学界 | François Chollet谈深度学习的局限性和未来(上)
深度神经网络到底学会的是什么?
AI 科技评论按:本文来自 Keras 作者 François Chollet,同时也是根据他撰写的《Deeping Learning with Python》一书第 9 章第 2 节改编的。关于当前深度学习的局限性及其未来的思考,François Chollet 共撰写了两篇文章,这篇是其中第一篇。
作者注:这篇文章的受众是已经有深度学习经验的人(例如读过本书第 1 章至第 8 章的人)。 我们假设读者已经具有一定知识储备。
深度学习最令人惊讶之处就在于它十分简单。十年前,没有人指望由梯度下降方法训练的简单参数模型就可以在机器感知问题上获得惊人的结果。现在,事实证明,你只需要一个有足够多参数的模型,并且在足够大的数据集上使用梯度下降进行训练。正如 Feynman 曾经描述宇宙那样,「它并不复杂,只是很多而已」。
在深度学习中,一切都是一个向量,即一切都是几何空间中的一个点。模型输入(可以是文本,图像等)和目标首先被「矢量化」,即变成一些初始输入矢量空间和目标矢量空间。深度学习模型中的每一层对通过它的数据进行简单的几何变换。同时,模型的层次链形成一个非常复杂的几何变换,分解成一系列简单的几何变换。这种复杂的转换尝试将输入空间一次一个点得映射到目标空间。这种转换是通过层的权重进行参数化的,权重根据模型当前执行的情况进行迭代更新。这种几何变换的一个关键特征是它必须是可微分的,这是为了使我们能够通过梯度下降学习它的参数。直观地说,这意味着从输入到输出的几何变形必须平滑且连续——这是一个重要的约束条件。
这种复杂的几何变换应用到输入数据的整个过程可以用三维的形式进行可视化,将其想象成一个人试图将揉成团的纸球恢复平整:皱巴巴的纸球是模型开始时的输入数据的复本。人对纸球的每个操作相当于一层简单几何转换的操作。完整的抚平(纸球)动作顺序是整个模型的复杂转换。深度学习模型是用于解开高维数据复杂流形的数学机器。
深度学习的神奇之处在于:将语义转化为矢量,转化为几何空间,然后逐渐学习将一个空间映射到另一个空间的复杂几何转换。你需要的只是足够高维数的空间,以便捕捉原始数据中全部的关系范围。
用这个简单策略实现的应用程序空间几乎是无限的。然而,现有的深度学习技术对于更多的应用程序完全无能为力——即使提供了大量的人工注释数据。例如,你可以尝试收集成千上万甚至百万的关于软件产品特征的英文描述的数据集,由产品经理编写,以及由工程师团队开发的相应的源代码来满足这些要求。即使有了这些数据,你也无法训练深入的学习模式去简单地阅读产品说明并生成适当的代码库。这只是其中的一个例子。一般来说,无论你投入多少数据,深度学习模型都无法实现任何需要推理的东西,如编程或科学方法的应用——长期规划和类似算法的数据操作。即使使用深度神经网络学习排序算法也是非常困难的。
这是因为深度学习模型仅仅是将一个向量空间映射到另一个向量空间的简单连续几何变换链。它可以做的全部就是将一个数据流形 X 映射到另一个流形 Y,假设存在从 X到 Y 的可学习连续变换的话,并且可以使用密集的 X:Y 采样作为训练数据。因此,尽管深度学习模型可以被解释为一种程序,反过来说的话,大多数程序不能被表达为深度学习模型——对于大多数任务来说,要么没有相应的实际大小的深度神经网络来解决任务,或者存在这样的神经网络,但它可能无法学习,即相应的几何变换可能太复杂,或者可能没有合适的数据可用来学习它。
