傅盛认知学:抑制你成长的其实是你的自卑

“你对认知的清晰定义到底是什么?
“认知有多深才算知?”
“为啥技能差别可量化,认知差别是本质的?
“如何去提升自己的认知?”
思考认知,本质是在思考“一种思维”。认知思维所具有的超越性,不可想象。正所谓,擒贼先擒王。这个王,某种维度看,就是认知。
那么,到底怎么定义认知?技能相对认知,为什么可量化?
我认为,技能就是回字的四种写法,是一种知识的熟练掌握。再直白点,技能就是背了唐诗三百首,背了圆周率后50位或背一个微积分方程,然后来回做题。
技能的熟练掌握,当然重要。甚或,掌握一种获得熟练技能的方法,也可能是一种认知。但,技能最终仍是一种线性映射。如同程序里的函数,输入A,就产生B。一旦学到了,就变成简单的模式化。
本质上,整个中国教育就是技能教育。发一张答题卡,谁填得好,谁就优秀。它是一种封闭条件下的技能组合。
而认知是什么呢?认知是基于一个综合情况而做出的一个精准判断。什么叫综合情况?就是复杂情况下,做了超出常人的不一样的判断。从这个维度看,技能本质是一个封闭式问题,而认知更多是一个开放式问题。
这里,我画了一幅图来描述认知产生的整个过程。
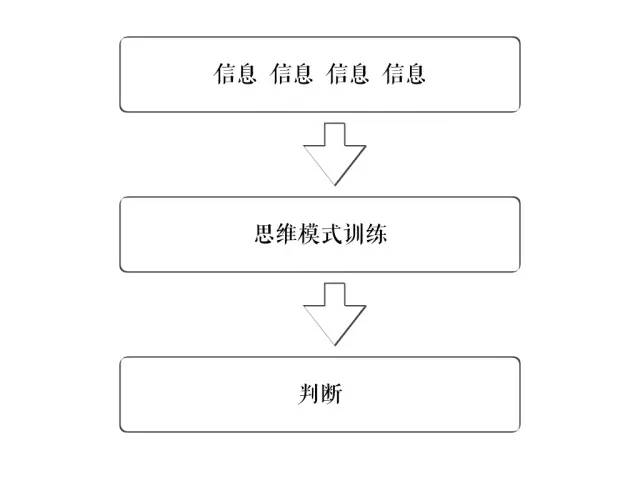
认知产生原理跟神经网络的模型训练很像。简言之,通过海量信息不断输入,再进行自我思维模式的训练,最后输出一个判断。由此,我总结了认知的三个要素,分别为输入、训练和判断。
01
认知第一要素:信息输入与挖掘
有一句话很流行:道理听了无数,依然无法过好这一生。为什么?不同人面对信息,有不同的态度、方法和能力。所有这些因素,决定了认知的起跑线。同样刷朋友圈,你看花边新闻,人家看某一篇论文,认知能一样吗?
有的人,凭着一股喜欢,叶公好龙。比如我面试一些技术人员,让他们讲讲对AlphaGO的原理,十有八九,答不上来。有人说,AlphaGO就是运算能力更强,能算出更多步数。
听懂这个答案是错的人,说明不是叶公好龙。关于AlphaGO技术解析的文章遍网都是,不需数学知识就能看懂。看不懂,不是智商问题,而在于是否愿意深度挖掘。
信息挖掘的核心,就是广度和深度兼得。我们常常遇到的广度问题是——对很多新的现象和机会视而不见;而遇到的深度问题则是——对当下处境和形势看不透。
然而,即使认为自己很有深度,也可能会出现盲区。这里的盲区主要有两类:第一类盲区是“看不起-自傲”;第二类盲区是“接受不了-自卑”。
先说第一类盲区,看不起-自傲。99%的人都可能有这样的心态,一开始就抗拒信息的输入。
有一天,我跟一位同事讨论游戏,告诉他要学习王者荣耀。他反驳道,我不是王者荣耀。我说你玩了吗?一个做游戏的人,不玩王者荣耀,不要跟我谈了。当然,或许你比它牛,但你都不了解它,不愿去接触它,何谈超越?
