无需双语语料库的无监督式机器翻译
|全文共3197字,建议阅读时长4分钟 |
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
选自:Medium
作者:Harshvardhan Gupta
参与:刘晓坤、路雪
去年,Facebook 发表论文《Unsupervised Machine Translation Using Monolingual Corpora Only》,提出使用单语语料库的无监督式机器翻译。近日 Medium 上一篇文章对该论文进行了解读,机器之心对此进行了编译介绍。
深度学习广泛应用于日常任务中,尤其擅长包含一定「人性」的领域,如图像识别。或许深度网络最有用的功能就是数据越多性能越好,这一点与机器学习算法不同。
深度网络在机器翻译任务中做得不错。它们目前在该任务中是最优的,而且切实可行,连 Google Translate 都在使用。机器翻译需要语句级别的平行数据来训练模型,即对于源语言中的每个句子,目标语言中都有对应的译文。难点在于某些语言对很难获取大量数据(来使用深度学习的力量)。
机器翻译的问题
如上所述,神经机器翻译最大的问题是需要双语语言对数据集。对于英语、法语这类广泛使用的语言来说,这类数据比较容易获取,但是对于其他语言对来说就不一定了。如能获取语言对数据,则该问题就是一个监督式任务。
解决方案
论文作者指出如何将该任务转换成无监督式任务。在该任务中,所需的唯一数据是两种语言中每种语言的任意语料库,如英语小说 vs. 西班牙语小说。注意两部小说未必一样。
也就是说,作者发现如何学习两种语言之间共同潜在空间(latent space)。
自编码器简单回顾
自编码器是用于无监督任务的神经网络的一种宽泛类别。它们可以重新创建与馈送的输入相同的输入。关键在于自编码器中间有一个层,叫作 bottleneck 层。该层可以捕捉所有输入的有趣信息,去除无用信息。
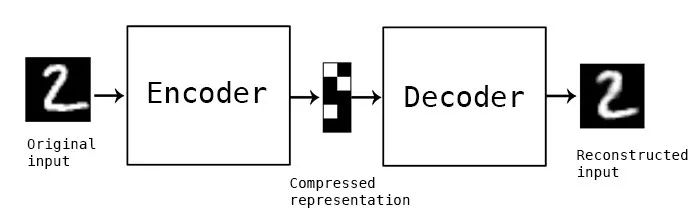
自编码器图示。中间的模块是存储压缩表征的 bottleneck 层。(图片来源:https://blog.keras.io/building-autoencoders-in-keras.html)
简言之,bottleneck 层中的输入(这里经过编码器转换)所在的空间就是潜在空间。
去噪自编码器
如果自编码器可以学会完全按照接收的馈送来重建输入,那么它或许什么都不用学了。这种情况下,输出可以被完美重建,但是 bottleneck 层中并没有有用特征。为了弥补,我们可以使用去噪自编码器。首先,向输入添加一些噪声,然后构建网络用来重建原始图像(不带噪声的版本)。用这种方式,通过让网络学习什么是噪声(以及真正有用的特征)使其学习图像的有用特征。
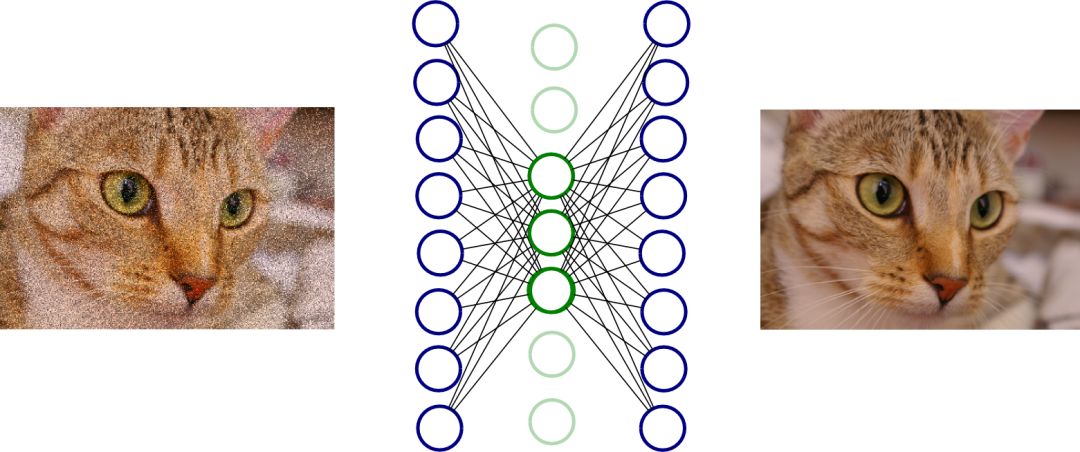
去噪自编码器图示。使用神经网络重建左侧图像,生成右侧图像。在此示例中,绿色的神经元就是 bottleneck 层。(图片来源:http://www.birving.com/presentations/autoencoders/index.html#/)
为什么要学习共同潜在空间?
