利用视频物体跟踪实现移动端Video Tagging


视频社交时代的来临使得社交中的主要传播内容从文字、图片演变成短视频。诸如天天p图,美图秀秀等图片编辑应用,对短视频的编辑需求也随之应运而生。视频滤镜(filter)、视频内容风格化(stylization)以及视频打标(tagging)等功能的出现也为计算机视觉、视频处理领域提供了更广阔的想象空间。
本文中,我们将阐述利用计算机视觉中经典的视频目标跟踪算法来实现轻量级的视频tagging功能,从而可以生成更加丰富,个性化的视频内容。
Video tagging一般是指用户在视频任一帧图像中选取一块感兴趣物体添加sticker,与静止图像不同,由于视频具有时序性,我们希望在视频序列中该物体出现的任意帧中,都能够将添加的sticker展现出来,这就与计算机视觉中的视频跟踪算法不谋而合。
我们的视频tagging框架如下图所示。当拍摄完一段视频进行预览时,在某一帧时添加目标,接着从该帧开始依次进行后向和前向跟踪,计算该目标在视频序列中每一帧的位置。
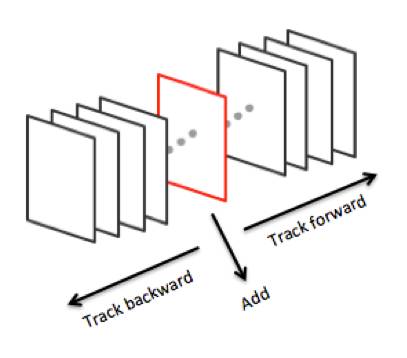
图1 video tagging框架示意图
虽然近年来包括相关滤波 [1]、siamese网络 [2]、RNN 等优秀的跟踪算法层出不穷,但考虑到移动端的速度和模型大小限制,我们还是采用经典的 TLD 跟踪框架来作为我们算法的baseline。
TLD(Tracking-Learning-Detection) [3] 是英国萨里大学的一个捷克籍博士生 ZdenekKalal 在其攻读博士学位期间提出的一种新的单目标长时间(long term tracking)跟踪算法。该算法与传统跟踪算法的显著区别在于将传统的跟踪算法和传统的检测算法相结合来解决被跟踪目标在被跟踪过程中发生的形变、部分遮挡等问题。同时,通过一种改进的在线学习机制不断更新检测模块的目标模型及相关参数,从而使得跟踪效果更加稳定、鲁棒、可靠。
TLD算法对每一帧图像对处理过程,都包含跟踪、检测和学习三个部分。如下图所示。通过将跟踪和检测的结果进行融合,得到每帧的目标估计位置,另一方面在新的目标预测位置上进行模型更新,从而提升检测器的鲁棒性。
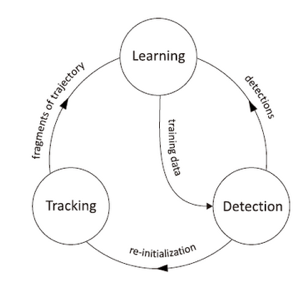
图2 TLD算法模块
由于TLD最初是为单目标跟踪设计的,而且每一帧都需要进行三部分的处理,在PC上针对VGA图像也仅能勉强达到实时的速度。为了能够移植到移动端,我们针对此框架进行了优化,力求实现快速、准确、稳定的跟踪效果。
我们改进的跟踪算法流程如下图所示。在处理流程上,不再每帧都进行检测和学习,而是在跟踪失败,即目标丢失后调用检测模块。同时,学习模块也只发生在目标发生较大变化后进行,以求达到最有效的学习,从而避免将处理时间花费在一些不需要更新策略的时刻。
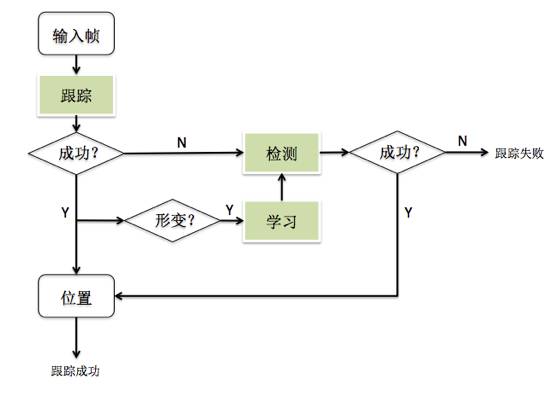
图3 跟踪算法流程
跟踪器的作用是跟踪连续帧间的运动,当物体始终可见时跟踪器才会有效。跟踪器根据物体在前一帧已知的位置估计在当前帧的位置,这样就会产生一条物体运动的轨迹,从这条轨迹可以为学习模块产生正样本。
在跟踪中,我们依然沿用Lucas-Kanade光流跟踪算法[4]。即给定若干跟踪点,跟踪器会根据像素的运动情况确定这些跟踪点在下一帧的位置。如下图所示。
