从逻辑回归到深度学习,点击率预测技术面面观
在计算广告系统中,一个可以携带广告请求的用户流量到达后台时,系统需要在较短时间(一般要求不超过 100ms)内返回一个或多个排序好的广告列表;在广告系统中,一般最后一步的排序 score=bid*pct^alpha;其中 alpha 参数控制排序倾向,如果alpha<1,则倾向于 pctr,否则倾向于 bid;这里的核心因子 pctr 就是通常所说的点击率(predicted click through rate)。
在推荐系统中,也有类似的需求,当用户请求到达后台的时候,我们需要返回一个排序好的文章列表或者 feeds 列表。早期的推荐系统主要以协同过滤和基于内容的推荐为主,近年来推荐系统的主流形式也变成和广告类似的两步走模式:先召回一个候选队列,然后排序;在排序这一步有很多种不同的策略,比如 pair-wise 的一些分类算法等,但更多还是类似 facebook、youtube 之类的计算一个分数然后排序;这个分数里往往也少不了 item 的 pctr 这个关键因子。
综上,在计算广告、推荐系统等不同业务系统中都对预测物品的点击率有需求,所以这方面的研究也比较多,本文试着梳理一下相关的技术脉络。
我们可以有很多种不同的方式来定义点击问题,本文会列举两种方式。
第一种是将其看做一个分类问题,这种看法比较自然是因为我们原始的日志是曝光和点击;通过简单的归约以后,我们把点击看做正样本、曝光看做负样本的话,基于一段时间的数据样本,我们可以训练一个分类器。形式化来说,假设用户 u、物品 i、上下文 c,曝光和点击类别 e,每个样本可以看成一个<u,i,c|e>的元组;其中 e 的取值只有 0 和 1 两种,这时候对每一个用户、物品、上下文组合<u,i,c>我们需要一个模型来对其分类,是点击还是不点击。
从分类角度出发,我们有很多算法可以用,比如贝叶斯分类器、svm、最大熵等等,我们也可以使用回归算法通过阈值来处理。
另一种看法假设每个<u,i,c>我们可以预测一个 ctr(0-1 之间的值),这时候就变成了一个回归问题,可以使用 lr、fm、神经网络等模型。
在本文的结尾部分可能会有其他的问题定义的方法,大家也可以看到在实际业务中,不同的问题定义方式不仅决定了可以使用的模型范围,甚至决定了本质效果的差异。某个领域机器学习方法的进步,往往不只是模型的进步,有时候是先有问题定义的进步,然后才有模型和算法的进步;而问题定义的进步来源于我门对业务场景的理解,所以做算法的同学一定要多花时间和精力在业务场景的分析和挖掘上。
将用户是否点击一个物品看成回归问题以后,使用最广泛的模型当属逻辑回归 Logistic Regression,[1] 是一篇很不错的关于逻辑回归的综述,这里不打算展开讲逻辑回归的细节,简单做个介绍并说明实际使用中的一些注意点。
首先逻辑回归使用 sigmoid 函数来建模,函数如下:
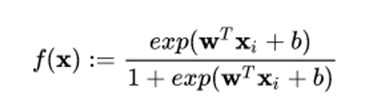
该函数对应的图像如下所示:
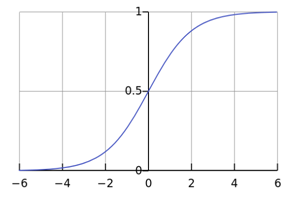
LR 的优点很明确,首先 sigmoid 函数的取值范围是 0-1,刚好可以解释为点击概率,而输入的范围却可以很宽广。所以 LR 是历史最悠久、使用最广泛的点击率、转化率模型。
这里重点说下使用 LR 需要注意的几个事项。首先是训练算法,如果使用离线训练算法,有比较多的选择,比如 sgd、lbfgs、owlq、tron 等等;其中 sgd 是一种非常通用的优化算法,但个人认为理论研究模型可以用 sgd 快速理解,但实际业务中往往不是最佳选择,尤其是存在其他备选项的情况下;原因可以给一个直观的解释,从 sigmoid 函数图像可以看出来,在 x 大于 4 或者小于 -4 以后,函数的取值已经接近于 1 或者 0 了,此时函数的梯度方向接近平行,说明梯度很小,那单个样本对模型参数的贡献也会接近于 0,所以 sgd 的收敛速度越来越慢。这种收敛速度是敏感的,如果你跑一个模型几个小时收敛不了,和另一个算法几分钟就收敛了,那时间的量变就会带来模型性能指标的质变。
