问答机器人2.0!文档问答产品大PK
在之前的文章里,我们测试过百度UNIT的图形化多轮对话编辑功能TaskFlow,今天我们将带大家体验UNIT和小i机器人最新的文档问答(document-based question answering,DBQA)功能。这两家也是作者目前了解到仅有的在开放平台提供这一功能的厂商。
传统的问答机器人产品往往需要用户提供大量自己整理的问答对(FAQ)用于模型的训练或知识库的构建;但借助基于文档的问答技术用户只需上传如产品手册、宣传文档这样的文本材料便可直接产生一个问答机器人。相比于FAQ,文档问答方式将大大降低机器人的启动门槛,在实际业务场景中是很有吸引力的。
技术背景
与文档问答相关的是NLP领域里一种称为机器阅读理解(machine reading comprehension,MRC)的算法,是在近两年大热的一个领域。该领域著名的排行榜如SQuAD、CNN/Daily Mail等一直都是NLP技术的风向标,也是NLP列强的兵家必争之地。
所谓机器阅读理解,就是给出一段文章,让机器能够回答与文章相关的问题。虽然定义简单,但细节不少,阅读理解相关数据集的难度其实是渐渐提高的。以SQuAD为例,2016年斯坦福大学发布SQuAD1.0[1]版本,该数据集一共针对题材广泛的500多篇维基百科中的23000多个段落提了十万个问题,在这些问题中主要的几类提问目标是常见名词、人名、日期等等。因为这些问题的答案都可以在文章中找到,算法的目标就是在文章中标出一个能回答问题的区间(Span)。
2018年斯坦福在1.0版本数据集的基础上发布了新的SQuAD 2.0。新版数据集不仅包含了原来的所有10万条问题,还人工撰写了五万句根据文章无法回答的问题,而且这些问题都是精心设计,让它们看起来和可回答的问题非常相似。


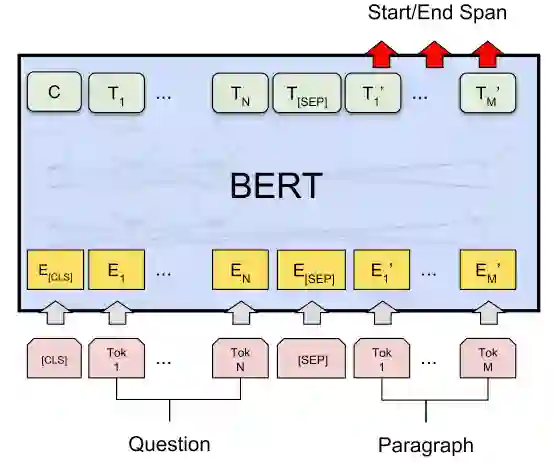
在前BERT时代,针对阅读理解的模型往往很复杂,在文章和问题、文章和标题、问题和标题间充满了各种人工设计的attention机制。而在预训练语言模型大行其道的今天,阅读理解问题的算法范式已经变得非常简单。例如在BERT[2]论文里,将问题和文章内容拼接后输入语言模型模型,然后用一个简单的2输出全连接层获得每个字词作为答案开始和结束的概率;再根据这两个概率经过简单的后处理即可得到预测的区间。
