训练网络像是买彩票?神经网络剪枝最新进展之彩票假设解读
机器之心原创
作者:朱梓豪
编辑:Haojin Yang
神经网络剪枝技术可以极大的减少网络的参数,并降低存储要求,和提高推理的计算性能。 而且目前这方面最好的方法通常能保持很高的准确性。 因此对通过修剪产生的稀疏架构的研究是一个很重要的方向。 本选题的思路是对以下两篇论文做深度解读,一探当今最好的剪枝方法的究竟。

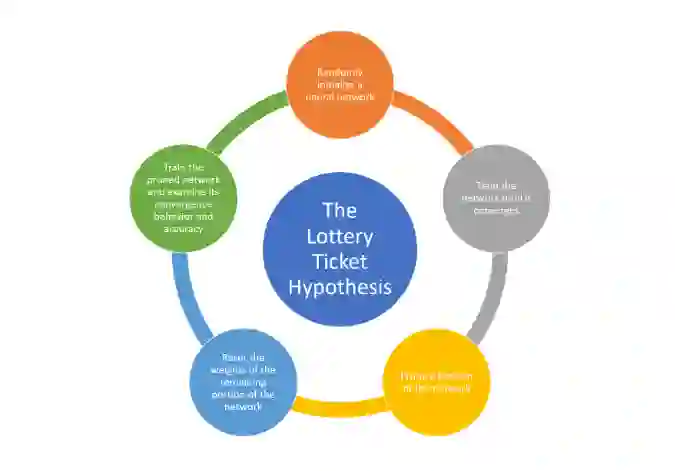
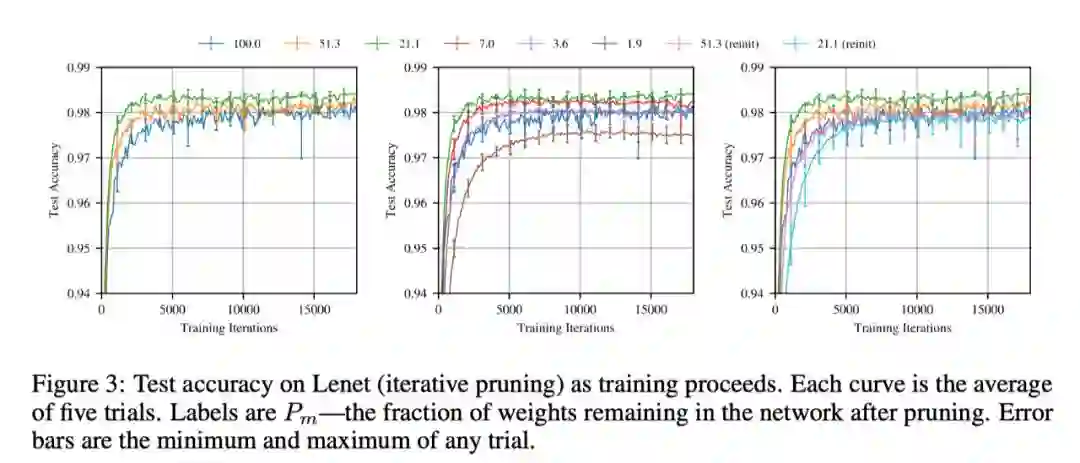
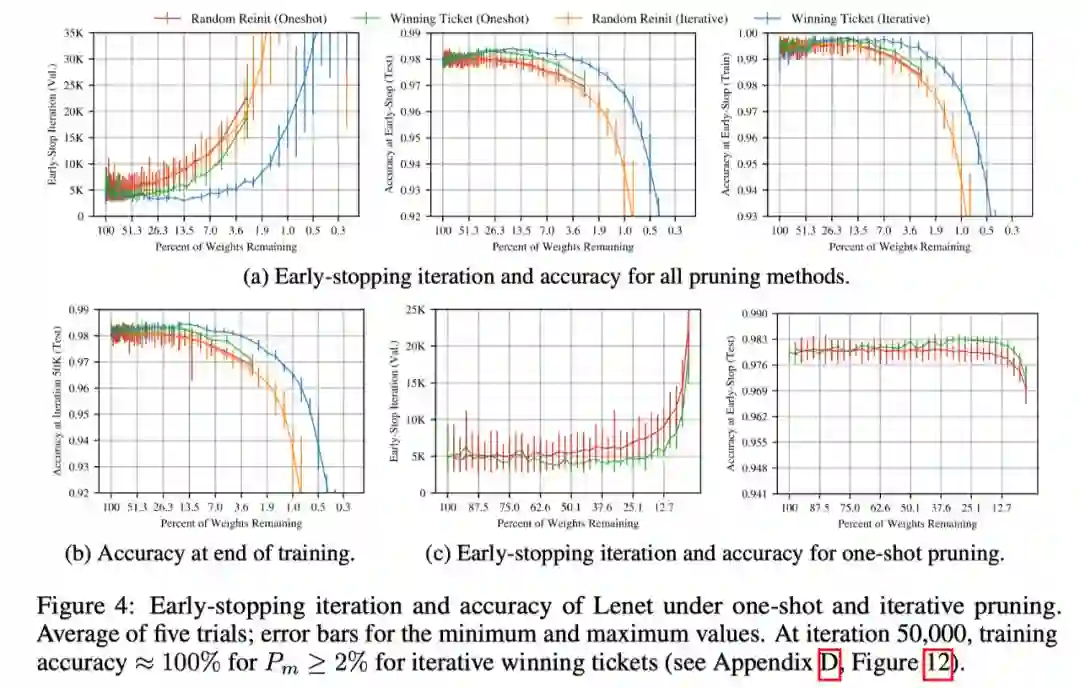

