常见强化学习方法总结
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:marsggbo
https://zhuanlan.zhihu.com/p/98962807
本文已由原作者授权,不得擅自二次转载
花了一天时间大致了解了强化学习一些经典算法,总结成如下笔记。笔记中出现不少流程图,不是我自己画的都标了出处。
博客链接:
https://www.cnblogs.com/marsggbo/p/12085014.html
版权声明:本文为原创文章,未经允许不得转载!
铺垫
1. Bellman方程
在介绍强化学习算法之前先介绍一个比较重要的概念,就是Bellman方程,该方程表示动作价值函数,即在某一个状态下,计算出每种动作所对应的value(或者说预期的reward)。

上面公式中:
s表示一个具体的状态值,很自然
就是表示当前时刻,下一时刻和下下一时刻,...,的状态
表示在t+1时刻所获得的奖励,其他同理
表示t时刻总的回报奖励,因为当前时刻做的某一个决定,未来不同时刻都会有不同形式的奖励。(或者也可以这么理解:前面
代表的是当前时刻某一个动作所带来的的奖励,而
就表示在当前时刻的一个奖励期望,即综合考虑所能采取的所有动作之后我们所能获得的奖励,我们把
称为value function
 就是表示当前时刻,下一时刻和下下一时刻,...,的状态
就是表示当前时刻,下一时刻和下下一时刻,...,的状态 表示在t+1时刻所获得的奖励,其他同理
表示在t+1时刻所获得的奖励,其他同理 表示t时刻总的回报奖励,因为当前时刻做的某一个决定,未来不同时刻都会有不同形式的奖励。(或者也可以这么理解:前面
表示t时刻总的回报奖励,因为当前时刻做的某一个决定,未来不同时刻都会有不同形式的奖励。(或者也可以这么理解:前面  就表示在当前时刻的一个奖励期望,即综合考虑所能采取的所有动作之后我们所能获得的奖励,我们把
就表示在当前时刻的一个奖励期望,即综合考虑所能采取的所有动作之后我们所能获得的奖励,我们把 上面这个公式就是Bellman方程的基本形态。从公式上看,当前状态的价值和下一步的价值以及当前的反馈Reward有关。它表明价值函数(Value Function)是可以通过迭代来进行计算的!!!
2. 动作价值函数
前面介绍的Bellman方程是价值函数,它直接估计的是某个状态下所有动作的价值期望,但是如果我们能够知道某个状态下每个动作的价值岂不是更好?这样我们可以选择价值最大的那个动作去执行,所以就有了动作价值函数(action-value function),它的表达形式其实是类似的:

上面公式中的 
其实我们最初的目的是找到当前状态下应该执行哪个action,但是如果我们求解出最优的 
其实还有 policy-based(直接计算策略函数) 和 model-based(估计模型,即计算出状态转移函数,进而求解出整个MDP(马尔科夫过程)过程) 方法,下面主要以介绍value-based为主。
最优的动作价值函数为:

有一点要注意的是 
Q-Learning
1. 算法总结

2. 算法流程图
初始化环境状态S
将当前环境状态S输入到Q网络(即策略网络,保存了action和value对应关系的table),然后输出当前状态的动作A
更新Q网络
表示Q真实值,简单理解就是我在S状态下采取了action,从环境中获得了R的奖励,然后对下一时刻的Q值应该也是有影响的,这个影响因子就是γ。另外这次是是一个递归的表达式,所以也可以看出离当前时刻越远,我所采取动作的影响力就越低。
就是常说的TD(temporal difference) error,这个error在后面的DQN中会作为损失函数。
更新当前状态为S'
返回第二步重复执行,直到满足限定条件
 表示Q真实值,简单理解就是我在S状态下采取了action,从环境中获得了R的奖励,然后对下一时刻的Q值应该也是有影响的,这个影响因子就是γ。另外这次是是一个递归的表达式,所以也可以看出离当前时刻越远,我所采取动作的影响力就越低。
表示Q真实值,简单理解就是我在S状态下采取了action,从环境中获得了R的奖励,然后对下一时刻的Q值应该也是有影响的,这个影响因子就是γ。另外这次是是一个递归的表达式,所以也可以看出离当前时刻越远,我所采取动作的影响力就越低。 就是常说的TD(temporal difference) error,这个error在后面的DQN中会作为损失函数。
就是常说的TD(temporal difference) error,这个error在后面的DQN中会作为损失函数。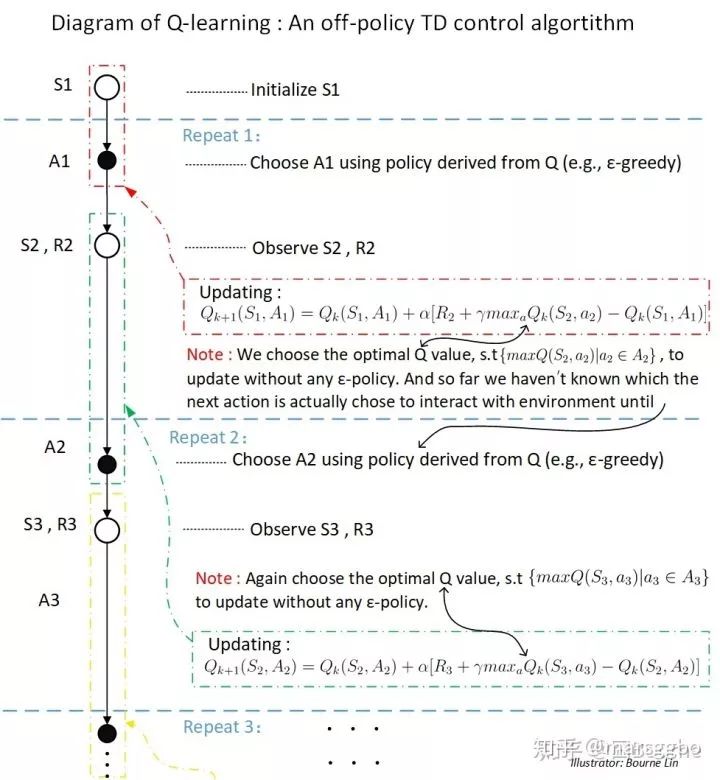
图片来源:[1]
Sarsa
1. 算法总结

2.算法流程图
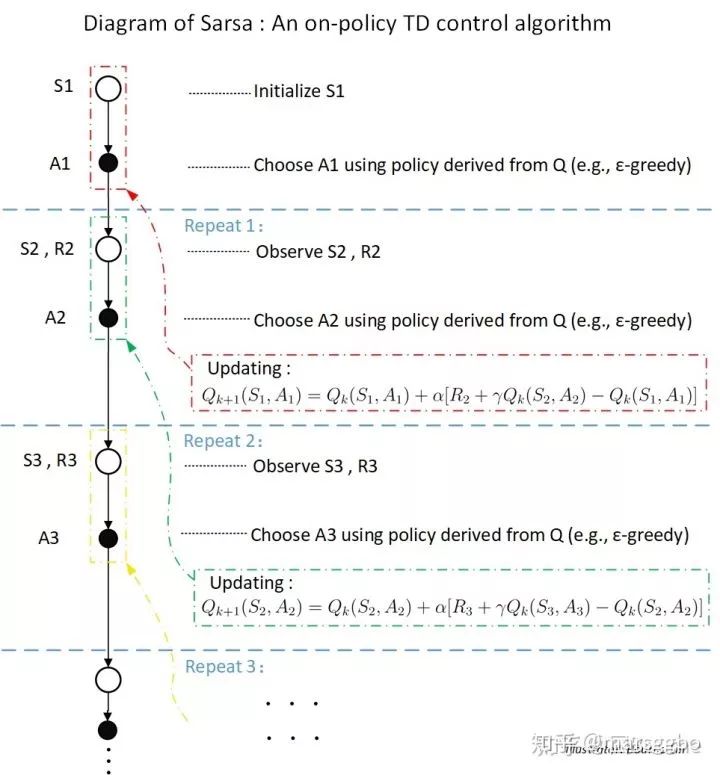
图片来源:[1]
3. 和Q-learning的区别
其实可以看到Q-learning和Sarsa的最大区别就是对Q网络的更新策略,Sarsa使用的是使用下次状态所采取的的动作所对应的Q值来更新Q值,而Q-learning使用下次状态S2的最大Q值用于更新。
感性的理解就是Sarsa会探索更多的可能性,而Q-learning会铁定心地选择最大可能性的选择。因此,Q-learning虽然具有学习到全局最优的能力,但是其收敛慢;而Sarsa虽然学习效果不如Q-learning,但是其收敛快,直观简单。因此,对于不同的问题,我们需要有所斟酌。
DQN(Deep Q-learning Network)
通过计算每一个状态动作的价值,然后选择价值最大的动作执行。
1. 深度学习如何和强化学习结合?
前面介绍的Q-learning和Sarsa的action和state都是在离散空间中,但是有的情境下无法用离散空间表达,而且如果真的用离散空间表达,那么空间会非常巨大,这对计算机来说会很难处理。例如自动驾驶车的state和action,我们不可能用一个表格来记录每个state和对应action的value值,因为几乎有无限种可能。那么如何解决这种问题呢?
我们以自动驾驶为例,仔细想想可以知道,车的状态是高维表示的(例如,当前的位置,车的油耗,路况等等数据来表示当前状态),而动作相对来说可能是低维的(为方便说明,假设速度恒定,最后的动作只有方向盘旋转角度)。
因为我们要做的是针对某一时刻的状态选择最合适的动作,所以我们可以把车状态当做高维输入数据,车的当前时刻的动作当做是低维输出,我们可以对二者构建一个映射关系。