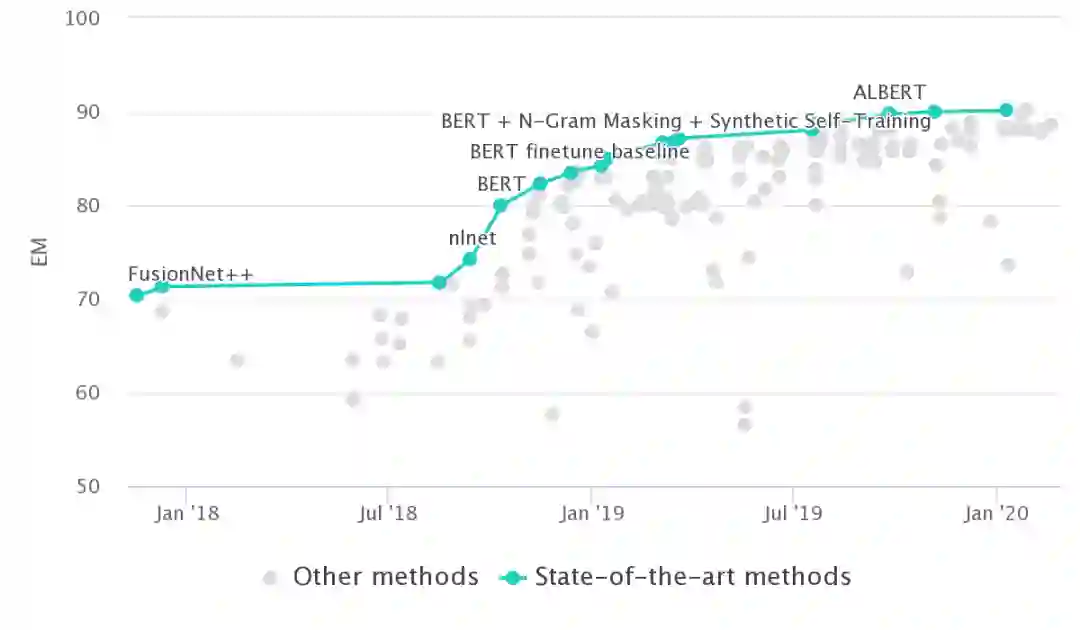
目前阅读理解问题的排行榜已经完全被各种强大的预训练语言模型占领,SQuAD2.0上的SOTA是来自上海交通大学的Retro-Reader on ALBERT[3]。精确匹配准确率达到了惊人的90.115,已经远远超过了人类86.831的水平。
虽然在一些特定的数据集上AI算法已经取得了优异的成绩,但这些都是在大量数据支撑训练下达到的结果。而在实际的应用场景中,一般的企业很难针对自身的业务场景提供如此大量的数据。
UNIT和小i的文档问答
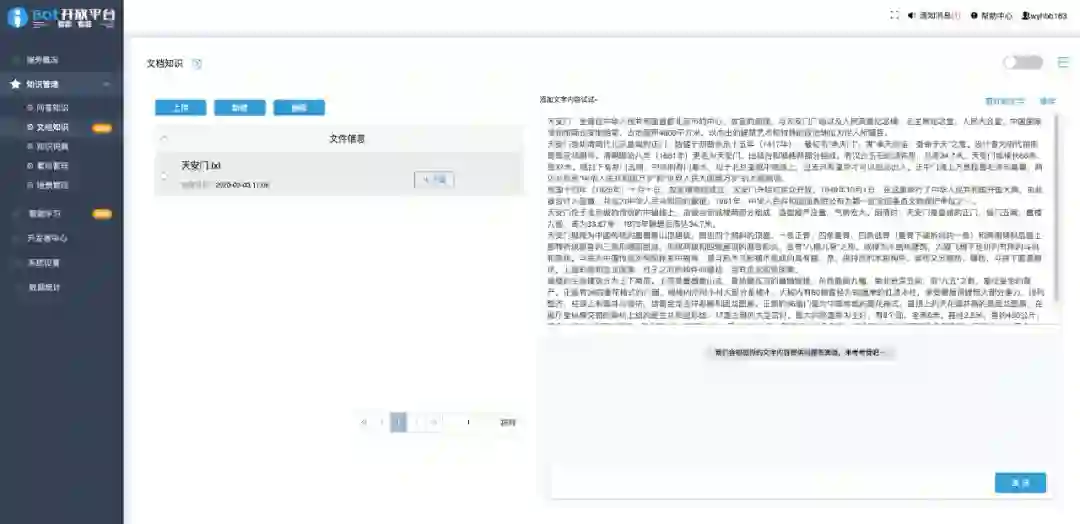
在我们看来,百度和小i敢于在实际产品中上线文档型问答是非常有勇气的,但似乎两家都将这一功能定位为体验为主。UNIT的文档问答入口并不显眼,仅仅是作为创新技术页面的三个功能之一。功能介绍写得也很直白,突出了文档问答对业务友好的特点。建立文档问答技能的操作方式也很傻瓜,准备好一个txt或者word格式的文档直接上传即可,再经过一段时间的训练就可以部署或测试模型了。

而小i的Bot开放平台将文档知识作为知识管理的一个栏目,并且非常明显地标上了Beta图标。操作方式也同样简单,上传文档即可开始测试。与百度不同的是整个过程甚至无需训练。
测试方法与结果
本次我们从百度百科的天安门词条[4]选取了一些文字作为文档。文档不长,一共500余字,包括了较大量的数字信息。针对这段文档,我们仿照SQuAD数据集人工整理了15道可回答问题和5道不可回答问题来对两家的算法进行测试。为了给大家一个直观的印象,在此摘抄第一段:
天安门,坐落在中华人民共和国首都北京市的中心、故宫的南端,与天安门广场以及人民英雄纪念碑、毛主席纪念堂、人民大会堂、中国国家博物馆隔长安街相望,占地面积4800平方米,以杰出的建筑艺术和特殊的政治地位为世人所瞩目。天安门是明清两代北京皇城的正门,始建于明朝永乐十五年(1417年),最初名“承天门”,寓“承天启运、受命于天”之意。设计者为明代御用建筑匠师蒯祥。清朝顺治八年(1651年)更名为天安门。由城台和城楼两部分组成,有汉白玉石的须弥座,总高34.7米。天安门城楼长66米、宽37米。城台下有券门五阙,中间的券门最大,位于北京皇城中轴线上,过去只有皇帝才可以由此出入。正中门洞上方悬挂着毛泽东画像,两边分别是“中华人民共和国万岁”和“世界人民大团结万岁”的大幅标语。 --百度百科天安门词条
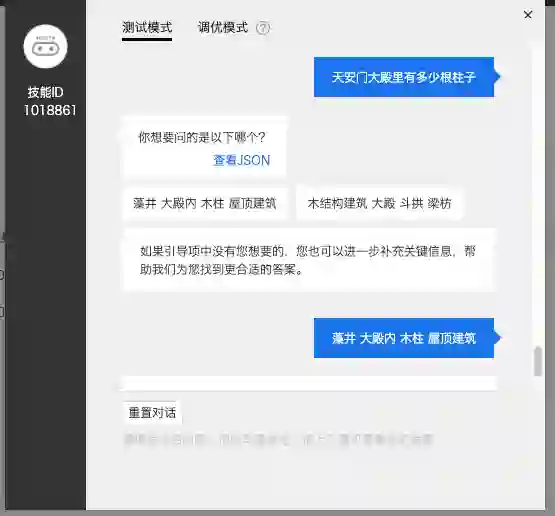
测试过程中UNIT的体验还是不错的,当它在文档中找到相关答案且置信度较高时会在聊天框回复答案所在的句子,并且用加粗字体标出可直接回答问题的信息(一个区间)。
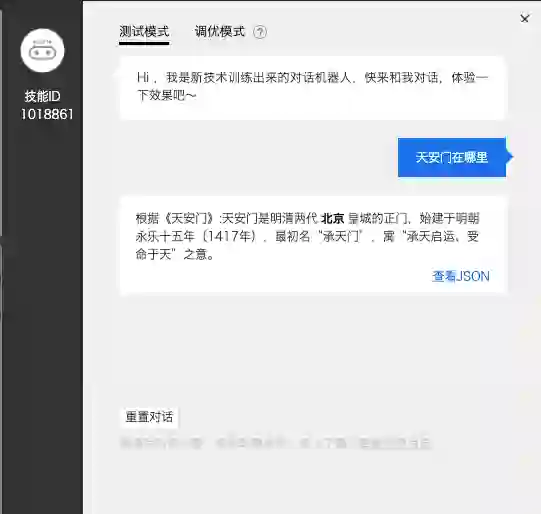
但如果UNIT没有直接命中答案则会给用户提供选项,选项稍微有点奇怪,似乎是把每句话的关键词罗列了出来。
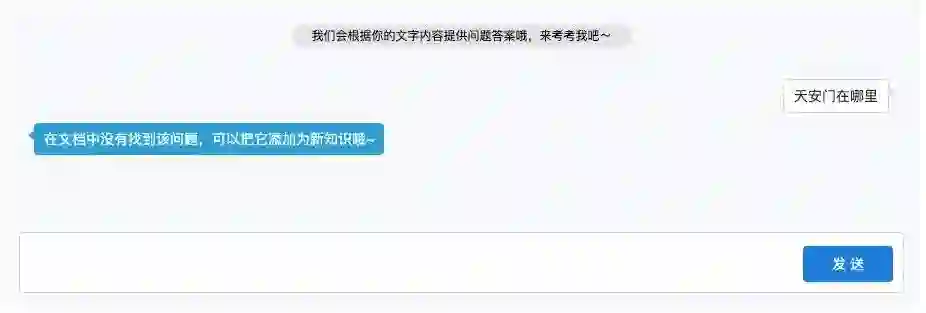
而小i则是不一样的风格,只有当他找到答案时才会回答,并且回答很简洁,就是一个词,直击问题。遗憾的是大部分时候系统都是直接提示答案未找到。虽然他的召回率较低,但回答的答案没有答错的。
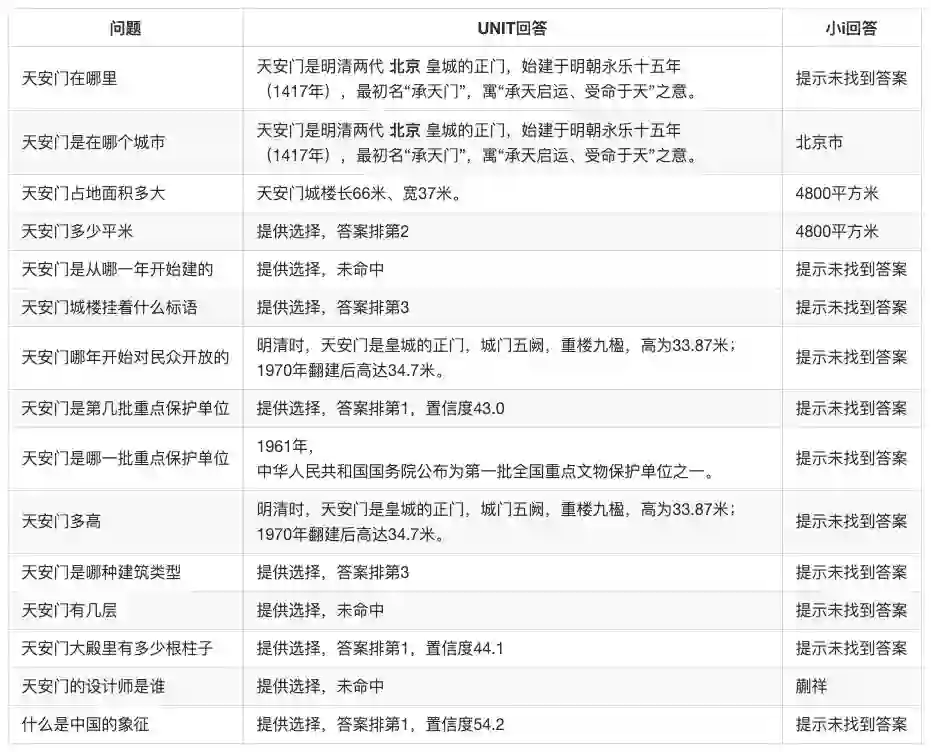
测试结果如下所示。对于可回答问题,小i答对了4道(26.7%),其余均为未回答,没有打错的;UNIT如果不计提供选择的测例答对了5道(33.3%),如果计入提供选择且排第一位的测例则答对了8道(53.3%),答错一道(6.7%),其余为提供选择且排在第一的选项未命中。
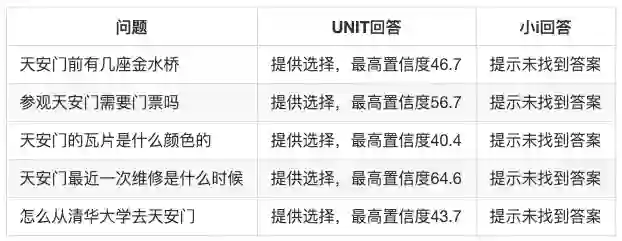
查看UNIT返回的json可以发现它对提供的选项都给出了置信度。虽然我们不知道UNIT提供的置信度具体定义是什么,但如果比较可回答问题和不可回答问题里的置信度可以发现这个值的指示性并不强。要想通过调节置信度的阈值来改善输出准确率似乎是一件比较困难的事情。而且我们还发现如果用户在UNIT的一个session里选择过他提供的选项,那么下次再问这个问题时它就可以命中了。但当重置对话之后又会变为无法命中的情况。
