ICCV 2019 | 爱奇艺提出半监督损失函数,利用无标签数据优化人脸识别模型

论文发表于ICCV 2019
作者 | 爱奇艺技术产品团队
编辑 | 唐里
论文标题:Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition
论文链接:https://arxiv.org/abs/1910.10896v1
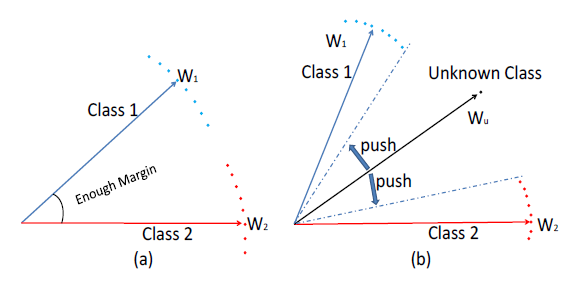
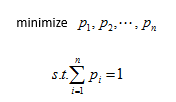
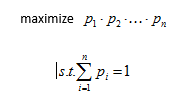
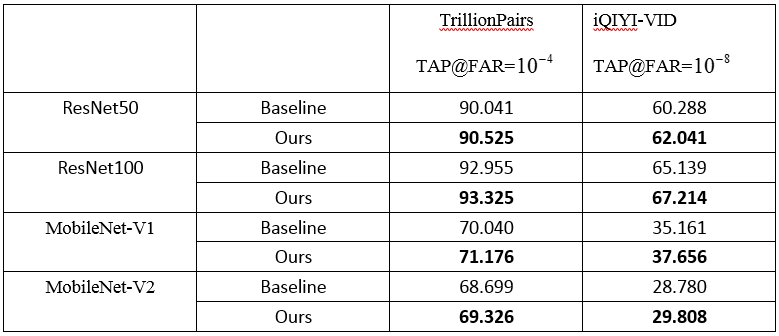
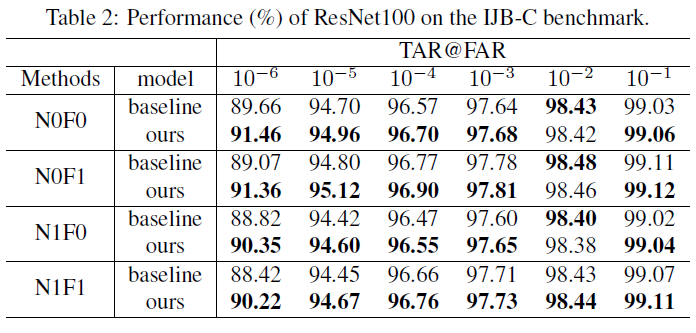
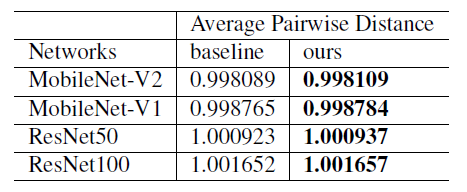
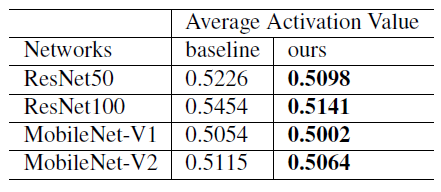
因此得到UIR loss,即:
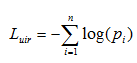
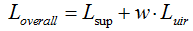
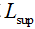 和
和
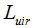 。
。


 点击“阅读原文”查看更多论文
点击“阅读原文”查看更多论文
登录查看更多
相关内容
专知会员服务
24+阅读 · 2020年4月4日
Arxiv
3+阅读 · 2018年3月26日




相关VIP内容
专知会员服务
24+阅读 · 2020年4月4日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年3月26日