KDD’20 | 解决会话(session)推荐中图神经网络的信息损失问题
Handling Information Loss of Graph Neural Networks for Session-based Recommendation, KDD 2020
引言
会话(session)推荐是指预测用户在一段相对较短的时间(会话)会接触哪些商品。因为用户的会话记录是按时间排列的,所以过去很多方法是基于序列推荐方法来进行预测。随着图神经网络的兴起,最近有一些工作是将会话记录构建成图来建模商品之间的跳转关系,本文主要是针对过去的方法进行优化,去解决之前使用图神经网络时的存在的信息损失问题。
背景
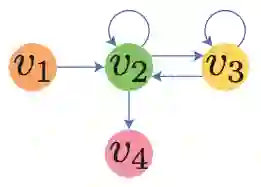
图1、传统会话图
第二,目前的GNN没有办法解决长序列问题。由于存在过度平滑(over-smoothing)的问题,GNN一般无法考虑超过三阶的邻居,所以在GNN中我们无法考虑相距较远的商品。而RNN可以考虑到序列整体,并且可以加入长短时记忆(LSTM)来记忆最早出现在会话里的商品,因此GNN在这方面存在劣势。
模型

图2、边顺序保留图
针对图(b)表示的保留边顺序的图,本文提出了EOPA层。它的主要想法是通过GNN的一个分支GRU模型来对每个点的邻居按标好的顺序进行聚合。具体公式如下:

在此公式中,xi表示目标节点,xj表示xi的邻居,di代表xi序号排最后的邻居,hdi是用GRU聚合之后的邻居表达,||表示将两个向量相连。通过这种方法我们就可以在GNN的框架下将邻居按顺序聚合,从而表示会话中商品的序列关系。
SGAT层
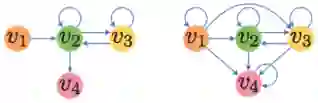
图3、直连图
对于直连图,本文提出了SGAT层来学习点的表达。基于自注意力(self-attention)的方法,我们可以学出每条边的注意力权重α,然后在聚合时我们用得到的节点表达乘上注意力权重就可以算出目标节点的表达。
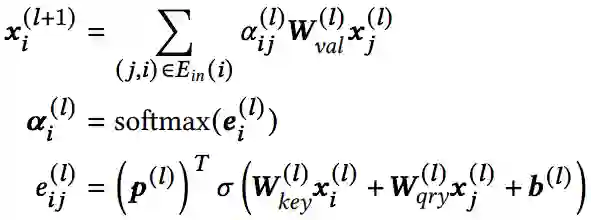
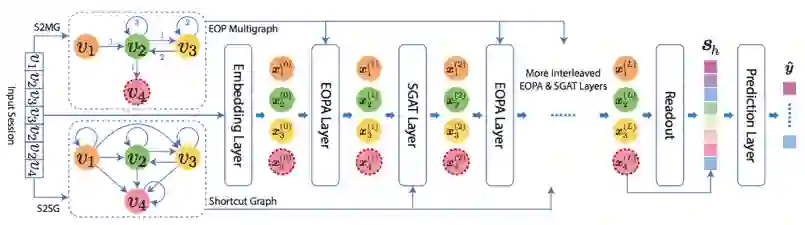
模型的整体结构如图4所示。我们将原本的会话序列转化成边顺序保留图和直连图。通过将EOPA和SGAT层穿插着堆叠起来,我们可以构建出一个多层的神经网络模型。
在用GNN得到每个节点的表达后,我们再加入一个readout函数来得到这个会话的整体表达。本文的readout函数首先是将会话中最后一个商品与所有其他商品算self-attention然后加权求和,具体如下公式:
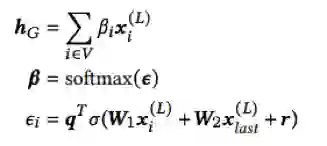
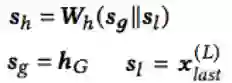
在预测层中,本文用了传统的softmax函数来预测用户未来可能喜欢的商品。
实验
本文用的数据集是三个会话推荐中常用的数据集。具体数据的统计如表1所示。
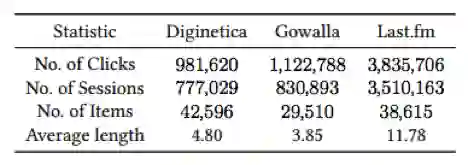
表1、数据集
本文的实验结果和8个过去已发表的会话推荐的模型进行对比,如表2所示,整体而言相较过去的模型有所提升,在LastFM上较为显著。
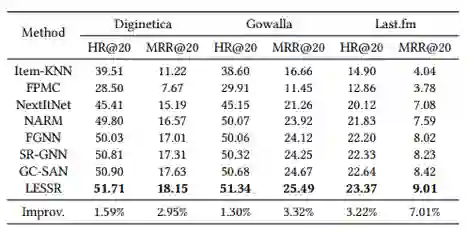
表2、实验结果
译者总结
本文描述了一些在用图神经网络进行会话推荐时存在的问题,并给出了一些解决方法,作者从信息损失和长序列这两个问题出发,分别设计了两个模块来解决这个问题。但其中我个人认为直连图的方法存在问题,他们将两个实际上并不直接相连的连接起来,这样相当于额外引入了不存在的信息,这种方法会对模型产生误导,引来不必要的误差。整体而言,本文依然有着不错的切入角度,并且本文的写作也能让读者很容易理解他们为什么要这么设计模型。
参考文献:
[1] Session-based Recommendation with Recurrent Neural Networks, ICLR 2016
[2] Neural Attentive Session-based Recommendation, CIKM 2017
[3] Self-Attentive Sequential Recommendation, ICDM 2018
[4] Session-based Recommendation with Graph Neural Networks, AAAI 2018
往期文章:



