AI在中国,还没到抢切蛋糕的时候
李根 发自 凹非寺
量子位 报道 | 公众号 QbitAI

他们中的不少名字,之前并不广为人知。
刘全全、王宇杰、王昌宝、帅靖文、张顺丰、蒋尚达、余革年、闵可锐、宋洪伟、李晓普、张晓伟、王峰、董倩倩……
不过从今往后很多年,AI变革发展历程中,他们的名字可能会一次次出现在大众视野中。
这一次,他们是首届AI Challenger挑战赛5个赛道的冠军项目成员。
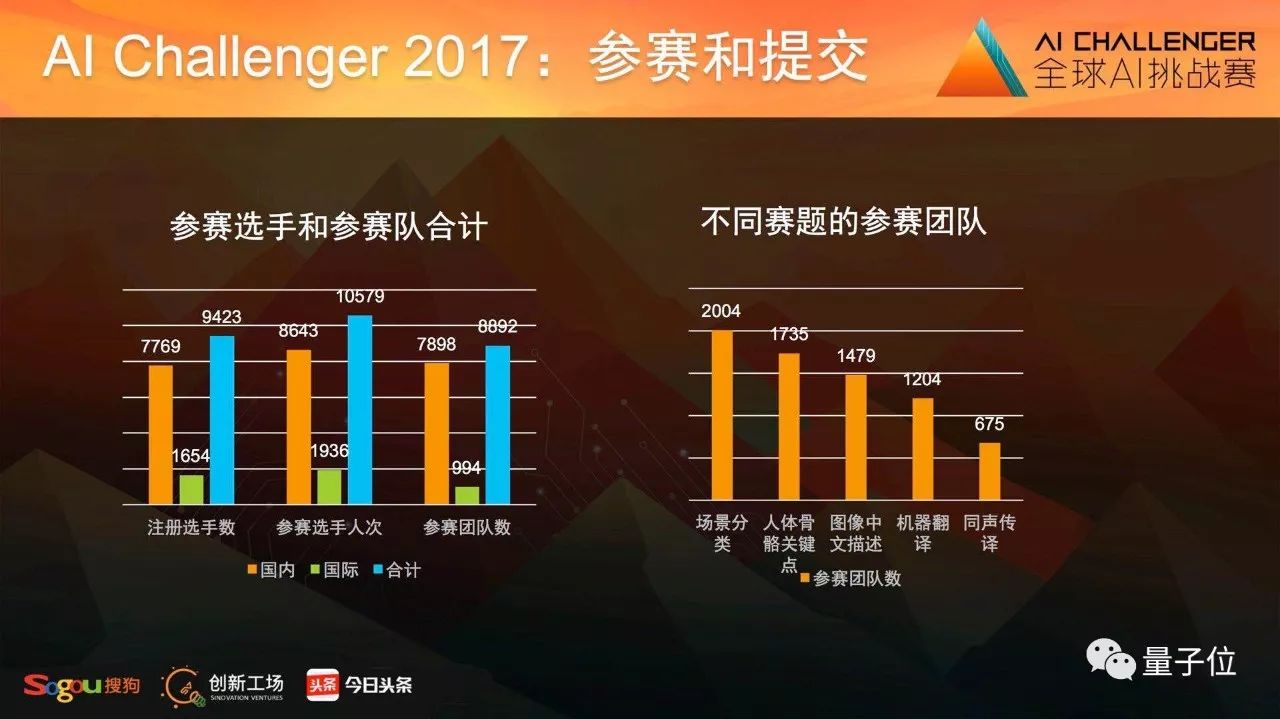
他们中间有的人还在高校读研,有的人低调就职于某家公司。AI Challenger提供了一次技术竞技展示,在全球8892支队伍中,他们脱颖而出。
这是AI Challenger最初的意义之一,但并非全部价值,因为仅仅为发掘13个模式的名字,就要专门投入人力精力耗时130天、三家公司总投入千万,还要开放数据,并不“划算”。
中国数据集
从无到有,数据集完全源自中国。

之前,量子位报道过,此次图像描述和人体骨骼关键点的数据集,由旷视Face++的标注团队标注,由创新工场AI工程院90后校验,在半年多的时间中,他们终日面对的是那些图片中的框框线线,以至于回到现实中也会有特殊的“眼力”。
图像和人体骨骼关键点的花费,各自均有数百万元。