通过堆叠更多层并使用更多训练数据来扩展当前的深度学习技术,只能在表面上缓解一些问题。它不能解决深度学习模型在他们可以表示的内容种类非常有限的基本问题,并且大多数被期望可学习的程序不能被表示为数据流形的连续几何变形。
当代人工智能的一个非常现实的风险是人们误解了深度学习模型的作用,并高估了他们的能力。人类思维的一个基本特征是我们的「心智理论」,我们倾向于将意向,信仰和知识投射到我们身边的事物上。在我们的意识中,在岩石上画一个笑脸石头就突然变「快乐」了。应用于深度学习,这意味着当我们能够「基本成功」的训练模型以生成用于描述图片的标题时,我们就会相信该模型能够「理解」图片的内容以及「理解」它所生成的字幕。然后,当训练数据中出现的图像类别轻微偏离时,我们会非常惊讶地发现模型开始生成完全荒谬的标题。

尤其是「对抗性样本」值得强调,这些例子是一个深度学习网络的输入样本,旨在诱骗模型对它们进行错误分类。你已经意识到,可以在输入空间中进行梯度上升以生成最大化某个闭环过滤器激活的输入,这是我们在第 5 章中介绍的过滤器可视化技术的基础,以及第 8 章的 Deep Dream 算法。同样,通过梯度上升,人们可以稍微修改图像以最大化给定类的类别预测。通过拍摄一张熊猫的图片并添加一个「长臂猿」梯度,我们可以得到一个神经网络,将这只熊猫归类为长臂猿。这证明了这些模型的脆弱性,以及它们的输入——输出映射与我们人类自身认知之间的深刻差异。
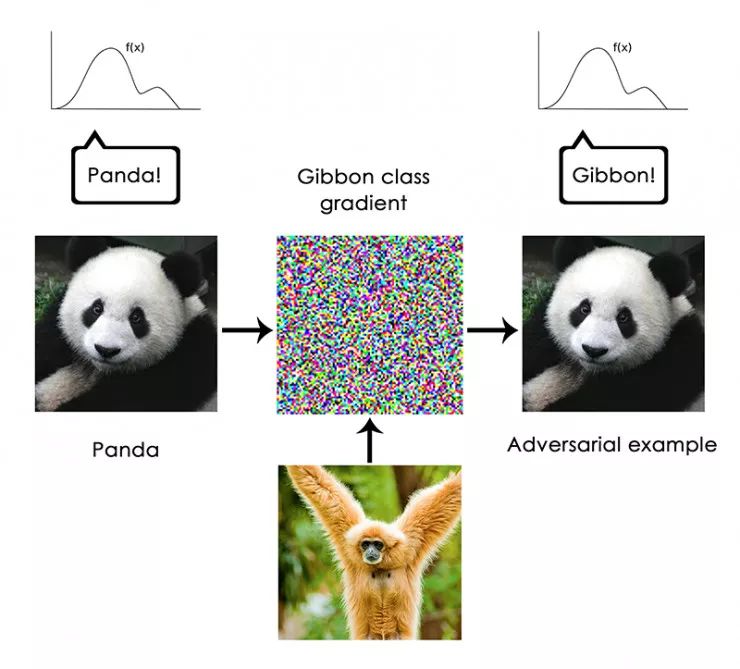
总之,深度学习模型并不理解他们的输入,至少没有人类意识上的理解。我们人类对图像,声音和语言的理解是基于我们作为人类的感觉运动体验——正如地球上的生物所表现的一样。机器学习模型无法获得这些经验,因此无法以与人类一致的视角来「理解」他们的输入。 通过注释大量的训练样例来训练我们的模型,我们让他们学习在特定数据集上,将数据映射到人类概念的几何变换,但这个映射只是我们头脑中原始模型的简单概要,这是我们作为人类实体的体验得来的——它就像镜子里的一个模糊的形象。
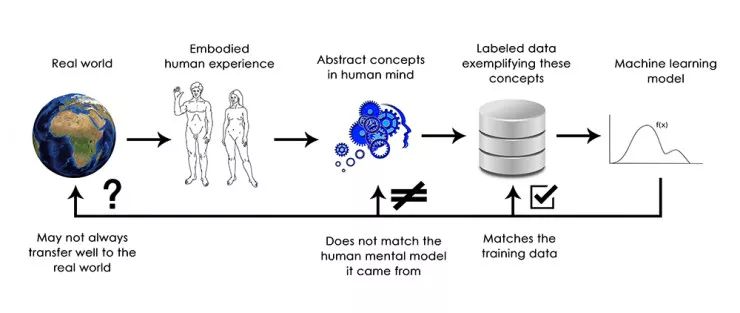
作为一名机器学习实践者,请始终注意这一点,永远不要陷入这样一个陷阱,即相信神经网络理解他们所执行的任务——他们不会的,至少不会以对我们有意义的方式理解。不同于我们想教他们的任务,他们被训练来执行更为狭窄的任务:仅仅将训练集输入逐点映射到训练目标中。向他们展示任何偏离训练数据的东西,他们将给出最荒谬的结果。
深度学习模型中从输入到输出的直接几何变形,与人类思考和学习的方式之间几乎是完全不同的。这不仅仅是人类从自身的经验中学习而不是通过明确的训练实例来学习的问题。除了学习过程不同之外,基本表征的性质也存在根本差异。