上面等式的含义就是对把状态S作为输入数据,然后经过映射函数 

那么这个映射函数就可以用 "万能" 的神经网络代替,也就是后面要介绍的DQN了。
2. 如何训练DQN?
1) loss函数构造
我们知道,要训练一个神经网络,那么我们就需要构建loss函数,而这个loss函数的构建又需要真实的label和预测的label。
预测的label很好理解,其实就是最终得到的输出向量嘛,那么真实的label是什么呢?其实就是前面Q-learning算法中介绍到的 

2)训练算法
Playing Atari with Deep Reinforcement Learning

具体的算法还涉及到很多细节,例如Experience Replay,也就是经验池的技巧,就是如何存储样本及采样问题。按照脑科学的观点,人的大脑也具有这样的机制,就是在回忆中学习。那么上面的算法看起来那么长,其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降!也就是在DQN中增强学习Q-Learning算法和深度学习的SGD训练是同步进行的!通过Q-Learning获取无限量的训练样本,然后对神经网络进行训练。样本的获取关键是计算y,也就是标签。
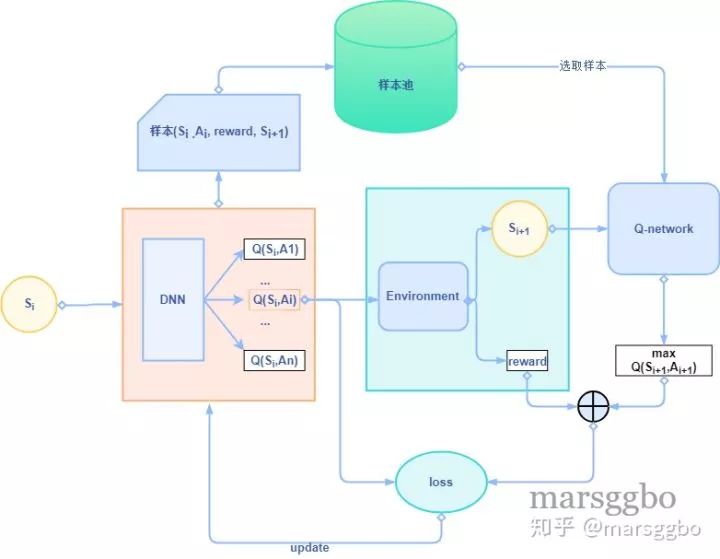
Policy Network
一个神经网络,输入是状态,输出直接就是动作(不是Q值)。
前面三种算法都是基于价值(value)的方法,即输入当前状态,然后计算出每个action的价值,最后输出价值最大的action。而policy network则是根据某种策略直接输出action,即 

1. loss函数构造
和前面算法类似,一个比较直观的损失函数构造方式如下

但是上面的loss函数有个问题是式子中的 

我们换个角度想,如果一个action得到的reward多,我们就应该加大这个action的概率,反之就减少。所以目标函数可以写成如下形式:

其中x表示某个action,p(x)和f(x)分别表示该action的概率和对应的reward。
更一般地说,f(x)应该是对action的评价指标,我们可以用reward,当然也可以用其他的指标,如Q值等等。换句话说Policy Network的核心就是这个评价指标的选取。
我们继续分析上面的目标函数,将目标函数对策略网络的参数 

