量很少(通常小于 2)。这种情况经常出现在物体检测、场景分割、和视频识别等任务当中,它们在自动驾驶和视频监控中有广泛应用。然而,如前面的图所示,网络训练时的样本数量减少(小批量),使训练变得困难。总体来说,批量越小,训练过程越不稳定。Facebook 提出的组归一化(GN)正是为了解决上述问题。

图为物体检测与分割示例
其次,深度神经网络一般使用大量 GPUs 进行训练。训练方法可以分为两大类:同步训练与异步训练。同步训练代表网络参数的更新需要在多个 GPU 当中同步;异步训练是一种去中心化的方法。它比同步训练的好处在于,网络参数的更新可以在每个 GPU 当中单独进行,不需要同步。然而,由于网络占用大量内存,单独一块 GPU 只能放下少量训练样本,妨碍了参数在一块 GPU 中更新,使得异步训练无法进行。
从上述原因得知,一种对批量不敏感的技术是非常必要的。
港中文的解决方案
为了解决上述问题,港中文团队提出了自适配归一化 SN(Switchable Norm)。它统一了现有的归一化方法,例如批归一化 BN,实例归一化 IN(Instance Norm 在 16 年提出并在 arXiv:1607.08022 公开),层归一化 LN(Layer Norm 由 Geoffrey Hinton 等在 16 年提出在 arXiv:1607.06450 公开),和组归一化 GN 等。SN 允许为神经网络中不同的归一化层自动学习不同的归一化操作。与强化学习不同,SN 使用可微分学习,使得选择归一化操作能够和优化网络参数同时进行,保证优化效率的同时还保持高性能。下图为自适配归一化的直观解释。它通过学习不同的归一化方法的权重系数来选择不同的操作。
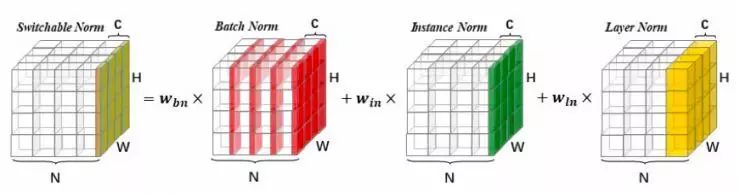
如何解决 BN 的问题
下图左边表示一个神经网络的子网络,而一个完整的神经网络往往由多达几十个子网络构成。前面提到的 ResNet 和 DenseNet 也可以归为这种结构。在一个子网络里,可以有多个 BN 层。换句话说,一个神经网络可以有上百个 BN 层。
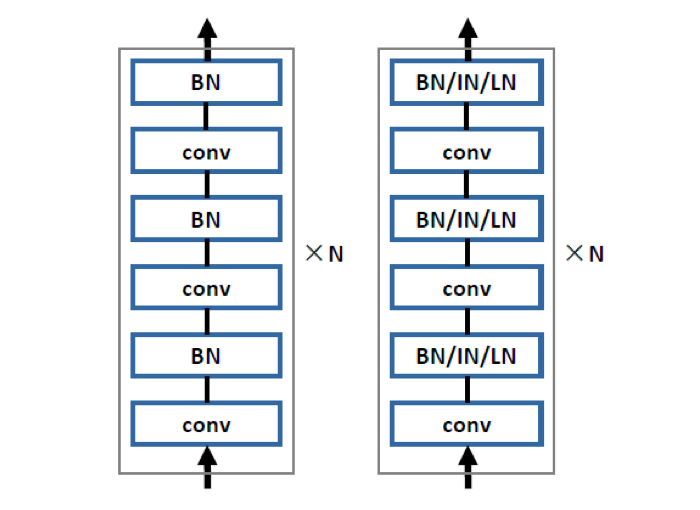
我们称一个 BN 所在的层为一个归一化层。那么为什么在主流神经网络结构中,所有的归一化层都只采用 BN 呢?
