深度学习三十问!一位算法工程师经历30+场CV面试后总结的常见问题合集(含答案)

极市导读
作者灯会为21届中部985研究生,凭借自己整理的面经,去年在腾讯优图暑期实习,七月份将入职百度cv算法工程师。在去年灰飞烟灭的算法求职季中,经过30+场不同公司以及不同部门的面试中积累出了CV总复习系列,此为深度学习上篇。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一位算法工程师从30+场秋招面试中总结出的超强面经—语义分割篇(含答案)
一位算法工程师从30+场秋招面试中总结出的超强面经——目标检测篇(含答案)
优化算法
1.梯度下降法原理
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function , example ,params)
params = params - learning_rate * params_grad
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
2.梯度下降算法改进
3.牛顿法
Batch Normalization

def batchnorm_forward(x, gamma, beta, eps):
N, D = x.shape
#为了后向传播求导方便,这里都是分步进行的
#step1: 计算均值
mu = 1./N * np.sum(x, axis = 0)
#step2: 减均值
xmu = x - mu
#step3: 计算方差
sq = xmu ** 2
var = 1./N * np.sum(sq, axis = 0)
#step4: 计算x^的分母项
sqrtvar = np.sqrt(var + eps)
ivar = 1./sqrtvar
#step5: normalization->x^
xhat = xmu * ivar
#step6: scale and shift
gammax = gamma * xhat
out = gammax + beta
#存储中间变量
cache = (xhat,gamma,xmu,ivar,sqrtvar,var,eps)
return out, cache
def batchnorm_backward(dout, cache):
#解压中间变量
xhat,gamma,xmu,ivar,sqrtvar,var,eps = cache
N,D = dout.shape
#step6
dbeta = np.sum(dout, axis=0)
dgammax = dout
dgamma = np.sum(dgammax*xhat, axis=0)
dxhat = dgammax * gamma
#step5
divar = np.sum(dxhat*xmu, axis=0)
dxmu1 = dxhat * ivar #注意这是xmu的一个支路
#step4
dsqrtvar = -1. /(sqrtvar**2) * divar
