“爸爸,什么是机器学习呀?”
原作:Daniel Tunkelang
安妮 编译自 Quora
量子位 出品 | 公众号 QbitAI
爸爸,什么是机器学习呀?
难以回答!抓了抓开始脱发的脑壳,爸比还是被这个问题KO了。这个有些学术的问题,如何给孩子解答?
近日,计算机科学博士Daniel Tunkelang就在Quora上回答了这个问题——

不如我们由机器学习中的分类问题入手,教计算机学习哪些食物好吃,哪些难吃。
和人类不一样,计算机没有嘴巴,不能品尝食物。所以,我们需要用很多食物样例(标记的训练数据)教会计算机。这项样例中有美味的食物(正例),也有恶心的(负例)。对于每个被标记的示例,我们给计算机提供了描述食物(特征)的方法。
正例被标记为“美味”,比如巧克力冰淇淋、披萨、草莓等。负例被标记为“恶心”,比如凤尾鱼、花椰菜和球芽甘蓝。
在真正的机器学习系统中,你可能需要更多的训练数据,但3正3负的例子够我们了解概念了。

现在,我们需要一些特征。不妨就将这些样例设置为甜、咸和蔬菜三个特征,因为为二元特性,所以每种食物的每个特征都被赋予“是”或“否”的值。
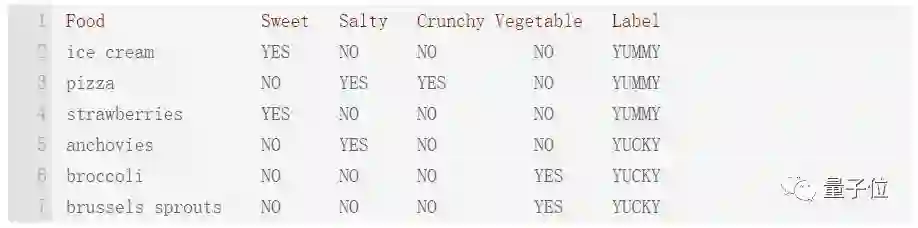
有了这些训练数据后,计算机的工作就是从这些数据中总结一个公式(模型)。这样,当它会遇到新食物时,它能根据模型决定食物是美味还是恶心的。
一种模型是点系统(线性模型)。如果具备每个特性,就会得到一定分数(权重),如果不具备就没有分数。然后,模型将食物的点数加起来,得到最终分。
模型里有一个分界点,若得分高于分界点,模型就判定食物美味;如果分数低于分界点,就判定为难吃。
根据训练数据,模型中的特征分可能会被设置为甜3分,咸1分,松脆1分,蔬菜为-1分。则巧克力冰淇淋、披萨、草莓、凤尾鱼、花椰菜、和球芽甘蓝在模型中的得分如下:
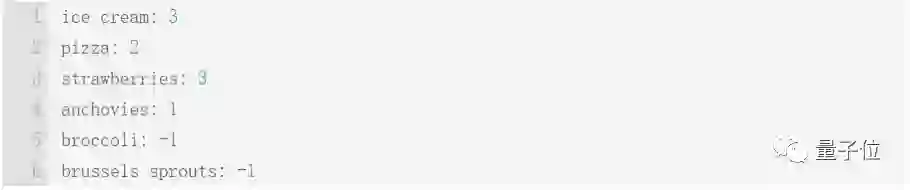
权重让选择分界点更容易,因为正例都得分≥2,负例得分≤1。
总能正确找到权重和分界点不太容易。即使找到了,最终可能会得到一个只适用于这个训练数据的模型,但当我们用新例子时,模型效果就没这么好了(过度拟合)。
理想的模型不仅在训练数据中正确率高,在新例中仍然有效(泛化)。通常,简单模型比复杂模型(奥卡姆剃刀)更容易一般化。
我们可以不使用线性模型,构建决策树也是个好方法。在决策树中,只能问能用“是”和“否”回答的问题。
用训练数据让决策树答对并不难,在这个示例中训练数据是这样利用的:
这是蔬菜吗?
如果是,则难吃。
如果不是,那它是甜的吗?
如果是,则好吃。
如果不是,那它是松脆的吗?
如果是,则好吃。
如果不是,则难吃。
如同线性模型,我们需要担心过度拟合,不能让决策树太深。所以这意味着最终可能会有一个模型,虽然在我们的训练数据上会犯错,但能对新数据更好泛化。
希望孩子能听懂这个机器学习的解释~
最后,原文地址(请注意科学前往):
https://www.quora.com/How-do-you-explain-machine-learning-to-a-child/answer/Daniel-Tunkelang
— 完 —
加入社群
量子位AI社群10群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态



