天啦噜!在家和爱豆玩"剪刀石头布",阿里工程师如何办到?

阿里妹导读:如今,90、00后一代成为消费主力,补贴、打折、优惠等“价格战”已很难建立起忠诚度,如何与年轻人建立更深层次的情感共鸣?互动就是一种很好的方式,它能让用户更深度的参与品牌/平台呈现的内容,提供更深层的参与感,提升用户对品牌/平台的认同感和满意度。
今天,我们一起看看这些趣味互动技术背后的秘密。
一. 背景
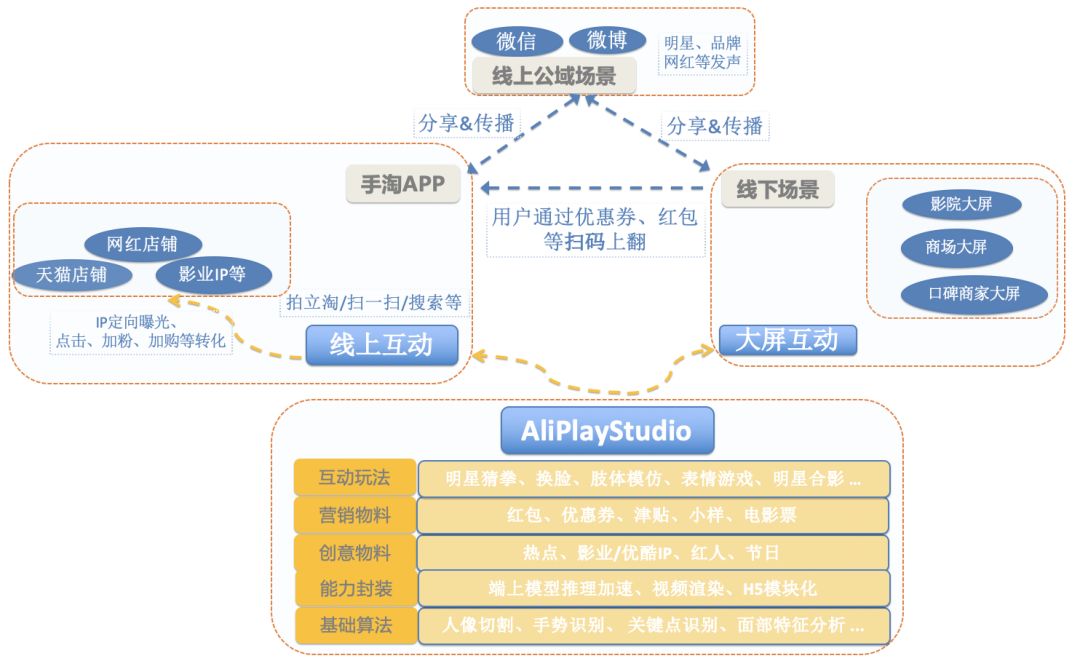
最近一年以来,阿里巴巴搜索事业部和浙江大学宋明黎教授团队联合打造了手淘视频互动平台(AliPlayStudio),分别落地线上互动、线下大屏互动多个场景(线上手淘APP的拍立淘、扫一扫、搜索关键词入口;线下商场大屏、影院互动大屏等)。接入阿里集团内天猫品牌、阿里影业、优酷IP、淘宝网红,行业营销等各类资源,在线上线下让用户互动,打通线上公域场景 、手淘APP 、线下商超这3个流量场。以新颖的视频化互动方式,利用用户对明星、红人、IP、新奇的玩法所产生的好奇心及聚众心理,创造全新的AI互动营销方式,同时结合权益发放、店铺加粉、商品推荐等手段,将互动用户自然转化为真正的消费者。
下面是18年双11期间上线的“明星猜拳PK”互动:

下面是结合了人像语义切割、用户年龄/性别预测的的18年天猫黑5“刷脸”活动:

