何恺明团队计算机视觉最新进展:从特征金字塔网络、Mask R-CNN到学习分割一切
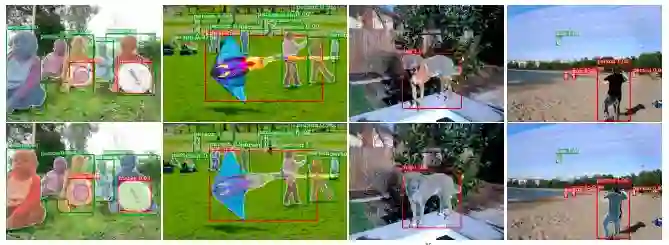
图来自Learning to Segment Everything
【2018 新智元 AI 技术峰会倒计时 10 天】
2018 年 3 月 29 日,北京举办的 2018 年中国 AI 开年盛典——新智元产业 · 跃迁 AI 技术峰会,邀请了微软技术院士、微软语音、自然语言和机器翻译团队负责人黄学东博士和微软全球杰出工程师张祺博士,解析机器翻译最新突破和人机交互未来趋势!想近距离交流互动?点击文末阅读原文,马上参会!
抢票链接:http://www.huodongxing.com/event/8426451122400
新智元编译
来源:skrish13.github.io
作者:krish 编译:肖琴
【新智元导读】这篇文章介绍了FAIR何恺明、Tsung-Yi Lin等人的团队在计算机视觉领域最新的一些创新,包括特征金字塔网络、RetinaNet、Mask R-CNN以及用于实例分割的弱半监督方法。

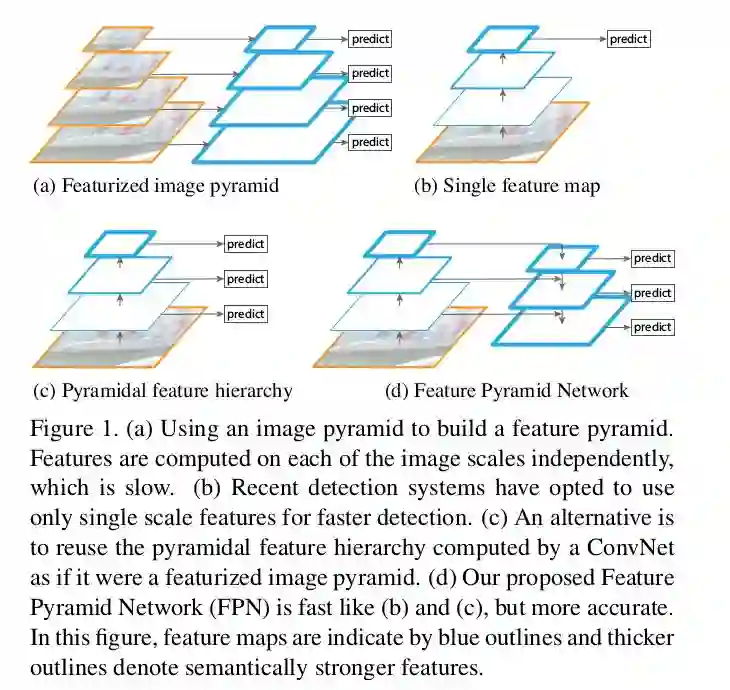
让我们以现在著名的Feature Pyramid Networks(FPN)[1]开始,这是在CVPR 2017发表的论文,作者Tsung-Yi Lin,何恺明等人。FPN的论文真的很棒。构建一个每个人都可以在各种任务、子主题和应用领域中建立的基准模型并不容易。在详细讨论之前,我们需要了解的一点是:FPN是ResNet或DenseNet等通用特征提取网络的附加组件。你可以从你喜欢的DL库中得到想要的预训练FPN模型,然后像其他预训练模型一样使用它们。
物体是以不同的的scale和size出现的。数据集无法捕获所有这些数据。因此,可以使用图像金字塔(图像的多种缩小比例),以使CNN更易处理。但这太慢了。所以人们只使用一个单个scale的预测,也可以从中间层进行预测。这跟前一种方法有点像,但这是在特征空间上进行的。例如,在几个ResNet块之后放一个Deconv,并获得分割输出(分类也类似,可以是1x1 Conv和GlobalPool)。
FPN的作者找到了一种改进上述方法的聪明方法。不是仅仅具有横向连接,而是将自上而下的pathway也放在上面。这非常合理!他们使用一个简单的MergeLayer(mode ='addition')来组合两者。这个想法的一个关键点是,较低层(比如初始的conv层)的特征语义信息比较少,不足以用来进行分类。但是更深层的特征可以用于理解。在这里,你还可以利用所有自上而下的pathway FMaps(特征地图)来理解它,就像最深的层一样。这是由于横向连接和自上而下的连接相结合形成的。
FPN论文的一些细节
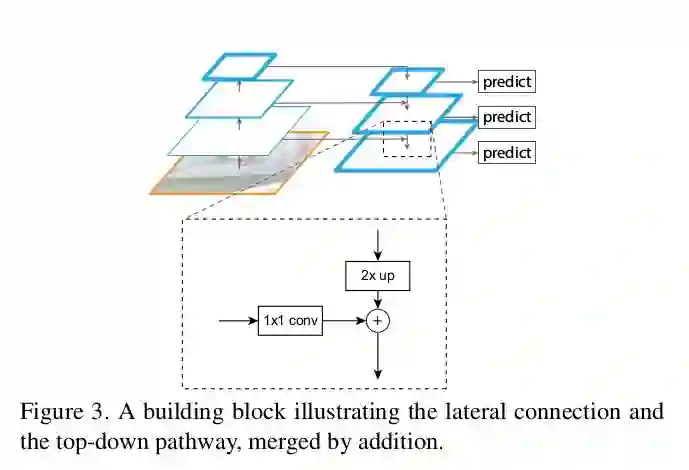
金字塔(pyramid):即属于一个stage的所有大小相同的输出图。最后一层的输出是金字塔的参考FMaps。例如:ResNet - 第2,3,4,5个block的输出。根据内存的可用性和特定任务,你可以根据需要改变金字塔。
横向连接(Lateral connection):1x1 Conv和Top-Down pathway是2x的上采样。这个想法来自于顶部特征,同时向下产生粗糙的特征,而横向连接则增加了从下往上的路径中更精细的细节。如下图所示。
这篇论文只描述了一个简单的demo。它只是展现了这个想法在简单的设计选择中表现非常好,你可以做得更大、更复杂。
正如我前面所说,这是一个基础网络,可以在任何任务上使用,包括目标检测,分割,姿态估计,人脸检测等等。论文发布后几个月的时间,已经得到100多个引用!论文的标题是FPNs for Object Detection,因此作者继续将FPN用作RPN(Region Proposal Network)和Faster-RCNN网络的baseline。更多关键细节在论文中有更全面的解释,这里只列出一部分。
实验的一些要点:
用于RPN的FPN:用FPN替换单一尺度的FMap。它们对每个级都有一个单一尺度的anchor(不需要多级作为其FPN)。它们还表明,金字塔的所有层级都有相似的语义层级。
Faster RCNN:他们以类似于图像金字塔输出的方式观察金字塔。因此,使用下面这个公式将RoI分配到特定level。
其中w,h分别表示宽度和高度。k是分配RoI的level。
是w,h=224,224时映射的level。
他们对每个模块的工作进行消融实验,以证实论文开头的宣称。
他们还基于DeepMask和SharpMask这两篇论文展示了如何将FPN用于segmentation proposal生成。
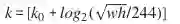
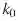
请阅读原论文了解实现细节和实验设置等。
代码
• 官方Caffe2 - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
• Caffe - https://github.com/unsky/FPN
• PyTorch - https://github.com/kuangliu/pytorch-fpn (just the network)
• MXNet - https://github.com/unsky/FPN-mxnet
• Tensorflow - https://github.com/yangxue0827/FPN_Tensorflow
RetinaNet跟上面的FPN来自同一团队,第一作者也都是Tsung-Yi Lin。这篇论文发表于ICCV 2017,并且获得当年的最佳学生论文。
这篇论文有两个关键想法——称为焦点损失(Focal Loss,FL)的损失函数和称为RetinaNet的single stage物体检测网络。该网络在COCO物体检测任务上表现非常出色,同时也击败了前面的FPN benchmark。
Focal Loss
Focal Loss是很聪明的想法,而且很简单!如果你已经熟悉加权损失,这个与加权损失基本相同,但具有更聪明的权重,将更多的注意力集中在对困难的样本进行分类。公式如下:
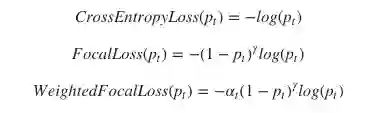
其中γ是一个可以改变的超参数。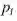
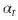
RetinaNet
FAIR发布这个single stage的检测网络,很是令人惊讶。直到现在,在 single stage 的目标检测中,占据主导地位的仍是YOLOv2和SSD。但正如作者指出的那样,这两个网络都没有能够非常接近SOTA方法。RetinaNet做到了这一点,同时它是one stage而且快速的。作者认为,最好的结果是由于新的损失,而不是由于一个简单的网络(它后端是一个FPN)。 one stage的检测器将在背景与positive classes之间存在很多不平衡(而非positive classes内部的不平衡)。他们认为,加权损失函数只是针对平衡,但FL则针对简单/困难的样本,同时也表明两者可以结合起来。
代码
• Official Caffe2 - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
• PyTorch - https://github.com/kuangliu/pytorch-retinanet
• Keras - https://github.com/fizyr/keras-retinanet
• MXNet - https://github.com/unsky/RetinaNet
再次,Mask R-CNN也来自FAIR何恺明团队,论文发表在ICCV 2017。Mask R-CNN用于目标实例分割。简单来说,目标实例分割基本上就是对象检测,但不是使用边界框,它的任务是给出对象的精确分割图!
TL;DR : 如果你已经了解Faster R-CNN,那么Mask R-CNN就很好理解了,就是为分割增加另一个head(branch)。所以它有3个branch,分别用于分类、bounding box regression和分割。
下面的解释假设你已经对Faster R-CNN有一定了解:
Mask R-CNN与Faster R-CNN相似,Faster R-CNN是two-stage的,其中第一个stage是RPN。
添加一个预测分割mask的并行分支——这是一个FCN。
Loss是
,
和
的和。
ROIlign Layer而不是ROIPool。这就不会像ROIPool那样将(x / spatial_scale)分数舍入为整数,相反,它执行双线性插值来找出那些浮点值处的像素。
例如:想象一下,ROI的高度和宽度分别为54,167。空间尺度基本上是图像大学/ FMap大学(H / h),在这种情况下它也被称为步幅(stride)。通常224/14 = 16(H = 224,h = 14)。
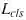 ,
,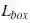 和
和 的
的◦ ROIPool: 54/16, 167/16 = 3,10
◦ ROIAlign: 54/16, 167/16 = 3.375, 10.4375
◦ 现在我们可以使用双线性插值来进行上采样。
◦ 根据ROIAlign输出形状(例如7x7),类似的逻辑将相应的区域分成适当的bins。
◦ 感兴趣的话可以看看Chainer的ROIPooling的python实现,并尝试自己实现ROIAlign
◦ ROIAlign代码可以在不同的库中使用,请查看下面提供的代码库。
它的主干是ResNet-FPN
代码
• 官方 Caffe2 - https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
• Keras - https://github.com/matterport/Mask_RCNN/
• PyTorch - https://github.com/soeaver/Pytorch_Mask_RCNN/
• MXNet - https://github.com/TuSimple/mx-maskrcnn
文如其名,这篇论文是关于分割的。更具体的说,是关于实例分割的。计算机视觉中用于分割的标准数据集非常小,对现实世界的问题不足以有效。即便到了2018年,创建于2015年的COCO数据集仍然是最流行、最丰富的数据集,尽管它只有80个物体类别。
相比之下,对象识别和检测的数据集(例如OpenImages [8])具有用于分类任务的6000个类别和用于检测的545个类别。话虽如此,斯坦福大学还有另一个名为Visual Genome的数据集,其中包含3000个物体类别!那么,为什么不使用这个数据集呢?因为每个类别中的图像数量太少,因此DNN在这个数据集上并不会真正起作用,所以即使它更丰富,人们也不会使用这个数据集。而且,这个数据集没有任何分割注释,只有3000个类别的对象检测的边界框(bounding boxes)标签可用。
让我们回到Learning to Segment Everything这篇论文。实际上,边界框(bounding box)和分割注释(segmentation annotation)对于域来说并没有太大的区别,仅仅是后者比前者更精确。因此,因为Visual Genome数据集有3000个类,为什么不利用这个数据集来做实例分割呢?FAIR何恺明团队正是这样做的。这可以被称为弱监督(或弱半监督?)学习,也就是说你没法完全监督你想要实现的任务。它还可以与半监督相关联,因为它们都使用COCO + Visual Genome数据集。这篇论文是迄今为止最酷的。
它是建立在Mask-RCNN之上的
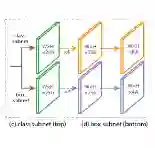
同时在有mask标注和无mask标注的输入上训练
在mask和bbox mask之间添加一个weight transfer函数
当无mask标注的输入通过时,wseg 预测将于马萨卡 features相乘的权重;当有mask标注的输入通过时,不使用这个函数,代而使用一个简单的MLP。
如下图所示。A是COCO数据集,B是VG。注意不同输入的两个不同路径。
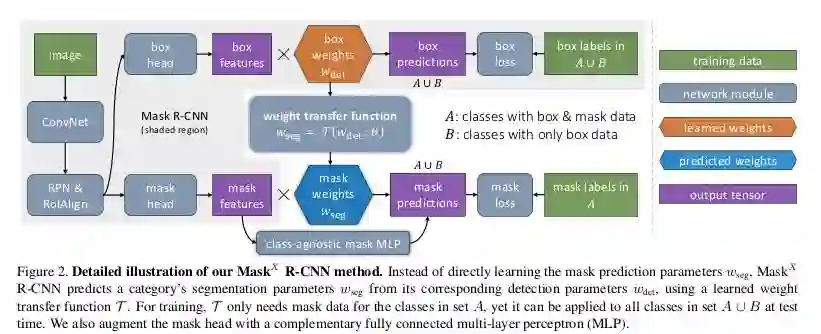
