CVPR 2017 李飞飞总结 8 年 ImageNet 历史,宣布挑战赛最终归于 Kaggle
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
机器之心报道
参与:机器之心编辑部
2017 年 7 月 18 日,ImageNet 最后一届挑战赛成绩已经公布,多个国内院校和企业在各个比赛项目上取得了非常不错的成绩。据官网信息,在 CVPR 2017 期间也会有一场 Workshop 以纪念 ImageNet 挑战赛。当地时间 7 月 26 日,李飞飞与 Jia Deng 在 ImageNet Workshop 上做主题演讲,对 8 年的 ImageNet 挑战赛历史进行了总结,并宣布之后的 ImageNet 挑战赛将转由 Kaggle 主办。最后,感谢李飞飞教授提供的 PPT,以及对本文内容的确认。

在 CVPR 2017 的 ImageNet Workshop 中,演讲者介绍了挑战赛的结果,回顾了物体识别领域的顶尖成果。同时,也有挑战赛获胜者介绍研究成果在产业中的部署等。在李飞飞与 Deng Jia 的演讲中,两位演讲者对 8 年的 ImageNet 挑战赛进行了回顾与总结,以下是基于 PPT 对演讲内容的介绍:
始于 CVPR 2009

ImageNet 始于 2009 年,当时李飞飞、Jia Deng 等研究员在 CVPR 2009 上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,之后就是 7 届 ImageNet 挑战赛的开始(2010 年开始)。
8 年来,ImageNet 这篇论文对业内有极大的影响。在 Google Scholar 上,该论文有 4386 的引用量。另一篇论文《ImageNet Large Scale Visual Recognition Challenge》(2015),也有 2847 的引用量,这篇论文描述了 ImageNet 数据集基准的创造、物体识别领域的研究进展。

众多 ImageNet 挑战赛的参与者发展成了创业公司,其中包括机器之心很早就关注到的图像识别创业公司 Clarifai(机器之心 AI00 获奖者)、被谷歌收购的 DNNresearch。

ImageNet 的历史
在演讲中,演讲者首先介绍了 2009 年之前的图像数据集历史:从 1998 年 CMU 的 Vasc Faces 到 2008 年的 TinyImage 数据集。