dvar = 0.5 * 1. /np.sqrt(var+eps) * dsqrtvar
#step3
dsq = 1. /N * np.ones((N,D)) * dvar
dxmu2 = 2 * xmu * dsq #注意这是xmu的第二个支路
#step2
dx1 = (dxmu1 + dxmu2) 注意这是x的一个支路
#step1
dmu = -1 * np.sum(dxmu1+dxmu2, axis=0)
dx2 = 1. /N * np.ones((N,D)) * dmu 注意这是x的第二个支路
#step0 done!
dx = dx1 + dx2
return dx, dgamma, dbeta
二、基础卷积神经网络
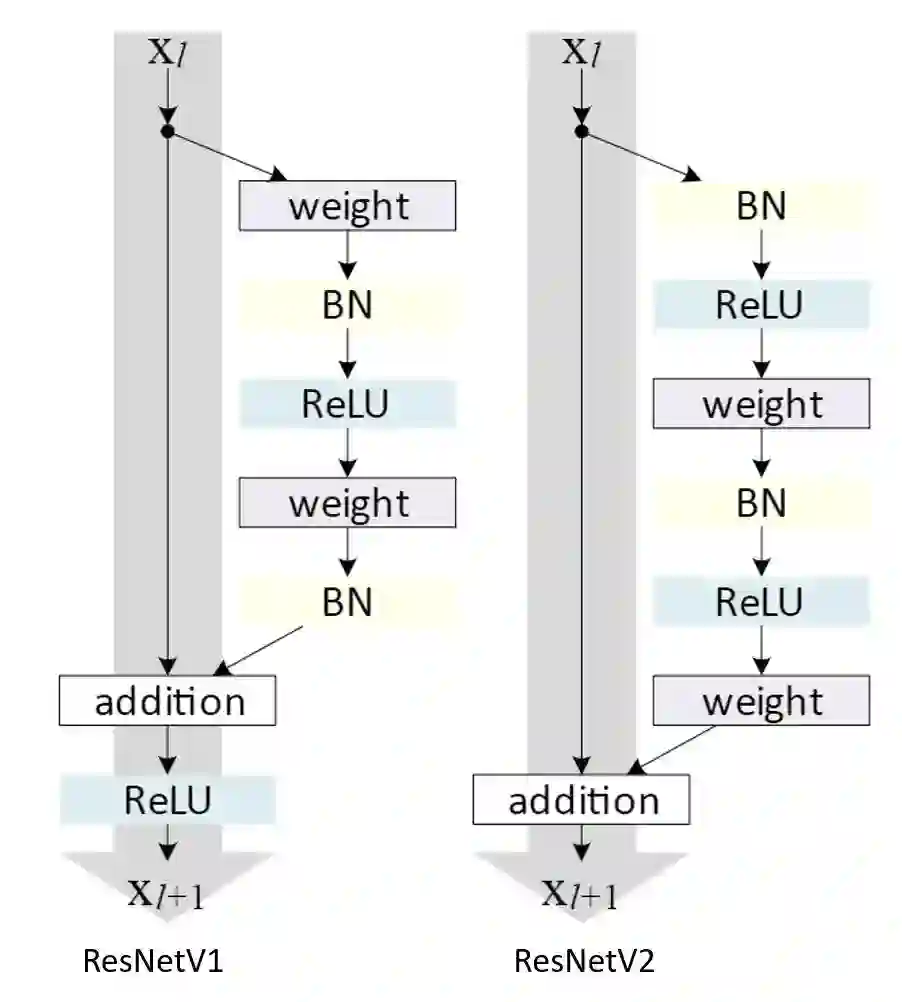
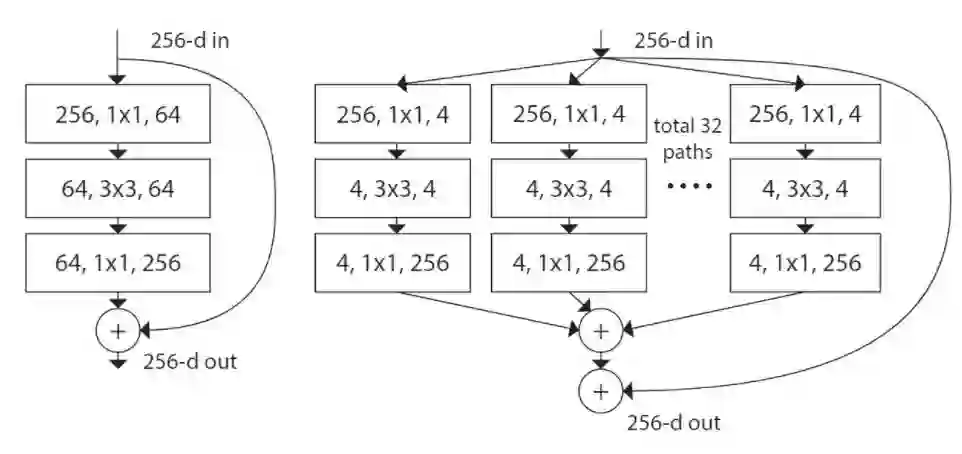
三、损失函数
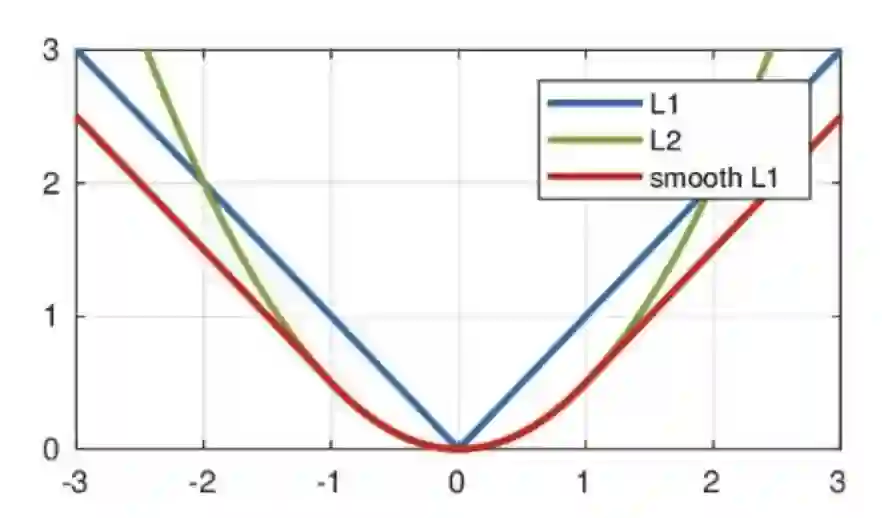
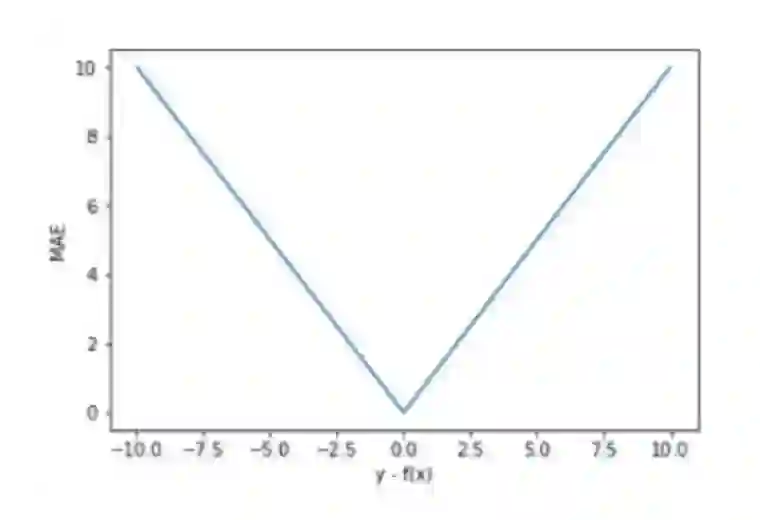
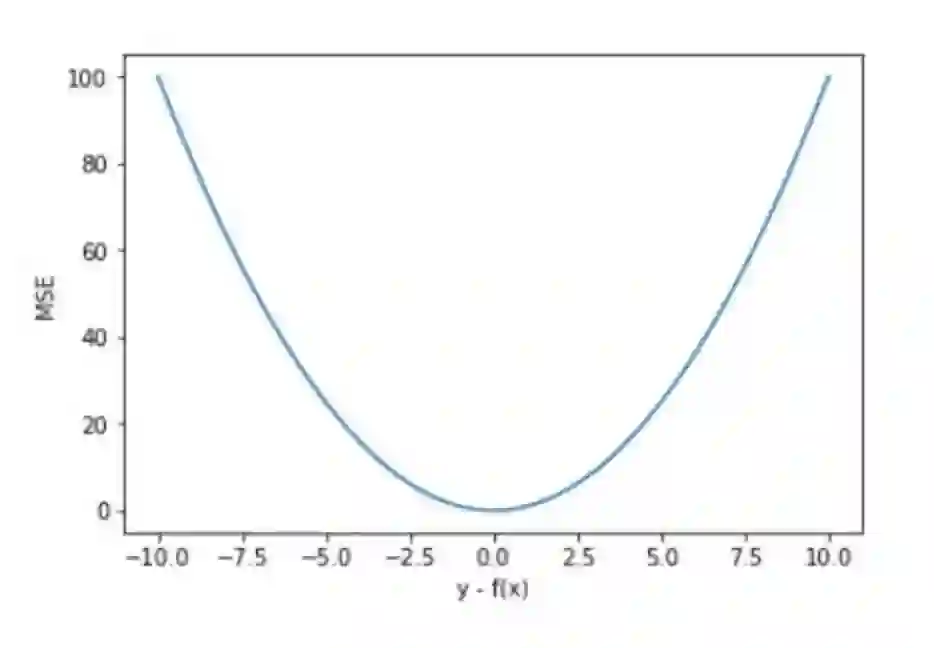
参考文献
参考链接
公众号后台回复“长尾”获取长尾特征学习资源~

# 极市原创作者激励计划 #


登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文