下面是人脸融合的玩法:
下面是基于实时人体关键点检测的《西虹市首富》宣发互动玩法:

下面是和“黄小鹿”互动大屏在线下商场部署的“明星合图”活动:用户通过在大屏上自拍,经过人像切割后跟明星合照,用手淘扫码导流到线上关注店铺,完成照片打印。

为了打造AliPlayStudio视频互动平台,我们从基础图像算法能力到系统层面的端上模型推理加速、客户端native实现(视频、图片,Camera多输入源渲染)、H5玩法模块化等,做了大量研发工作。
本文主要介绍图像算法这块的研发工作。
端上互动用到的手势识别、POSE检测、人像语义切割等能力,涉及计算机视觉分类、检测、语义切割几个核心问题。随着这几年深度学习的发展,目前这些任务比较好的解法都是基于深度学习方法。我们的业务场景(手淘)要求模型一般能够大规模部署到手机和低性能的嵌入式设备上。这些任务尽管解决的Pipeline不一样,都会面临一个共性的问题:设计一个面向低性能平台的轻量级高效神经网络,并且能在 cpu、gpu、dsp等混合环境有高效的实现部署、运行,让网络在保持不错的性能下,尽量降低计算代价和带宽需求。
在神经网络加速方面,目前业界常用的一些方法有网络减支和参数共享、网络量化、知识蒸馏以及模型结构优化等。关于剪枝方面的研究在大模型上做的比较多,效果也比较好。但是我们模型的backbone一般是采用MobileNet/ShuffleNet这类很小的网络,剪枝在小网络上精度损失比较大,加速收益比不高。目前我们主要采用模型结构优化和知识蒸馏来提升网络性能。
我们研发的视觉互动基础算法能力中,人脸识别、人脸关键点检测,用户年龄性别预测等是已经有较好解决方案的任务,人像语义切割、手势识别、人体关键点识别、图像风格化、人脸融合这几个目前业界还没有成熟方案的任务。我们的工作重点也主要投入在后面几个任务上。
二. 人像语义切割
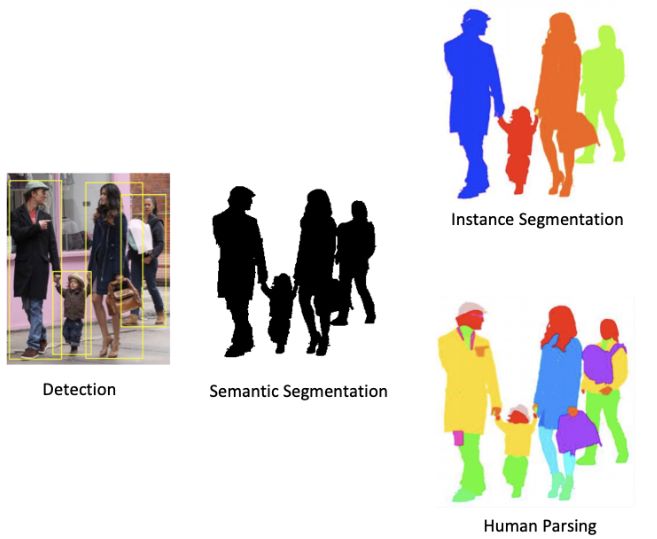
图像语义分割任务(Semantic Segmentation)根据物体的不同类别进行像素级别的标记。针对人这个特殊的类别,Human Parsing将人的各个部位(脸部/头发/四肢等)进行像素级别的区分。我们分别从数据、模型、框架优化三面着手,整体提升分割效果和体验。