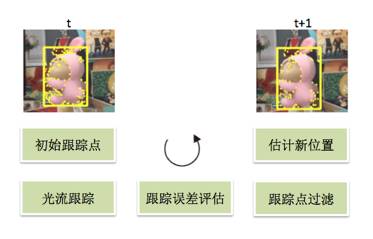
图4 跟踪器流程
1.1 跟踪点的选择
在原始TLD算法中,跟踪点采取均匀网格取点的方式,如下图a所示。此种取点方式的优点是速度快,而且不受跟踪目标区域影响,总能取到固定的点数,但缺点是获得的点往往并非图像的特征点,不具有鲜明特性无法有效反映图像本质特征,因此在跟踪中往往容易发生点漂移,使得跟踪器不够强健。基于此,我们对点的选取做了改进,改用fast点来快速提取目标区域特征点,作为跟踪器的初始点进行跟踪。

a b
图5 a) 均匀取点;b) fast特征点
1.2 跟踪误差的评估
我们采用跟踪器的FB误差(ForwardBackward Error)[5]和NCC(Normalized Cross Correlation,归一化互相关),以及SSD(Sum-of-Squared Differences,差值平方和)作为筛选跟踪点的衡量标准。
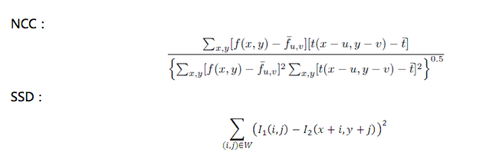
检测模块由级联分类器构成,共包括三层:随机蕨分类器(Random FernsClassifier)、最近邻分类器(Nearest Neighbor Classifier)以及特征点匹配。如下图所示。
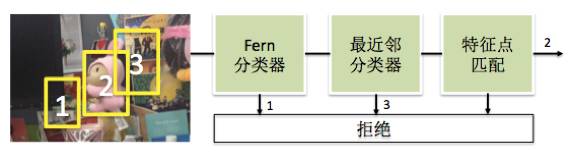
图6 级联分类器检测流程
2.1 随机蕨分类器
原始TLD算法中的FernClassifier采用树形结构,类似于随机森林(Random Forest),共包含10个弱分类器,每个弱分类器由10层节点构成,每个节点包含一对图像中的点对,通过对比两个点的像素灰度值大小生成0或1,最终所有点对的结果生成十进制特征值,通过查表计算对应的弱分类器分数值。本文中,我们对分类器做了几点优化:
1. 将弱分类器由树形结构替换成了线性结构,将10层节点减少到了6个节点,有效地减少了计算时的点对比较次数,相比原始结构检测速度提升了近一倍。
2. 在训练时,最优点对由训练样本训练(原始算法是随机初始化得到),同时训练出基于最优特征点对的弱分类器分数分布。
3. 针对线性结构特征,提出了一种更适合该结构的训练方法,使得能够在保证一定的准确率的同时,最大程度地减少弱分类器个数。
此种改进的检测方法我们之前也用于二维码的快速预判,是一种简单高效的快速检测算法。
2.2 最近邻分类器
通过计算新样本的相对相似度,如大于一定阈值,则认为是正样本,否则为负样本。具体计算公式可参考原论文。
2.3 fast特征匹配
我们在前两层级联分类器过滤后的区域中提取fast特征点,并计算其brisk特征,得到512维二值特征, 与初始目标的特征进行hamming距离计算 ,从而过滤误检,得到最终的检测结果。
学习模块主要针对目标发生较大形变时,针对“新”的检测器没有见过的目标,在线收集相关的正负样本,用于更新检测中的三种分类器,提高检测器的鲁棒性。
TLD使用的学习方法是作者提出的P-N学习(P-N Learning)[6]。P-N学习是一种半监督的机器学习算法,它针对检测器对样本分类时产生的两种错误提供了两种“专家”进行纠正:
P专家(P-expert):检出漏检(false negative,正样本误分为负样本)的正样本;
N专家(N-expert):改正误检(false positive,负样本误分为正样本)的正样本。