也介绍了当时机器学习中的多种问题:复杂性、泛化、过拟合等。
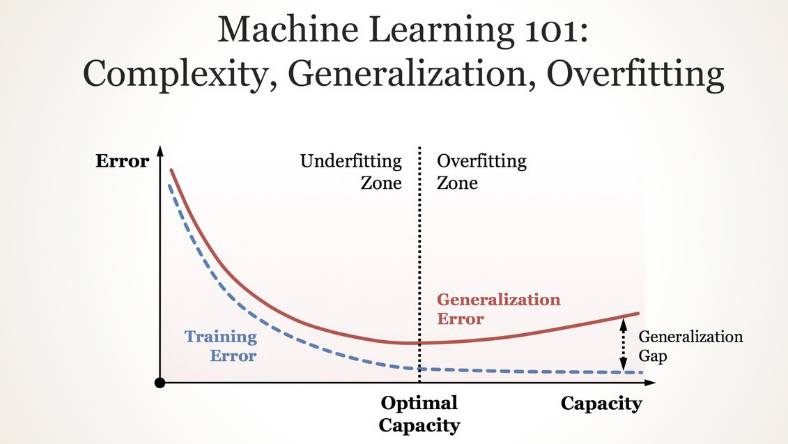
如此,衍生出了一种新的思维方式:对视觉识别的关注点,从模型转移到数据。
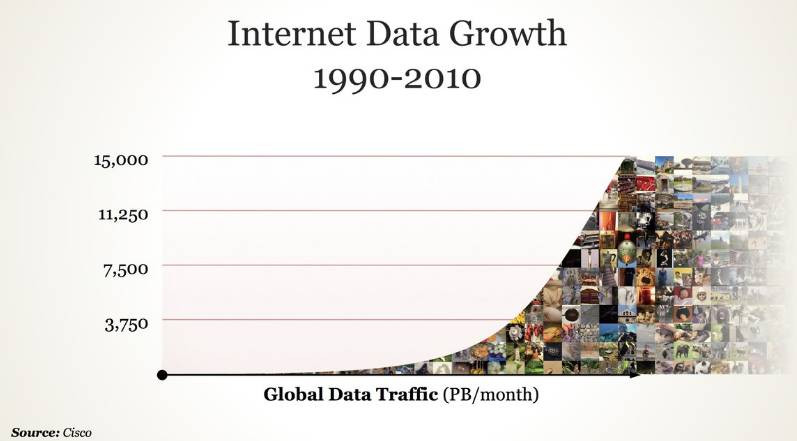
从 1990 年开始到 2010 年,互联网数据的量级有了极大的增长,满足了发展机器学习的数据需求。
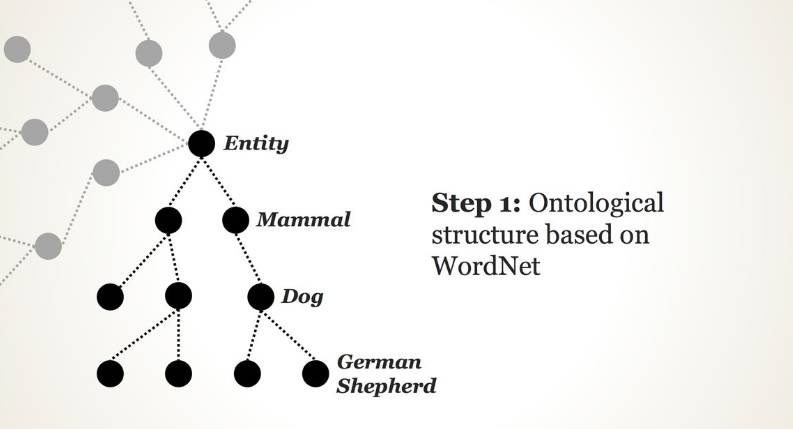
在这里,演讲者对 Wordnet 项目进行了介绍,ImageNet 的层级结构正是从 WordNet 之中派生出来的。
在 20 世纪 80 年代末,普林斯顿大学的心理学家 George Miller 启动了一个名为 WordNet 的项目,旨在构建英文语言层级结构的模型。它就像某种形式的字典一样,但是每个单词都会与其他相关的词相联系——而非以字母表形式呈现。例如,在 WordNet 中,单词「dog」在单词「canine」之下,而后者在「mammal」目录之下,往上往下都有更多的层级。这是为了让语言组织成为机器可读的逻辑,它已经积累了超过 155,000 个单词。

之后,ImageNet 的研究员(包括当时普林斯顿大学博士 Jia Deng、普林斯顿大学教授 Kai Li ) 基于 WordNet 发展出 ImageNet 的层级结构。
第一步:基于 WordNet 的本体结构
第二步:为来自互联网的数千张图像填入类别

第三步:手动清洁结果

发布 ImageNet 的三个尝试
这部分,演讲者介绍了 ImageNet 发起者们为推进 ImageNet 所做的三个尝试。
第一种方式:心理学实验,但这种方式会非常耗时间。

第二种方式:人类参与的解决方案。机器生成的数据集只能匹配一时的最佳算法,而人类生成的数据集超越了算法限制,能够生成更好的机器感知。

第三种方式:众包
通过亚马逊 mechanical turk 平台,来自 167 个国家的 4 万 9 千名工作者用 3 年(2007-2010)努力成就了 ImageNet。