在数据层面,语义切割的样本标注非常贵,我们通过图片合成创造更多样本。为了模拟真实的数据分布,分别采用了颜色迁移算法调整前背景光照、通过人位置的分布统计将人贴到合理的位置。通过人工合成高质量的数据,我们能够获得相比原来数十倍的分割样本。
在模型层面,我们分别针对图片分割场景和视频分割场景训练了高精度模型和实时模型:
语义分割网络大都采用Encoder-Decoder结构,Encoder负责提取高层语义信息,Decoder负责还原边缘分割细节。对于高精度模型,在backbone选取方面,我们采用了Inception结构。为了获得更大的感受野,我们参考DeepLab系列工作的思路,引入了ASPP(Atrous Spatial Pyramid Pooling)。
在Decoder设计上,我们参考UNet系列工作的思路,将前层的特征进行融合,以获得更好的边缘细节。整体的网络结构如下图所示:
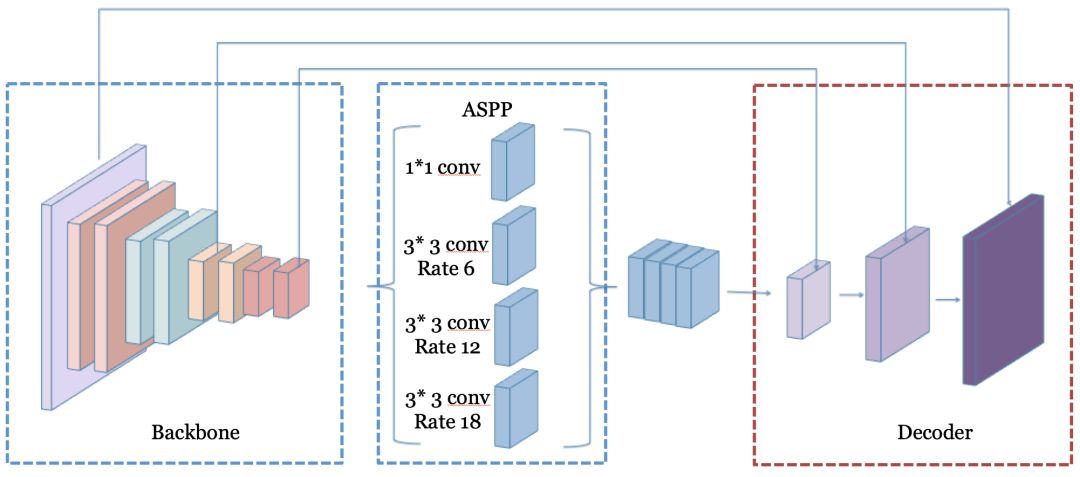
实时模型需要做到精度 / 速度的相对平衡。因此模型设计的整体原则是:Encoder尽量精简、Decoder尽量恢复细节。Encoder模块针对backbone分析耗时瓶颈,进行模型裁剪,减少channels数目;采用fast downsample,使得feature maps的大小尽可能早的缩小,以节省计算量;不固定输入大小,在不同机型下可以使用不同大小的输入。
Decoder网络在精简的基础上尽可能多的融合前层特征,提高网络整体并行度:采用类似UNet的结构,融入浅层特征;在Decoder部分也采用较大的卷积核来进一步扩大感受野;引入残差结构增加信息流动。
通过以上优化,我们的模型大小在1.7MB左右(量化后0.5M),miou 0.94,在中端Android机型(高通625)、320*240输入下,能达到25FPS,满足实时化要求。
此外针对人这个特定的类别,我们尝试加入更多关于人的先验知识来提升分割效果。分别尝试了Pose Estimation-Human Segmentation联合训练和Human Parsing- Human Segmentation联合训练。通过联合训练的方式,不同任务之间能够相互作用从而提高各个任务的精度。
下面是手机端实时切割的效果(同时加上了手势检测,识别剪刀手势来实时换背景):

下面是商场场景下的切割效果:

三. 猜拳游戏:手势识别
18年双11期间我们在手淘上线了“明星猜拳大战”玩法,受到用户大量好评。这是业界首次在手机端上实现的实时猜拳玩法。
猜拳互动要求实时检测用户的手势(剪刀/石头/布/其他),我们需要从用户视频的每一帧中找到手的位置,然后再对其进行分类,这也就是目标检测要做的事情。
虽然目标检测在近几年得到了飞速的发展,但是直接将现有模型算法用在猜拳游戏上还是会遇到一些挑战。首先由于手是非刚体,形变极大,同一个手势会表现出很多形态,再加上角度等问题,使得我们几乎不可能穷举所有可能的情况。另外,用户在切换手势的过程中会出现很多中间形态,这些形态的类别也很难确定。此外我们需要在手淘app覆盖的绝大部分中低端机型上做到实时运行,这对我们的模型运行速度提出很大挑战。
为此我们从模型架构、主干网络、特征融合、损失函数、数据等层面进行了全方位的优化,保证游戏能够在大部分移动端上都能够正常运行。具体的,在模型架构上我们采用了经典的SSD框架,因为SSD速度快、效果好、易扩展;主干网络借鉴了最新的MNasNet,进行了深度的优化,使其速度和精度进一步提升;特征融合用的是改进版的特征金字塔FPN,使其融合能力更强更高效。最终我们的模型优化到只有1.9M,双十一手淘的线上ios设备平均运行时间17ms,在测试集上的AP(IoU=0.5)达到了0.984。

四. 人体关键点检测
人体关键点检测任务是针对RGB图片或视频输入,检测其中人物的头、颈、肩、腕、肘、髋、膝、踝等骨骼关键点。传统的基于视觉的关键点检测技术一般需借助Kinect等特殊的摄像头设备,解决方案成本高,且不易扩展。而近年来学术界利用深度学习的相关工作又重在追求精度,模型设计复杂,速度比较慢且需要占用大量存储空间。 我们在平衡计算量和精度上做了大量探索和实验,提出一个能在手机端上实时运行的高精度人体关键点检测模型。具体来说,我们借鉴了语义分割中的Encoder-Decoder模型,引入MobileNet系列轻量级网络作为backbone提取高层语义信息,然后decoder使用转置卷积进行上采样恢复稠密输出,同时也使用了open pose工作的PAF(Part Affinity Fields)模块进行两路输出预测。
模型在高通骁龙845上运行单帧图片(320*320输入)只需要11ms,在RK3399这种低端嵌入式芯片上也可以跑到15fps,预测精度能够很好的支持我们线上线下的互动场景,且模型大小仅2.5M。下面是我们多人实时关键点识别在RK3399上跑的效果:

五.图像风格化
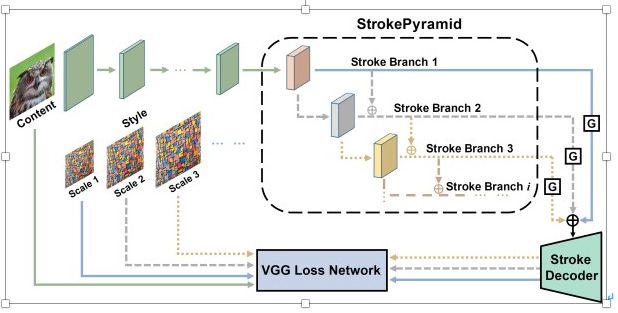
图像风格化算法的目标是在保持内容图的高级语义信息不变的情况下,将风格图的风格迁移到内容图。 风格化算法一般有2类:慢速、快速风格化,我们的互动场景下只适合后者: 对特定风格图训练前向神经网络模型,在测试的时候只需要一次前向即可得到响应结果。虽然快速图像风格化算法的速度较快,但是与此同时带来的一个缺点是风格迁移过程中很多因素变得不可控,比如笔触大小。 给定一个预训练好的网络和一张固定大小的内容图,输出的风格化结果图的笔触大小是固定的,无法让用户进行笔触大小的灵活控制, 即无法实现精细的任意连续笔触大小控制。针对此问题,我们和浙江大学宋明黎老师团队合作,提出了一个笔触大小可控的图像风格化迁移算法。
我们设计了一个笔触金字塔结构,通过笔触金字塔(StrokePyramid),把整个网络划分为了很多不同笔触分支,下面的分支通过在前一分支的基础上增加卷积层的方式获得了更大的感受,并利用不同的感受野,使用不同尺度大小的风格图进行训练,之后通过在特征空间进行笔触特征插值(stroke interpolation),来实现任意的连续笔触大小控制。在测试阶段,笔触金字塔通过门函数来控制网络的感受野,从而产生出与感受野对应的不同的笔触大小。
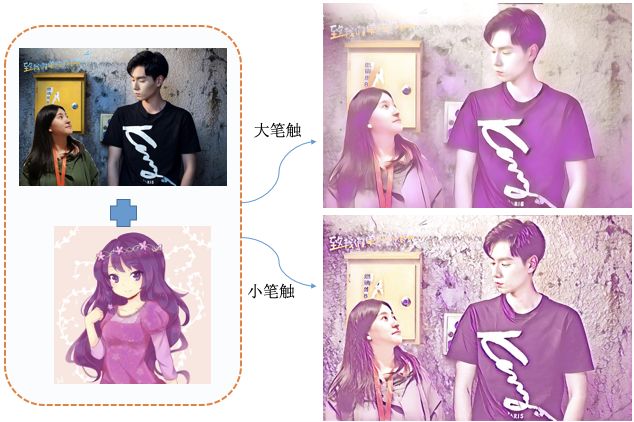
下面是我们在明星合图活动上应用的不同笔触风格迁移效果。
对于1024×1024 大小的测试图,我们的模型在NVIDIA Quadro M6000上只需要0.09s的时间,模型大小为0.99MB。
我们的工作发表于ECCV 2018上,具体见论文:Stroke Controllable Fast Style Transfer with Adaptive Receptive Fields.
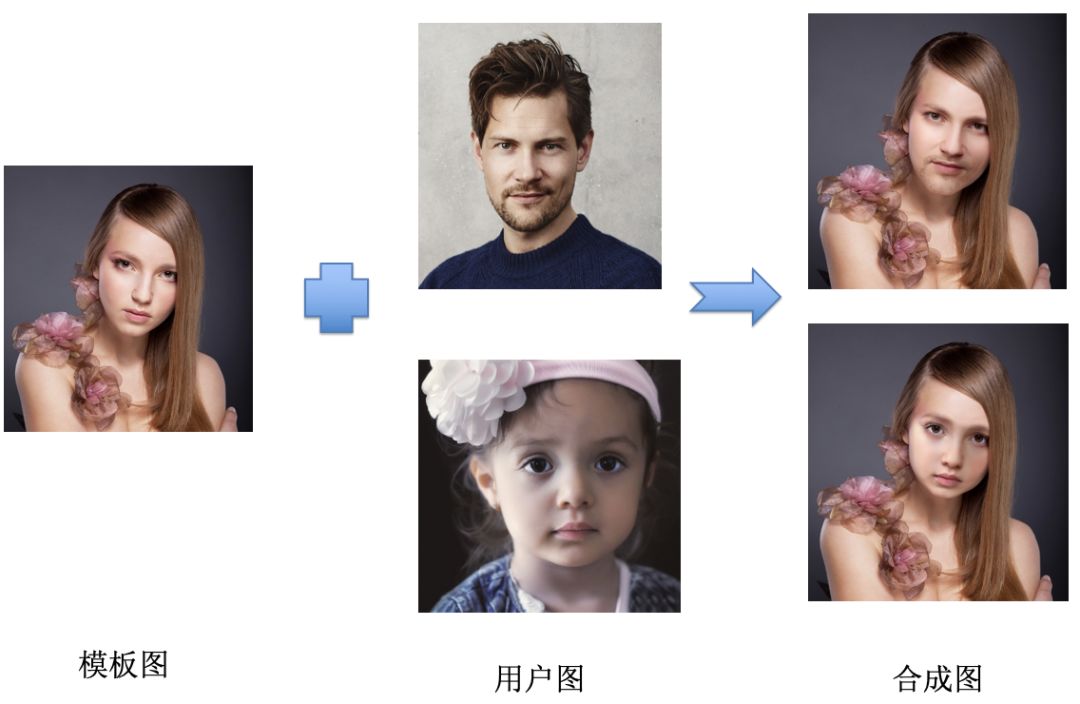
六.人脸融合
人脸融合是将用户自拍图片的人脸与模板图的人脸进行融合,融合以后,模板图的人脸呈现出用户人脸的五官特征与脸型轮廓,并保持原模板图的发饰、穿着,以此达到以假乱真的效果,实现“换脸”。 简单实现人脸融合并不困难,但是,如果想使得绝大多数的用户图片都能呈现满意的效果并不容易,有许多细节问题,其中最主要的两个问题是人脸变形与图像融合:
用户在自拍的时候,拍摄的角度多种多样,无法做到与模板图的人脸保持相同的角度。如果只做简单的变形就将用户的人脸贴到模板上,会造成十分诡异的效果。
用户所使用的拍照设备各异,拍照环境各异,会产生不同的像素与光照环境的图片,这些图片中存在大量白平衡失调、皮肤高光等的错误。
如何对这些质量不足的图片进行处理,使得融合后仍然能够产生高质量的融合图片,是人脸融合中必须解决的问题。 我们的方法获得了完善的用户脸部关键点,在尽可能保持用户五官脸部形状的同时,利用关键点插值对其进行变换,保证了五官的和谐,同时,针对用户不同的脸型,如圆脸、尖脸,对模板图进行了变换,使得融合后得到的结果与用户更加相似。 为了解决用户照片质量各异的问题,我们利用皮肤在颜色空间上的特征值,采用预定义的LUT(LookUpTable),将用户的肤色与模特肤色进行了统一,并有效处理了高光的问题,使得低质量的图片也能够得到良好的融合效果,并且观感上更加受用户喜爱。