在响应速度方面两家的差距不大。当提问可回答问题的时候反应都很迅速,但当问不可回答问题的时候两家都有2-3秒的等待时间。测试的两家厂商实际的方案不得而知,但从百度的中间结果看,他们提取出了句子的关键词,应该在检索上做了很多工作。也欢迎大家在公众号后台跟我们交流。
后记
今天的评测大概就到这里,相信大家对文档问答都有了一个直观的认识。作为NLP爱好者,确实非常欣喜地看到有厂商已经在实际产品中推广DBQA。虽然目前看问答的效果并不是特别好,但相信随着优化的深入,这种技术可以渐渐代替传统问答的位置。一个可行的方案是在产品上线初期使用DBQA来直接冷启动得到一个问答机器人,上线之后再根据用户实际的提问针对性地建立FAQ知识库。
为了让大家可以快速测试,我们在公众号后台绑定了这个天安门知识问答机器人,欢迎大家关注我们进行体验。UNIT研发环境每天请求次数有限,大家先测先得。
我们也已经在之前提到的GitHub项目[5]里更新了这次评测相关的数据,大家如有兴趣可以自己体验。对话平台评测项目涉及到大量的数据准备工作,在此再次真诚邀请有兴趣的朋友们一起加入到这个项目中来。
参考资料
SQuAD数据集论文: https://arxiv.org/abs/1606.05250
[2]BERT: https://arxiv.org/abs/1810.04805
[3]Retro-Reader on ALBERT: http://arxiv.org/abs/2001.09694
[4]天安门百度百科词条: https://baike.baidu.com/item/%E5%A4%A9%E5%AE%89%E9%97%A8/63708?fr=aladdin
[5]对话平台评测GitHub项目地址: https://github.com/thuwyh/dialog-platform-evaluation
推荐阅读
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。