演讲者介绍说,他们的量级目标是 1500 万,还有更高的清晰度、更高质量的标注、免费等。

惊人的成就
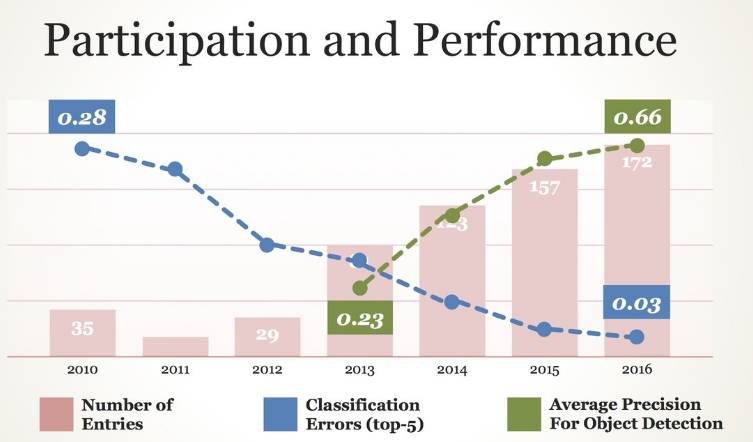
一张图总结 2010-2016 年的 ImageNet 挑战赛成果:分类错误率从 0.28 降到了 0.03;物体识别的平均准确率从 0.23 上升到了 0.66。
为了让 ImgaNet 变得更好,发起者们也做了许多细节工作,比如图像量、物体种类的倍数级增加。
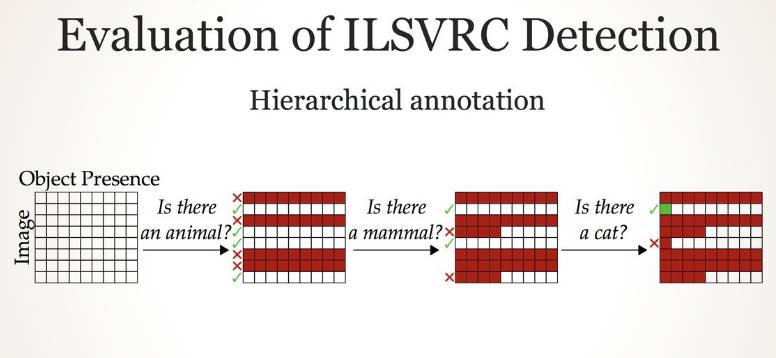
ILSVRC 检测的评估需要注解所有出现的类别,从而对虚假检测做出惩罚。ILSVRC 图像达 40 万张,类别数量为 200,注解有 8000 万个。

ILSVRC 检测的评估:分层注解。
细粒度识别。ImageNet 关于汽车的数据集中,汽车图像的数量达到了 70 万张,类别数量为 2567 个。

演讲者介绍了 ImageNet 所取得的意料之中的成果。主要包括三个方面:1. ImageNet 成为了计算机视觉识别领域的标杆;2. 物体识别领域取得了前所未有的突破;3. 机器学习获得了长足发展,同时变化也很大。
除此之外,还取得了一些意料之外的成果:神经网络再一次流行起来,并且越来越流行。演讲者举例进行了说明。在使用深度卷积神经网络进行 ImageNet 分类任务中,有一篇成果显著的论文,即《imagenet classification with deep convolutional neural networks》(Krizhevsky, Sutskever & Hinton, NIPS 2012),该论文摘要如下:我们训练了一个大型的深度卷积神经网络,把 ILSVRC 2010 训练集中的 130 万高分辨率图像分为了 1000 个不同的类别。在测试数据中,我们获得了 top1 和 top 5 的误差率,分别是 39.7\% 和 18.9\%。该论文的引用数量为 13259,神经网络之火热可见一斑。同时演讲者还给出了该深度卷积神经网络的图示。