潜在空间捕捉数据特征(在机器翻译中,数据是句子)。如果可以学习对语言 A 和语言 B 馈送的输入输出相同特征的空间,那么就可以实现这两种语言之间的翻译。由于该模型已经学会了正确的「特征」,那么利用语言 A 的编码器来编码,利用语言 B 的解码器解码就可以使该模型完成翻译。
如你所料,该论文作者利用去噪自编码器学习特征空间。他们还指出如何使自编码器学习共同潜在空间(作者在论文中称之为对齐潜在空间),以执行无监督机器翻译。
语言中的去噪自编码器
作者使用去噪编码器以无监督的方式学习特征。其中定义的损失函数为:
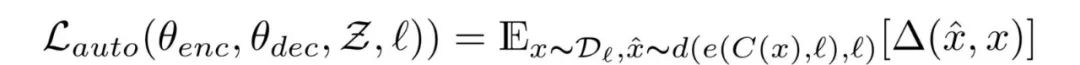
式 1.0 去噪自编码器损失函数
式 1.0 的解释
l 是语言(按其设置,应该有两种可能的语言),x 是输入,C(x) 是将噪声加到 x 之后的结果。e() 是编码器,d() 是解码器。等式末尾的 Δ(x_hat ,x) 项是 token 级别的交叉熵误差总和。由于是通过输入序列得到输出序列,我们需要确保每个 token 都以正确的顺序排列。因此最终得到了上式中的损失函数。可以将其视为多标签分类问题,其中输入中的第 i 个 token 和输出中的第 i 个 token 对比。一个 token 就是一个单元,不能再继续分解。在机器翻译中,一个单词就是一个 token。
因此,式 1.0 的作用是使网络最小化它的输出(给定带噪输入)和原始语句之间的差异。
如何添加噪声
图像处理可以通过在像素中添加浮点数来添加噪声,而在语言中添加噪声的方式是不同的。因此,论文作者开发了自己的噪声生成系统。他们用 C() 表示噪声函数。C() 以输入语句为输入,然后输出该语句的带噪声版本。
有两种添加噪声的方法。
一种是,以 P_wd 的概率从输入中删除一个单词;另一种是,每个单词以下式中的约束从初始位置偏移:
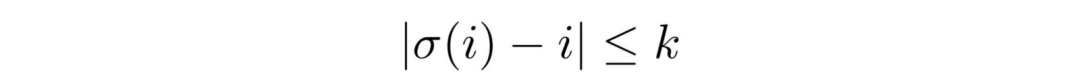
这里,σ是第 i 个 token 偏移后的位置。因此,上式的含义是「一个 token 最多可以偏离原来位置 k 个 token 的距离」。
作者使用的 k 值为 3,P_wd 值为 0.1。
跨域训练
为了学习两种语言的互译,需要构建将输入序列(语言 A)映射到输出序列(语言 B)的过程。作者称该学习过程为跨域训练。首先,采样一个输入语句 x,然后使用前一次迭代后的模型 M() 生成翻译后的输出 y,即 y=M(x)。之后,使用上述的噪声函数 C() 应用到 y 上,得到 C(y)。语言 A 的编码器将 C(y) 编码,然后由语言 B 的解码器将其解码,重构出 C(y) 的无噪声版本。训练模型时使用的是相同的交叉熵误差总和,类似式 1.0。