由上面的求导可知,其实目标函数也可以写成

下图是文献中的截图,总结了多种评价指标,如Q,reward,TD等。

2. 算法流程图
下图中的A表示策略输出的action,P表示该action对应的概率。
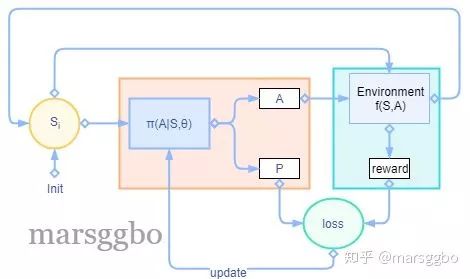
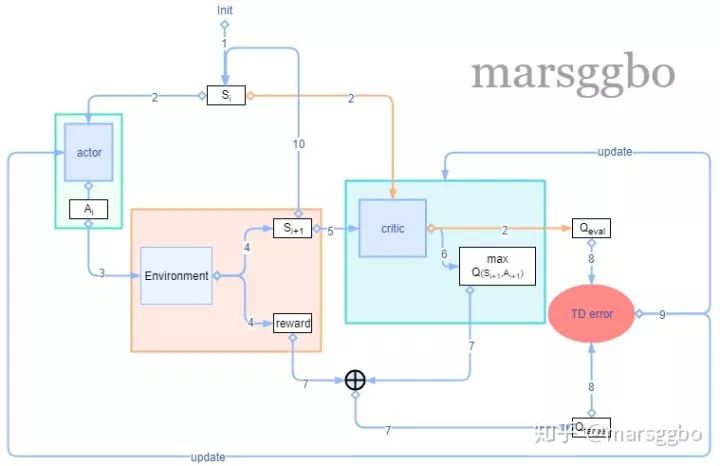
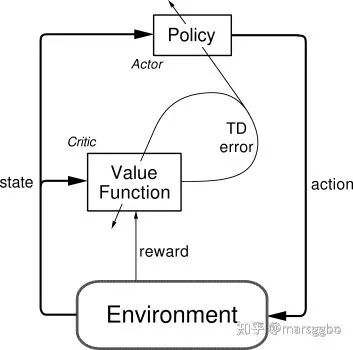
Actor-Critic
上面的policy gradient的loss函数中其实仅仅使用了环境返回的reward,而没有用到Q值。而如果我们希望用到Q值的话就需要用到Actor-critic网络来实现。简单理解,policy network其实就是actor,用来输出动作,而critic则对应评价网络,即评估actor选择的动作的好坏,进而引导actor下次做出更好的选择。
Actor的更新方法和上面policy network可以一样。
critic的评价指标我们可以用Q来表示,那么真实值就用

2. 算法流程图
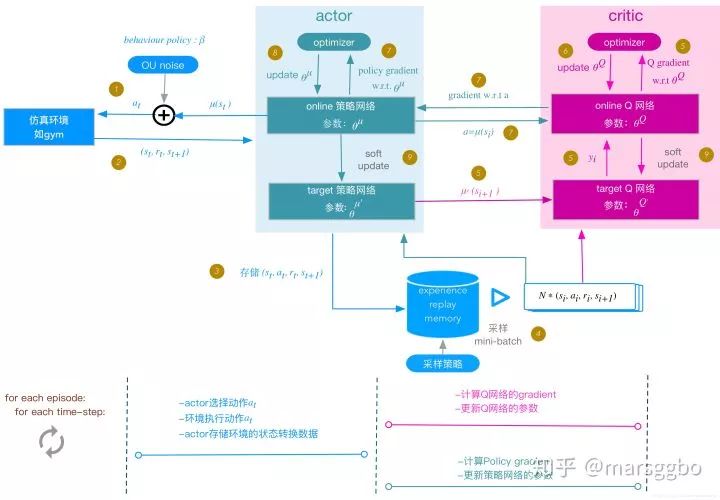
DDPG
强推这篇博文,写的非常好:Deep Reinforcement Learning - 1. DDPG原理和算法。


2. 算法流程图
参考:
1. 强化学习2:Q-learning与Saras?流程图逐步解释
2. DQN 从入门到放弃3 这有一个系列的介绍,建议看完。
3. Deep Reinforcement Learning - 1. DDPG原理和算法
4. Actor Critic (Tensorflow)
重磅!CVer-强化学习交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如强化学习+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!