看不起,是一种非常要命的心理。

我说过,现象即规律。看到一个现象,如果没有惶恐感,就会错过一堆现象。一个现象背后必然有大规律,而这个大规律背后,肯定还有别的现象根本不在你的视野。
我们有时候看到现象,就跟当年乾隆看到西方人送的钟表一样。认为这都是奇淫技巧,全然不知钟表背后隐藏的现代物理学规律。当一个现象发生时,我们应该首先扑上去,了解它,吃透它,再想想背后的规律,而不是简单予以屏蔽。
表面看,你错过了一些看似不重要的现象,本质上有可能错过了一个重要规律或对一个机会的认知。
第二类信息挖掘的盲区叫“接受不了-自卑”。有时候,一些同事工作没啥进展,当我跟他们聊时,本来就有情绪,聊完情绪更大了。甚至来一句:你不了解我。我想说的是,你试图了解过我为什么这么说吗?我站在CEO的位置,看到的对一个岗位的要求,肯定和你看到的不一样。
如果换一个角度看,实际是一个人进入到了自我保护和自卑的状态。于是非常难以接受外面的信息,尤其负面信息。
我们都是成年人,要有职业心理。否则真的沦为一群巨婴。更重要的是,当你将情绪转化为一种意见,由此会下定论——领导对自己极度不满。这时候,你就丧失了一个信息深度挖掘的机会。
这一点,我们必须警醒。
我曾经跟腾讯一位高管交流,他说,牛人其实都是在自信和自卑之间来回跳跃。如果我们能平衡二者,站在上帝视角思考问题,检视自己的心态,是不是更有利于获取认知呢?
人的成长,就是一种自我抗衡。如果你能在信息输入与挖掘的过程中,把自傲与自卑对抗掉,获取信息的维度一定会好很多。
反之,我们怎样才能克服以上两类盲区,真正从海量信息中挖掘出真知灼见呢?我认为需要两种能力:第一要能趴在地上面对自己;第二要能学会倾听。
人不能心比天高,命比纸薄。心态高一定会导致信息获取遭遇巨大问题。尤其在激烈的商业竞争中,我们不仅需要趴在地上看对手,更要趴在地上看世界。因为只有趴在地上时,你才能发现对手真的很强大。
大多数时候,我们的行为往往是:获取信息时,站在云端看别人,每个人都很渺小,一览众山小;真正做起事情来,又趴在地上,觉得这事太难,困难像高山一样无法撼动。
其实应该反过来。
当我们学习时,应该趴在地上,每个人都挺高大,像小学生一样对别人保持崇敬和倾听;而遇到困难时,应该站得更高一点,虽然困难很多,但心态要乐观。
第二,倾听是一种能力。我经常观察一些人,喜欢打断别人的人,往往容易在学习状态上出问题。
有时候,几个人一起聊天,有的人突然打断,急于提问或强调自己,别人的叙述就断了。所谓信息挖掘,先要让人把话说完,你才有机会挖掘。而不是听了只言片语,也不是听了一点立刻欣喜若狂。与人沟通时,无需极力表现自我。
有一句万能理由是:只要对了,我就听。其实也是一种经验主义。经验主义的问题在于,拿过去的经验作信息筛选,往往漏掉可能改变自己的很多新信息。你要假定,自己可能错,多去听一听,才有机会纠正。
信息挖掘,是构建认知体系中非常重要的一点。我们必须承认,那些对行业变化非常敏锐的人,对关键点的信息挖掘能力,一定比常人技高一筹。
02
认知第二要素:思维模式训练
如上图所示,有了足够大的信息输入后,才能不断训练自己脑海里的模型,从而形成自己独有的思维模式。