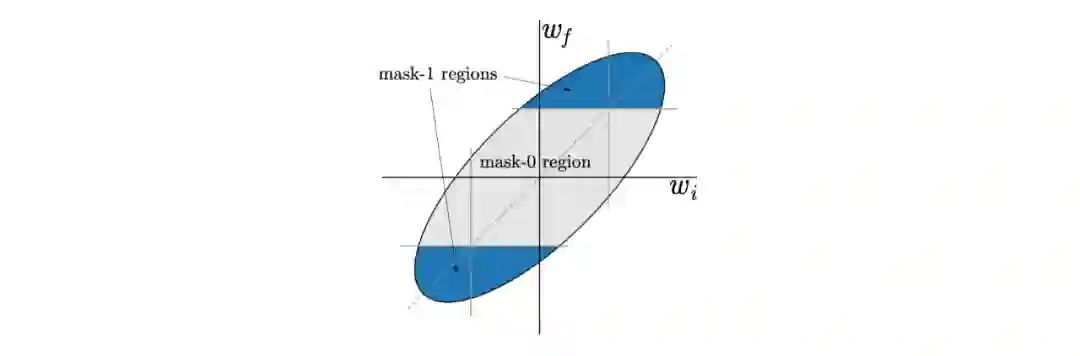
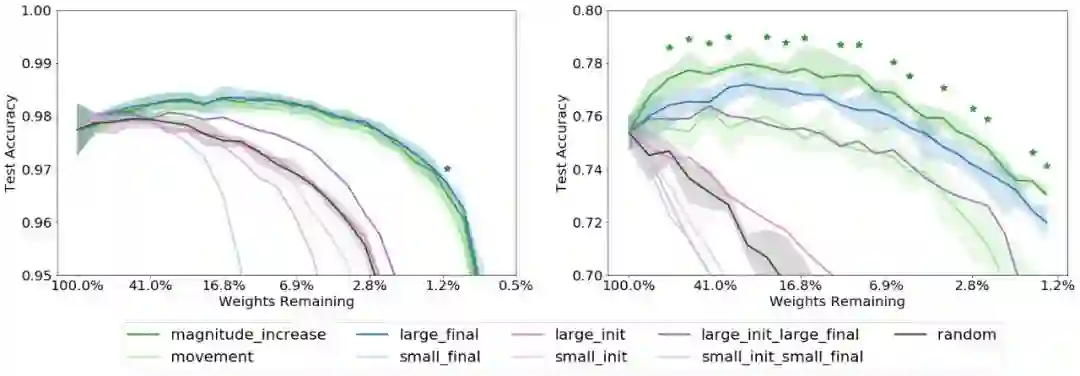
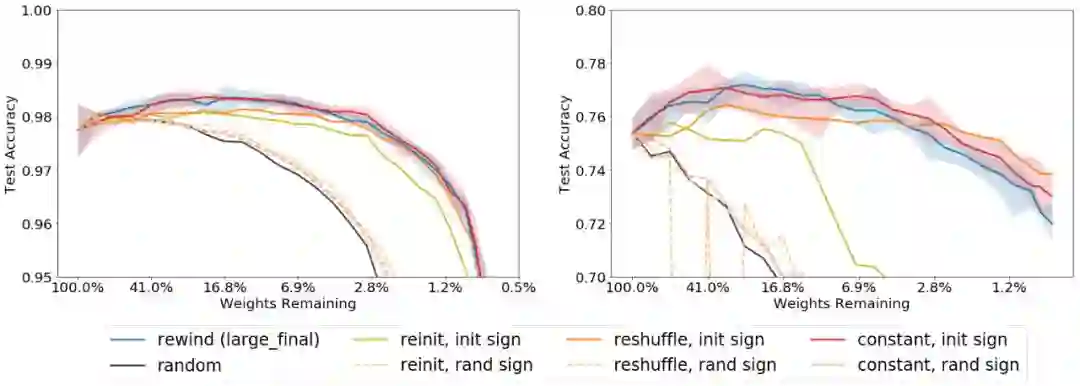
Reinit:基于原始的初始化分布来初始化保留的权重
Reshuffle:基于保留权重的原始分布进行初始化
Constant:将保留的权重设为正或负的常数,即每层原初始值的标准差

登录查看更多
相关内容

专知会员服务
26+阅读 · 2020年3月26日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
4+阅读 · 2018年3月30日


相关VIP内容
专知会员服务
26+阅读 · 2020年3月26日
相关资讯