还有搜狗负责的英中翻译数据集,初始数据源自搜狗之前的积累,属于公司竞争力的一部分,此次不仅开放,还耗时6个月,投入60人,对1200万口语句对进行清洗、标注和检查,值得注意的是,每一个参与者都是手持英语专八证书,拥有多年翻译经验的人。
英中翻译数据集打造,同样耗费了上百万元。
当然,付出自然也得到了认可。
中科院自动化所研究员王亮,是本次图像方面的专家评委,他认为此次AI Challenger的数据集在规模上已经超过了国际通行的MS COCO和ImageNet,对于中国科研工作者而言是福音。
清华大学计算机系的副教授刘洋,常年带领学生进行机器翻译领域的探索,他介绍说,全球还没有一个英中口语翻译数据集,与直接拿公开新闻、文件资料作为数据源不同,口语数据集的困难从搜集开始,中间经历标注、校对、检验,在交付之前每一步都要经历挑战。
之前,清华和搜狗通过共建联合实验室的方式进行翻译突破,让清华师生最为看重的便是来自搜狗的大规模数据集,在强调大数据运用的深度学习模型中,数据量带来了更好的成绩,但作为科研探索,如果能够让更多人使用同一数据集进行比拼,才能更好发现模型算法之优劣。
在这次AI Challenger挑战赛中,刘洋透露,有选手用相同的方法超越了他们实验室中的最好成绩,他觉得这样的“启发”如果成为常态化,未来肯定能促进中国AI在产学研方面的进一步提升。
或许这位清华大学副教授,也侧面揭示了一个易被忽略的真相:中国产学研都在谈AI,但AI的核心资源却并不平等,从数据到算法,还没有一个公开的平台,让科研工作者接触企业拥有的大数据,让企业看到科研实验室中的最新突破。
AI Challenger,正在承当这样的角色。

数据集、竞赛和开放分享平台
在AI Challenger首次对外宣布时,外界对此有不同的比喻,有人说这是中国的ImageNet、MS COCO,也有人将其比作ImageNet+Kaggle。
总之,认为这是一次中国版数据集+竞赛的新尝试,核心是为更好挖掘人才。

于是在首届AI Challenger颁奖典礼现场,发起者李开复决定把话说明白。
他不否认AI Challenger背后的人才挖掘意义,但比这更迫切的是数据开放分享。
李开复说,AI是未来发展最重要的方向,现在业界也都意识到了数据的重要性,但中国产学研领域的研究员、从业者和潜在创业者,并不能很方便地接触到精确的、大量的数据,也就无法通过这些“燃料”来推动自己的“火箭发射”。
李开复说,目前精确地、大量的数据,一方面可能存在高校和企业的联合实验室中,更具吸引力的部分则为BAT所有,而有识之士一旦离开这两大地方,就还需要把大量时间精力花费在数据集构建中。
他希望通过AI Challenger构建起一个彼此分享、透明,一起进步的平台,“有数据的出数据,有资源的出资源,需要成长的能够在这个平台上成长”。最后,这批成长于AI Challenger的人才,能够成为中国乃至全球的AI引领者。
让中国AI人才成为全球AI引领者,也不光是李开复一人心愿。

搜狗公司CEO王小川在现场说,以前科研的情况是大家都以美国为中心,我们贡献智力,最后他们选择题目,而且成果我们还不能优先享有。
但中国人才对此还毫无办法,因为过去美国经济、企业都比中国领先,技术制高点自然在人家手中。
而最近几年情况开始发生改变,中国经济、企业和技术都在进步,是时候让中国研究的题目,吸引中国乃至全球的人才参与共振。
“能够把舞台的中心从美国逐步向中国做迁移,这是一个苗头,是很重要的起点。”王小川说。
中国AI国际化
实际上,在专家评审的午餐会上,国际化也是围绕AI Challenger讨论最多的话题。
即便AI Challenger从诞生伊始就是面向全球的比赛,但这一次参赛的情况来看,还是以华人居多,全球性的“共振”尚未开始。
专业评审们也给出了一些建议。
微软亚洲研究院的资深研究员梅涛建议,当前的数据集规模已经超过了MS COCO,未来是不是可以把这样的数据集推向国际主会,使得各个国家的人都可以通过这样的数据集来比拼,或许也能够激发出更多原创性的想法和技术。
旷视Face++首席科学家孙剑则表示,可以在标注和衡量方法上,都与国际目前通行的数据集协商达成统一标准,这样能更好促进国际化。

AI Challenger的执委王咏刚也表示,国际化肯定是未来AI Challenger的核心方向之一,而且数据集也会持续对外分享,在符合使用权规定的前提下,科研工作者都可以使用AI Challenger推进自己的研究。
不过,对于中国AI发展来说,国际化是一方面,蛋糕不够大是另一绕不过去的现实。
AI Challenger颁奖典礼后的媒体采访环节,有媒体更关注AI Challenger可以带来的“人才挖掘”好处,比如创新工场可以投资其中的人才项目,搜狗和今日头条可以更好发现有潜力的人才。
作为发起者,李开复回应说:现在的问题不是如何切蛋糕,而是蛋糕还不够大,让我们号召大家一起参与把蛋糕做大,无论是对科研、企业还是整个国家,都有好处。
李开复明确表示,欢迎更多的企业和组织参与到AI Challenger中来,贡献数据,激励创新,鼓励人才,让中国和社会真正能在AI浪潮中受益。
实际上,目前在国际AI顶会上,中国企业已逐渐成为最主要的赞助商。
所以,也是时候将目光聚焦于国内人才培养了。
至少AI Challenger算是一个很好的开始,更多陌生名字开始脱颖而出,更多人才因之受益,更多科研项目也能在数据加持下取得更大的突破。
— 完 —
活动报名
加入社群
量子位AI社群12群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态