除了训练算法之外,LR 模型最需要注意的是特征的呈现方式,从 sigmoid 的解析式可以看到 LR 其实是广义线性模型的一种(GLM),所以 LR 既不能很好地处理连续型特征,也无法对特征进行组合。相反,对于 categorical feature 反而处理得很好。因此,使用 LR 模型的时候往往伴随着大量特征工程方面的工作,包括但不限于连续特征离散化、特征组合等。
对于 continous feature,如年龄、薪水、阅读数、身高等特征,如果要添加到 lr 模型中,则最好先进行离散处理,也叫 one-hot 编码;离散化处理的方式有几种,等值分桶、等频分桶等;或者直接根据对业务的理解分桶。例如对于电商类,可能 20 岁以下的没有什么经济能力,20-40 的经济能力差不多,这时候可以人工划分。
等值分桶是指每个区间同样大小,比如年龄每隔 5 岁为一个桶,则年龄特征变成一个 20 个区间(假设上限是 100 岁)的编码,如 15 岁对应(0、0、1、0、0、0…)。
等频分桶则是需要先对样本做一个分布统计,还是以年龄为例,首先我们要基于统计得到一个年龄分布直方图,通常这类特征都会大致符合正态分布,这时候对于中间阶段就需要多拆分几个桶,而对于两边的部分可以少一点;如 0-16 一个区间,16-18 一个区间,18-20 一个区间,20-30 一个区间。目标是使得每个区间里的人数分布基本持平。
特征离散化的好处我理解是风险均摊,不把鸡蛋放在一个篮子里。举个例子,如果年龄特征对最终的预测结果很重要,则可能在 LR 模型中获得一个比较大的权重 w,这时候如果有一个异常数据,某个人年龄写的是 200 岁,就会一下子将函数值推到接近 1 的区域。这明显不是我们想要的,相反如果通过离散化,年龄特征的权重会分散到各个桶对应的特征里,这时候单个特征的异常就不会造成很大的影响。
假设模型里有年龄、性别、身高三个特征,这时候就会出现特征组合的问题。比如年龄 + 性别可以作为一个新的特征,可能某类物品对于这种组合特征有偏好,如 16 岁以下的小男孩对变形金刚很感兴趣(我实在想不到什么例子)。这种需求 LR 是没有办法自动完成的,只能人工来添加。
类似还有三阶特征、四阶特征等等,在比较长一段时间里,特征工程是算法工程师的主要工作,后来特征多到人力无法进行有效组合的时候,又想出来了其他一些办法,比如后面要介绍的 GBDT+LR 就是 facebook 提出的一种应对特征组合的处理方式。
在这里也单开一个小节来介绍特征设计的内容,这块没有特别有效的现成方法,也没有相关的书籍总结,但又很重要。如果特征设计不好,很可能模型根本出不了效果,能给大家的建议就是多读读论文。从和自己业务需求相似的论文中去看别人设计特征的方式,然后结合自己的业务看看能否借鉴。
从我自己阅读的一些 paper 里,我总结了两个所谓的“套路”。
一个是 获取外部关联信息,比如对于新广告,我们要预测点击率的话,因为没有历史数据,我们可以从层次结构来获取一些信息,比如这个广告的 publisher 下面其他广告的点击情况,这个广告的落地页的 url 层次关系,比如 xx.com/food/x.html 这类 url,我们是否可以对 food 做一个聚合,看看这类落地页对应的广告的数据情况,以此作为我们新广告的特征。还有一种技巧,将广告相关的文本,或者广告购买的关键词列表,丢到搜索引擎上去跑一下,取返回的 top10 页面聚合以后做一个分类(类别体系可以提前设计),然后根据关键词列表在不同类别上分布形成的信息熵作为一个 feature,放到 LR 里。在 [2] 中使用这种方法得到了一定的提升。