对于用户实时拍摄的视频,在获取图像数据的同时,我们也采集了传感器相关数据,利用对传感器数据的分析估计手机在拍摄时的运动变化,弥补视觉信息的不足。
通过对原始加速度计、陀螺仪数据的计算,我们可以估算出手机姿态角(bodyangle)的变化。以iphone为例,其三个角的定义及方向如下图所示:
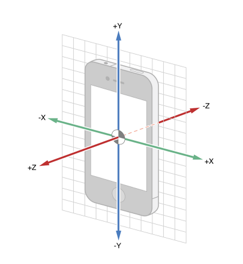
图7 iPhone三轴示意图
通过计算两帧之间手机三个方向的角度差值,可由前一帧的位置Xt利用下述公式估算出当前帧的位置 Xt+1:
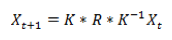
其中,
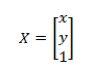
K是由相机内参组成的内参矩阵:
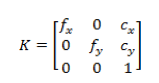
R是由三个轴角度差计算得到的旋转矩阵:
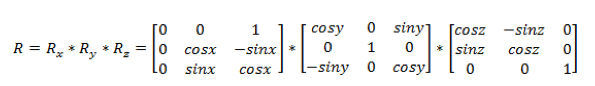
在假设只有手机旋转而目标不动的情况下,通过传感器估算的位置可以大致判定目标是否离开当前视野,从而可以减少一些不必要的检测计算等过程。
性能评估
在大部分情况下,由于每帧的处理仅针对小块图像patch做点跟踪,因此计算量极少,针对单目标,在iPhone6sp上我们的算法的平均速度可达到200fps,在iPhone5s上也能达到约67fps的速度,完全满足实时性的要求。
一些video tagging的结果如下:
快速抖动
旋转
在深度学习应用的如火如荼的今天,我们也在研究如何将深度神经网络更好地应用在跟踪中,提升对跟踪目标的描述能力,适应目标的外观、形变、光照等的变化。随着深度神经网络在移动端的更好的适配和部署,相信很快移动端目标跟踪算法的精度又会达到另一个高度。
参考文献
[1]J. F. Henriques, R. Caseiro, P. Martins,J. Batista, High-speed tracking with kernelized correlation filters.
[2]Ran Tao ,EfstratiosGavves , Arnold W. M.Smeulders, Siamese instance search for tracking.
[3]ZdenekKalal, KrystianMikolajczyk, andJiri Matas,
Tracking-Learning-Detection.
[4]Lucas B and Kanade T, An Iterative ImageRegistrationTechnique with an Application to Stereo Vision.
[5]ZdenekKalal, KrystianMikolajczyk, andJiri Matas,Forward-Backward Error: Automatic Detection of Tracking Failures.
[6] Zdenek Kalal, P-N Learning: Bootstrapping BinaryClassifiers by Structural Constraints.

 微信ID:
微信ID:
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文