随后,神经网络变得越来越流行,并出现了多种优秀变体,可谓百花齐放,比如 AlexNet、GoogLeNet、VGG Net、ResNet。相信这些神经网络大家并不陌生。其中出现较早的是 2012 年的 AlexNet,它最早在 [Krizhevsky et al. NIPS 2012] 被提出;新近出现的是 2016 年的 ResNet,它在上年的 CVPR 中被提出,刚好一年。这些变体之间是一种前后相继、不断迭代的关系,同时又发挥着各自的独特作用。
神经网络流行的同时,网络上的图像数据量有了爆发性的增长,GPU 的性能也在飞速提升,三者合力的结果就是为人类带来了一场席卷全球的深度学习革命。
接下来讲一下本体结构:一种不太常用的结构。
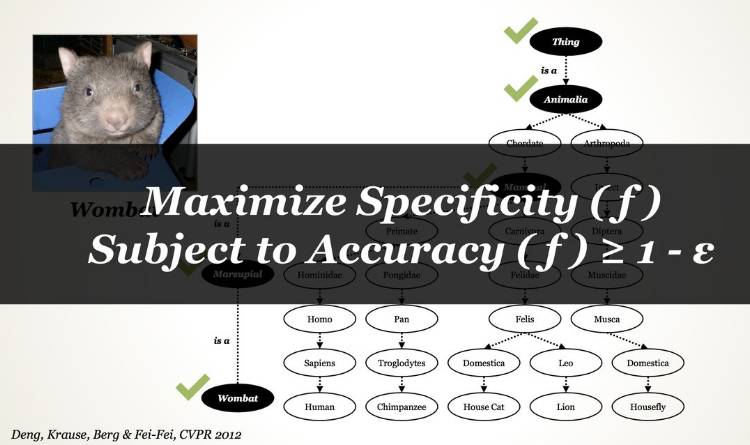
如图所示,这是一只袋熊,那么如何把这种图像识别为一只袋熊呢?方法是最大化特征 ( f ) 使其符合精确度 ( f ) ≥ 1 - ε。
使用本体结构开展的工作相对来讲依然很少(谷歌上只有 93 条结果),但并不妨碍有成果出现。ECCV 2012 最佳论文奖(Kuettel, Guillaumin, Ferrari.Segmentation Propagation inImageNet. ECCV 2012)就用到了本体结构。
机器视觉和人类视觉
自从 2012 卷积神经网络在计算机视觉上取得极大的成功后,我们一直在探索拥有更强大机器视觉的可能性。这也令大家都看到了近来计算机视觉所存在的局限,比如说小数据集训练,虽然我们能使用预训练模型进行迁移学习,但每一个类别仍然需要成百上千的标注图像。还有比如说分清视觉的本质和外在,人类很容易分清楚穿了驯鹿服的狗还是狗,但计算机却十分容易将其分类为驯鹿。这一些缺点都直接限制了计算机视觉的发展,那么计算机视觉和我们人类到底区别在哪?
如下所示,相对于 GoogLeNet,Top-5 误差率还是人类高一点,但如果使用近来最先进的模型,人类识别率却不一定比机器高。但识别误差率就是最关键的吗?

在计算视觉的机眼中,识别的物体永远都只是类别。如下所示,机器可以轻松地识别每个物体(如人和房间等),但是机器视觉也仅仅只能做到识别了,它不会思考这些人到底在干什么,他们为什么都站在这,他们之间的关系是什么。而人类即使识别物体的准确率可能还不及机器,但我们的视觉可以带给我们足够的信息以分析整个场景。
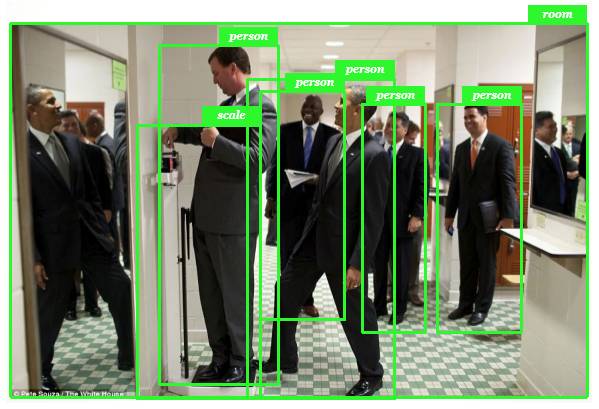
如下所示,人类的视觉不仅会告诉我们每个物体是什么,同时还会告诉我们物体间的关系、物体下一个时间步骤的动作或趋势以及情感细节等。对于这样的人类视觉,机器视觉还有很长的路要走,这也正是 ImageNet 所希望能促进的。
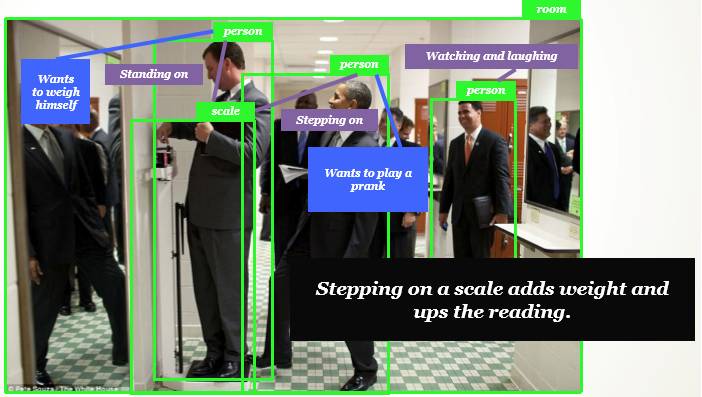
鉴于机器视觉和人类视觉之间的差距,我们因此希望计算机能描述其所见到的图像。如下所示,计算机可以在物体识别的基础上推断出物体间的关系,并结合 NLP 给出图像的描述。