另一个套路是 使用数据不同方面的信息,这个策略更加隐晦。举个例子,我们可以根据用户的资讯阅读历史计算一个兴趣画像,但是这个画像我们可以分成几个画像,比如拿一周的历史算一个,一个月的历史算一个,然后通过实践 decay 算一个历史全量的。这样场中短期分开的画像可以作为独立的特征放到模型中去。另一个例子是 cf 论文中一个很有意思的做法,在 Netflix 的数据集里,user-item 矩阵嵌入了一个隐藏信息是 user- 打分 item 的对应关系,所以我们可以从 user-rating 矩阵里提取一个二元取值的 user-item 关联矩阵,如果 u 对 i 打分了,则这个矩阵对应 ui 的位置为 1,否则为 0。把这个矩阵作为一个 implicit feedback 加入到 cf 里,会有进一步的效果提升,这就是数据信息的不同 facet。
特征设计还有很多其他的技巧,这里就不一一列举了,还是需要去搜寻和自己业务场景相关的论文,阅读、总结,后面我会再写一篇协同过滤的综述,那里会介绍另外一些技巧。
这一小节是后补的,主要介绍几种常用的评价指标以及他们各自的优缺点,主要取材于 [21]。这里选取 AUC、RIG、MSE 三个来重点说下,其他的指标有需要的请参考原文。
AUC 是 ROC 曲线下的面积,是一个 [0,1] 之间的值。他的优点是用一个值概括出模型的整体 performance,不依赖于阈值的选取。因此 AUC 使用很广泛,既可以用来衡量不同模型,也可以用来调参。比如
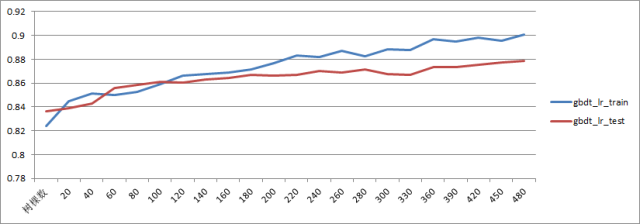
这是用 AUC 用来调超参的一个例子,横坐标是 GBDT 的树的棵数,纵坐标是对应模型收敛后在 test 集和 train 集上的 AUC 值,从图中可以看到在 120 棵树附近 GBDT 就开始出现过拟合情况了,不过两个集合的 AUC 都还在持续上升。除此之外,AUC 还可以作为一个在线监测的指标,用来时刻监测在线模型的表现。
AUC 指标的不足之处有两点:一是只反映了模型的整体性能,看不出在不同点击率区间上的误差情况;二是只反映了排序能力,没有反映预测精度。 简单说,如果对一个模型的点击率统一乘以 2,AUC 不会变化,但显然模型预测的值和真实值之间的 offset 扩大了。
Netflix 比赛用的 RMSE 指标可以衡量预测的精度,与之类似的指标有 MSE、MAE,以 MSE 为例,计算公式如下
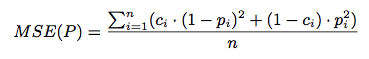
公式里的 ci 和 pi 分别对应真实的 laber 和预测的 ctr 值;前者用 0、1 表示曝光和点击;后者用 [0,1] 之间的实值即可。MSE 指标不仅可以用来调参,也可以在参数选定以后用来分区间看模型的拟合程度;熟悉 Netflix 比赛相关 paper 的同学可能知道缺点在哪,就是区分度的问题,很有可能 MSE 很小的提升,对线上的效果,比如 F 值会有较大的变化,因此在业务优化的时候还可以参考其他更有区分度的指标。
如果我们要对比不同的算法的模型的精度怎么办呢?除了 MSE 有没有其他选择?这里提供一个 RIG:
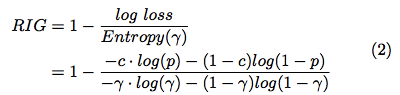
这张图直接取自 [21],表达式有点问题,我先留给大家来发现吧,正确的表达式在本文另一篇参考文献里有,先留个悬念:)
这里要强调的一点是 RIG 指标不仅和模型的质量有关,还和数据集的分布情况有关;因此千万注意不可以使用 RIG 来对比不同数据集上生成的模型,但可以用来对比相同数据集上不同模型的质量差异。这一点尤为重要。
[3] 是微软内部竞赛推出的一个算法,也被后续很多算法作为对比的 baseline。
这个算法的细节可以直接去看原文,这里只对优劣做一个简单介绍。该算法的基本思想是参数 w 是一个先验分布为正态分布的分布,参数为 u、ó;在贝叶斯框架下,每一个样本都是在修正对应的分布参数 u、ó;对应的更新公式为
转自:大数据杂谈