通过对抗训练学习共同潜在空间
论文中并没有提到如何学习共同潜在空间。上述跨域训练可能在某种程度上有助于学习类似的空间,但要使模型学习类似的潜在空间需要添加一个更强的约束。
作者使用了对抗训练。他们使用了另一个称为鉴别器的模型,以每个编码器的输出为输入,预测被编码的语句所属的语言。然后,编码器也要学习欺骗鉴别器。这在概念上和标准的 GAN 并没有什么区别。鉴别器通过每个时间步(由于使用了 RNN)的特征向量预测输入所属的语言种类。
整合所有部分
将上述的三个不同的损失(自动编码器损失、翻译损失和鉴别器损失)加在一起,所有的模型权重在一个步骤内更新。
由于这是一个序列到序列问题,作者使用了 LSTM 网络,结合注意力机制,即有两个基于 LSTM 的自编码器,每种语言使用一个。
训练该架构时有三个主要步骤。训练过程是迭代进行的。训练循环分为以下三步:
1. 使用语言 A 的编码器和语言 B 的解码器进行翻译;
2. 给定一个带噪语句,训练每个自编码器重新生成一个去噪语句;
3. 给步骤 1 中得到的翻译语句添加噪声然后重新生成,以提升翻译能力。这一步中,语言 A 的编码器和语言 B 的解码器(以及语言 B 的编码器和语言 A 的解码器)需要一起训练。
注意虽然步骤 2 和步骤 3 是分开的,但权重是同步更新的。
如何快速启动该框架
如上所述,该模型使用了之前迭代的译文来提升自己的翻译能力。因此,在训练循环开始之前,事先具备某些类型的翻译能力是很重要的。作者使用了 FastText 学习词级双语词典。注意这种方法是很粗糙的,只在模型开始时使用。
框架的完整结构如下流程图所示:
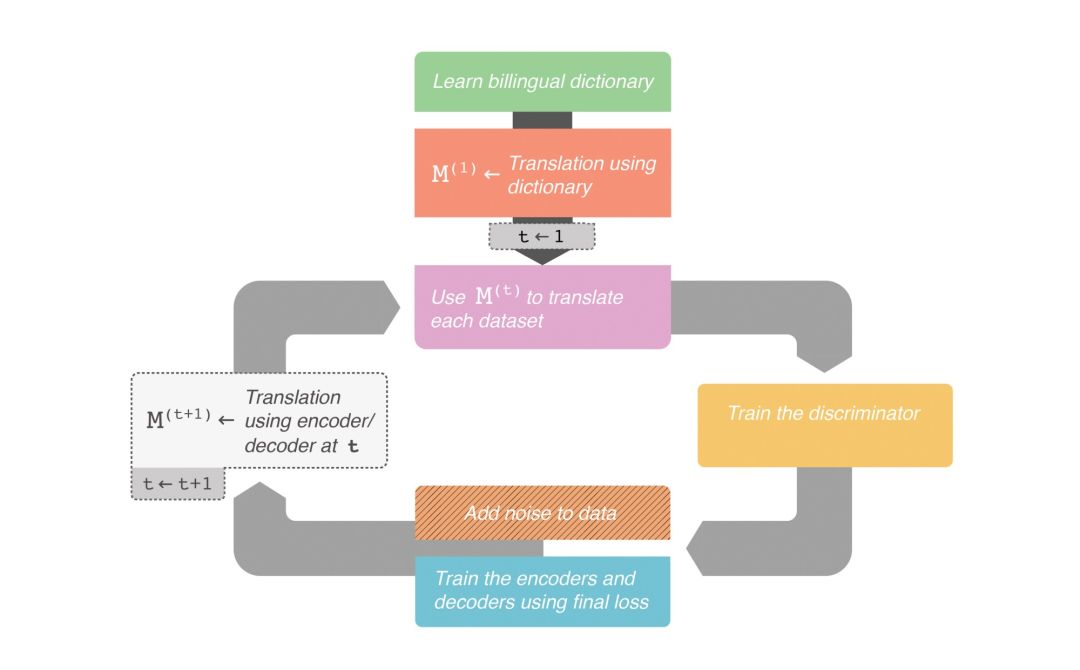
完整翻译框架的高级流程图。(图片来源:http://robertaguileradesign.com/)
结论
本文介绍了一种非常新的无监督机器翻译技术。它使用多种不同的损失函数来提升各个单独任务,同时使用对抗训练为架构行为添加约束。
原文链接:
https://buzzrobot.com/machine-translation-without-the-data-21846fecc4c0
喜欢我们就多一次点赞多一次分享吧~
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~