总的来说,随着硬件和软件技术的发展,计算机视觉的技术正在不断进步,目前机器学习(深度学习)在常见图片的物体识别上已实现类似人类的识别水平。
不仅如此,目前的技术已经可以实现对一张复杂照片中的内容进行自然语言描述,并回答相应问题了。这说明深度学习可以理解图片中的内容,并将其转化为可掌握的知识。虽然这一过程还非常基础,但这有助于拉近机器与人类的距离。图像描述一般也有专用的数据集,例如 Visual Genome Dataset 等。该数据集如下有 4.2M 的图像描述和 1.5M 的关系标注,它是基于目标分类实现关系和情景推理的优秀数据集。ImageNet 的下一步很可能就要传递给这些开放、大规模、详细的数据集。

ImageNet 的未来
ImageNet 2017 挑战赛是最后一届,李飞飞在 CVPR 2017 上表明 ImageNet 挑战赛以后将与 Kaggle 结合。她在演讲中欣喜地表明她们正在将接力棒传递给 Kaggle,不仅因为 Kaggle 社区是最大的数据科学社区,同时还因为她们认为只有将数据做到民主化才能实现 AI 民主化。虽然 ImageNet 挑战赛是最后一届了,但 image-net.org 仍然会一直存在,并致力于为计算机视觉做出更大的贡献。

Kaggle 拥有超过百万的数据科学家,它能大大地促进更多人参与 ImageNet 挑战赛。从最开始的 AlexNet 到后来的残差网络,我们已经看到 ImageNet 挑战赛催生出了许多优秀的计算机视觉解决方案。也许 ImageNet 加上 Kaggle 能继续在目标识别、目标定位和视频目标识别等任务上实现更大的突破,并解决如模型小型化、快速训练和更强的迁移学习等问题。

经过多年的更新,现如今 ImageNet 已经有 13M(百万)标注图像,但各大科技公司都在构建自己更强劲的数据集。大公司希望能利用其自身用户所产生的海量图像、语音片段和文本片段来构建更大的数据集,而初创科技公司也开始通过各种渠道或互联网数据构建自身的大规模数据集。
开放和自由使用是 ImageNet 的宗旨,这也是 ImageNet 对计算机视觉社区做出的最大贡献。自 ImageNet 以来,很多科技巨头都陆续开放了大规模图像数据集。如谷歌在 2016 年发布了 Open Images 数据集,该数据集包含 6000 多个类别共计 9M 图像,还有 JFT-300M 数据集,该数据集有 300M 非精确标注的图像。因此 ImageNet 的未来可能会催生一批大规模开放数据集。

自 2010 年起,ImageNet 经历了多年的发展,其分类错误现已缩小到当初发布时的 1/10,而这意味着 3 倍的模型预测准确率提升。在未来,计算机视觉的发展将可以预测图片中事物的动作,理解图片中的 3D 环境,并用自然语言对所有这些作出解释。
随着与 Kaggle 合并,ImageNet 挑战赛将会接入这个拥有多达 100 万数据科学家的庞大社区之中,为更多人带来帮助——这与「人工智能民主化」的理念相呼应。与此同时,该项目的原网址 image-net.org 仍将由斯坦福大学继续运营。
「人们已经意识到,ImageNet 改变了人工智能领域,数据集是 AI 研究的核心之一,」李飞飞表示。「在研究中,数据集与算法同样重要。」
在未来,ImageNet 将继续举办物体定位挑战、物体识别挑战与视频物体识别挑战。

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