七. 总结
从18年3月份以来,我们以活动营销的方式,在手机淘宝app内拍立淘、扫一扫、搜索等产品落地了十多场视觉互动IP营销活动。
譬如《西虹市首富》《碟中谍6》的影视IP宣发、双11《明星猜拳大战》、天猫国际黑5“刷脸”活动、双12"AI看相"、元旦"淘公仔"新年签活动。新鲜的AI互动技术结合有趣的创意,受到用户好评,引发在微博等平台上大量自发参与、传播讨论。
同时我们也与线下互动大屏场景鹿合作,其线下拍照互动产品“黄小鹿”部署在全国各大商场。我们为其提供了基础的人像语义切割等能力,从18年8月份开始陆续上线了健乐多、弹个车、婚博会糖类、贝壳租房等品牌宣传活动以及双十一天猫线下快闪店、万圣节等活动。 后面我们将通用互动提炼,进行平台化沉淀。让更多的品牌,尤其是中小品牌能够通过平台快速配置产出一套AI互动营销活动,再借助其站外推广资源引导用户回流,提升活动参与热度,赢得平台内更多推广资源。既能给品牌客户提供强有力的营销抓手,实现“财丁两旺“,又能为平台带来用户增量,从而实现双赢。
最后,感谢阿里巴巴-浙江大学前沿技术联合研究中心(AZFT)对本项目的支持。

你可能还喜欢
点击下方图片即可阅读

阿里去年新增12亿行代码;即将开源自研科学计算引擎、图学习框架;行人重识别算法斩获世界第一|周博通

如何“神还原”数据中心?阿里联合NTU打造了工业级精度的仿真沙盘


关注「阿里技术」
把握前沿技术脉搏