人类能做的远远不只是像深度神经网络或昆虫那样把即时刺激映射成即时反应。人们维持着关于目前处境、关于他们自己和其他人的复杂抽象模型,并且可以使用这些模型来预测不同的可能发生的未来并执行长期规划。他们能够将已知的概念合并在一起,来表示他们以前从未经历过的事物,例如描绘穿着牛仔裤的马,或想象如果他们中了彩票就会做什么。这种处理假设的能力,扩展了我们的心智模型空间,使其远远超出我们可以直接体验到的事物空间,总而言之,进行抽象和推理,可以说是人类认知的决定性特征。我称之为「极限泛化」:这是一种在面对未经历的情况时,使用很少的数据甚至根本没有新的数据就能适应新情况的能力。
这与深度网络所做的形成鲜明对比,我称之为「局部泛化」:如果新输入与训练时看到的略有不同,则由深度网络执行的从输入到输出的映射立马失去意义。例如,来思考这样一问题,想要学习使火箭在月球上着陆的合适的发射参数。如果你要使用深层网络来完成这项任务,无论是使用监督学习还是增强学习进行训练,你都需要用数千乃至数百万次的发射试验进行训练,也就是说,你需要将模型置于密集的输入采样点空间,以便学习从输入空间到输出空间的可靠映射。相比之下,人类可以利用他们的抽象能力来提出物理模型——火箭科学——并得出一个确切的解决方案,只需一次或几次试验即可获得月球上的火箭的发射参数。同样,如果你开发了一个控制人体的深度网络,要它能够在城市中安全地驾驶汽车并不被其他汽车撞,那么这个网络将不得不「死亡」数千次在各种场景中,直到它可以推断出汽车和危险并制定适当的回避措施。放到一个新的城市,网络将不得不重新学习已知的大部分知识。另一方面,人类就不必通过死亡来学习安全的行为,这要归功于他们对假设情境的抽象建模的能力。
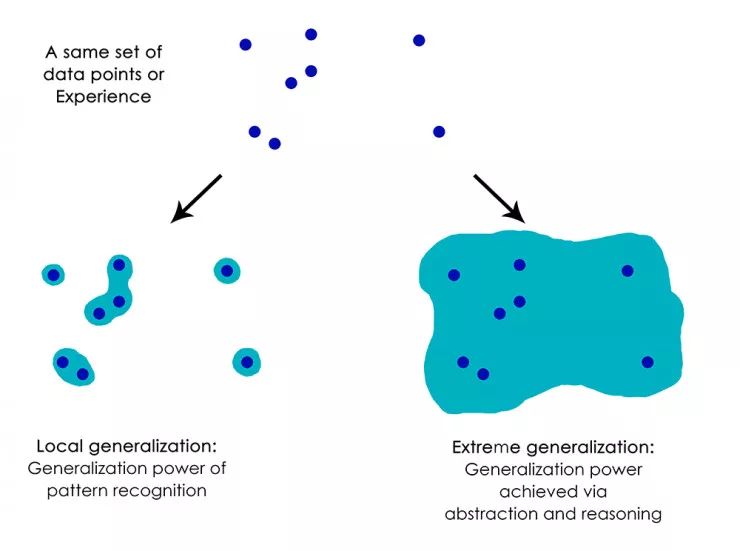
局部泛化:模式识别级别的泛化能力; 极限泛化:由抽象和推理得到的泛化能力
总之,尽管我们在机器感知方面取得了进展,但我们离人类级别的 AI 还很远:我们的模型只能执行局部泛化,要适应一种新场景必须与原始数据联系的很紧密,而人类认知能够极限泛化,快速适应全新的情况,或为长期的未来情况做出规划。
以下是您应该记住的内容:到目前为止,深度学习的唯一真正成功之处就是在给定大量人工注释数据的情况下,使用连续几何变换将空间 X 映射到空间 Y 的能力。做好这件事对于每个行业来说都是一件改变行业游戏规则的事儿,但它离人类级别的 AI 还有很长的路要走。
为了解除这些局限性并开始与人类大脑进行竞争,我们需要从简单的输入到输出映射转向推理和抽象。计算机程序可能是对各种情况和概念进行抽象建模的一个合适的基础。我们之前书中已经说过,机器学习模型可以被定义为「可学习程序」;目前我们能学习的程序属于所有可能程序中非常狭窄和特定子集。但是如果我们能够以模块化和可重用的方式学习任何程序呢?让我们在下一部分中讨论深度学习的未来发展之路。
原文地址:
https://blog.keras.io/the-future-of-deep-learning.html
对了,我们招人了,了解一下?

CCF-GAIR(CCF 全球人工智能与机器人峰会)
将在 6 月底再次席卷鹏城
连续 3 天 11 场 分享盛宴
6.29 - 7.1,我们准时相约!
点击阅读原文了解详情

┏(^0^)┛欢迎分享,明天见!