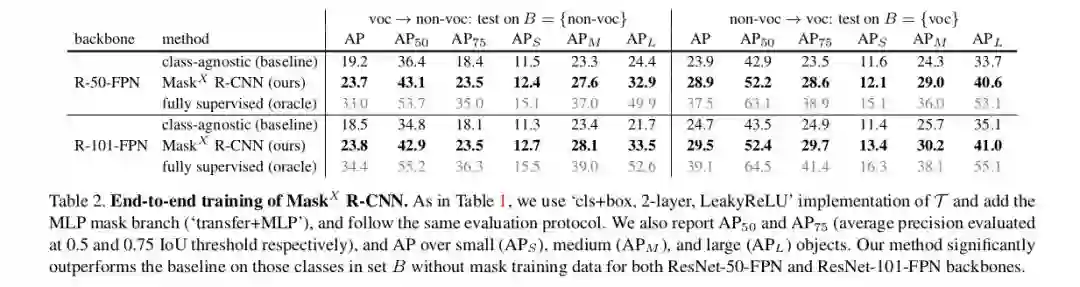
由于没有注释可用,作者无法在VG数据集上显示精确度,因此他们把这个想法应用到可以证明结果的数据集上。PASCAL-VOC有20个类别,而且这些类别在COCO中都很常见。因此,他们使用VOC分类标签进行训练,并且只使用来自COCO的bbox标签对这20个类别进行训练。结果显示在COCO数据集中20个类的实例分割任务上。反之亦然,因为这两个数据集都有ground-truth。结果如下表所示:
References:
[1] Lin, Tsung-Yi, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan and Serge J. Belongie. “Feature Pyramid Networks for Object Detection.” *2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)* (2017): 936-944.
[2] Lin, Tsung-Yi, Priya Goyal, Ross B. Girshick, Kaiming He and Piotr Dollár. “Focal Loss for Dense Object Detection.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2999-3007.
[3] He, Kaiming, Georgia Gkioxari, Piotr Dollár and Ross B. Girshick. “Mask R-CNN.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2980-2988.
[4] Hu, Ronghang, Piotr Dollár, Kaiming He, Trevor Darrell and Ross B. Girshick. “Learning to Segment Every Thing.” *CoRR*abs/1711.10370 (2017): n. pag.
[5] Ren, Shaoqing, Kaiming He, Ross B. Girshick and Jian Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” *IEEE Transactions on Pattern Analysis and Machine Intelligence* 39 (2015): 1137-1149.
[6] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017): 1800-1807.
[7] Lin, Tsung-Yi, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár and C. Lawrence Zitnick. “Microsoft COCO: Common Objects in Context.” ECCV (2014).
[8] Krasin, Ivan and Duerig, Tom and Alldrin, Neil and Ferrari, Vittorio et al. OpenImages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages
[9] Krishna, Ranjay, Congcong Li, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, David A. Shamma, Michael S. Bernstein and Li Fei-Fei. “Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations.” International Journal of Computer Vision 123 (2016): 32-73.
原文:https://skrish13.github.io/articles/2018-03/fair-cv-saga
【2018 新智元 AI 技术峰会倒计时 10 天】
点击阅读原文查看嘉宾与日程
峰会门票火热抢购,抢票链接:
http://www.huodongxing.com/event/8426451122400
【扫一扫或点击阅读原文抢购大会门票】