目前几乎所有的神经网络的全部归一化层都使用同样的归一化操作。这是因为手工为每一个归一化层指定操作需要进行大量的实验验证,耗时耗力。
由于这个问题,使得深度学习系统达不到最优性能。直观地说,港中文团队相信归一化操作应该可以通过学习得到;不同的归一化层应该允许自由的使用不同的归一化操作。如上图右边所示,子网络中的所有归一化层会使用 SN。它能够为每一个归一化层学习归一化策略,可能是 BN,IN,LN,GN 或者它们的组合。
SN 学习不同归一化策略的组合,避免了 BN 对小批量特别敏感的问题。
如最前面的图所示,当批量逐渐减小时,SN 的识别率保持最优。
SN 与 GN 的比较
组归一化 GN 是由 Facebook 何恺明等最新提出的归一化方法。该方法为了解决批归一化 BN 在小批量优化时性能下降明显的问题。直观地说,批量越小,训练越不稳定,训练得到的模型识别率越低。何恺明团队通过大量的实验验证了 GN 的有效性:例如在 ImageNet 当中,GN 在小批量条件下获得的识别率远远高于 BN 的识别率。但是,在正常批量条件下,GN 的识别率并不如 BN。
如前面所说,SN 是为了解决在神经网络不同的归一化层中自动学习归一化操作而提出的。港中文团队发现,SN 与 GN 一样能够在小批量条件下获得高识别率。并且,SN 在正常批量条件下超过 GN,甚至还超过了 BN。例如,在批量为 256 的情况下,用 SN 来训练的 ResNet50 在 ImageNet 的精度可以达到 77.5% 以上,而用 GN 和 BN 来训练的网络的精度分别为 75.9% 和 76.4%。
结果
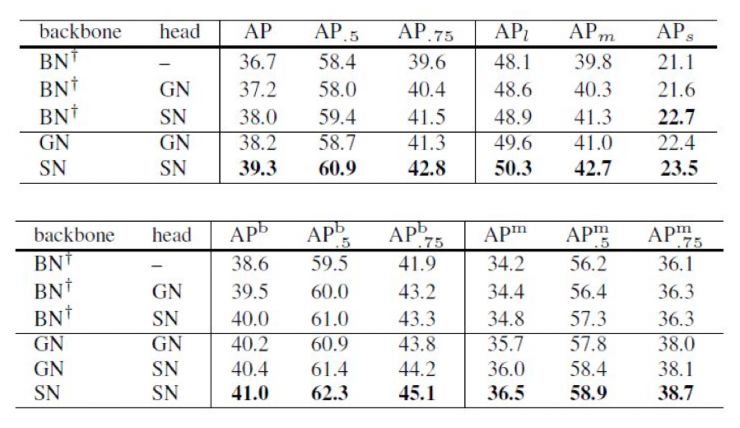
港中文团队验证了自适配归一化 SN 在多个视觉任务中的性能,包括图像识别、物体检测、物体分割、视频理解、图像风格化和循环神经网络如神经网络结构搜索。下面以物体检测为例,比较 SN,BN 和 GN 在 Microsoft COCO 物体检测数据集中的检测结果。
与图像分类不同,对于物体检测和分割任务,每个 GPU 中图片的数量通常只有 1 到 2 张。在这种情况下,BN 的效果会明显下降。而 SN 能够有效拓展到不同的检测模型,以及不同的深度学习平台上。下表展示了 SN 在 Mask R-CNN 和 Faster R-CNN 上的结果,可以看到 SN 在各项精度指标下保持了领先。
原论文同时展示了 SN 在图像风格化,以及网络结构搜索上的效果,详情可见论文。
相关文献:
1. BN: S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015
2. GN: Y. Wu and K. He. Group normalization. arXiv:1803.08494, 2018
3. SN:Ping Luo, Jiamin Ren, Zhanglin Peng,Differentiable Learning-to-Normalize via Switchable Normalization,arXiv:1806.10779,2018
┏(^0^)┛欢迎分享,明天见!