什么叫思维模式?我看过一些认知神经科学的文章。人脑的信号是通过神经元之间的连接来发送的。尽管,基因大致决定了神经元的连接形态。不过,在大脑发育的过程中,后天经历也在不断塑造神经元的连接。
比如,人们进行学习与认知活动时,大脑中的电信号就会激活神经元。当人们接受和处理外界信息后,神经元之间的连接就会发生可塑性的改变。而这些改变,代表了我们思考的过程,或可理解为一种思维训练的模式。
随着接受外部信息更多,你会学习更多,神经元之间的连接就会出现“创造性破坏”,不仅产生功能性改变,大脑认知结构也会重塑。而这些变化,正是学习的结果。本质上,思维模式就是如此被训练出来的。它一定不是天生长成。
此外,思维模式的训练中,还有一个非常重要的点叫自我挑战。即不断站在自己的对立面自我互搏。这个过程跟AlphaGO算法模型训练中的左右互搏原理一样。
然而现实生活中,绝大部分人只会作自我增强。一旦有了想法,每天都很激动,觉得要改变世界了。自我信任大过于自我质疑。
所谓思维模式训练,就是不断进行“自己问自己”的思考训练。两个自我,反复博弈,无休无止,直至精进。
03
认知第三要素:自我博弈与输出判断
做判断,必须基于深度思考。而深度思考的核心标志,就是自我博弈。即一个人要能不断自我反思。吊诡的是,尽管大家都在反思,但反思也是有层次深浅的。我把反思分了三个层次:
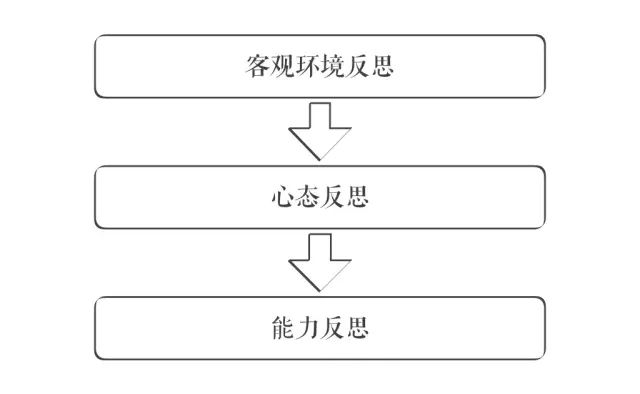
第一层反思,较为普遍,叫客观环境反思。反思时,只回顾客观困难。想当然假设,如果自己掌握更好资源,就能重新解决难题。这叫第一层反思。
第二层反思,进了一层,叫心态反思。认为自己不够投入。言下之意,只要投入,就能做好。
第三层反思,更难了,叫能力反思。认为自己可能不具备这样的能力。我曾经就反思过自己是否具备做CEO的能力。有一段时间,甚至很崩溃。心想:我这么一个在乎别人感受的人,做CEO,太痛苦了。
有时候,我们真的需要跳出来看。张颖有一句话叫——脱光了看自己。你要把自己的内在和外在,与事情本身结合起来。直面痛苦和真相,才能让反思真正产生效用。这个过程就是不断的自我博弈。
人的内心,本质只会自我加强。想了一个点,会顺着这个点继续想,于是越想越觉得自己好。尤其当自傲和自卑心态作祟时,就更难挑战自我了。
所以,我们要把思维模式的训练,由刻意为之,逐渐变成一种习惯。面对困境时,多向内看,反求诸己;取得一些成绩时,多向外看,总结外在机会,警惕自傲。如此,认知能力才可精进。
而精进本身,就是认知现实能力的不断升级。即通过大量信息的不断输入,反复的思维模式训练,不断自我博弈与挑战,克服自傲与自卑心态,使其认知结构在广度与深度上充分扩展,形成一套更高维度的、完整的认知框架,最终做出正确的判断和聪明的决策。
认知其实就是一场自我革命。这是我最后想说的。
来源:盛盛GO(ID:fstalk) 作者:傅盛

想加入钱皓频道,一起提升认知吗?
招募互联网分析师,请戳这里
简历投递:1000808@qq.com
或加微信:angelalu2016
更多原创精品,点击关键词获取




