因果关系到底存不存在:反事实和平行宇宙
选自inference.vc
作者:Ferenc Huszár
机器之心编译
参与:Nurhachu Null、刘晓坤
本文是 Ferenc Huszár 关于因果推理的系列教程中的第三篇——反事实。反事实(counterfactual)也是一个被重复定义的词。Judea Pearl 对反事实的定义是:「如果...... 将会......」这种问题的概率性答案。其他人则更频繁地使用反事实机器学习或者反事实推理来指代与因果分析相关的广泛性技术。在这篇文章中,作者将聚焦于 Pearl 对反事实的狭义定义。
第二篇:隐藏着的因果关系,如何让相同的机器学习模型变得不同
反事实
例子 1:David Blei 的选举例子
已知希拉里·克林顿没有赢得 2016 年的总统大选,她在大选前三天没有访问密歇根,已知我们知道关于选举情况的所有事情,那么,假如希拉里在大选前三天访问了密歇根,她赢得大选的概率又会如何呢?
让我们试着分解一下这个问题。我们对以下这个概率感兴趣:
假设她会赢得选举
以以下四件事为条件:
她输了选举
她没有访问密歇根
其他任何观察到的相关事实
假设她访问了密歇根
这是一个奇怪的事情:你同时在假设她是否访问了密歇根。而且你还对她赢得选举的概率感兴趣。这是什么鬼?
为什么量化这个概率是有用的?主要是为了信用分配。我们想知道她为何输掉了选举,以及选举失败可以归因于她在大选三天前没有访问密歇根的程度。量化这个概率是有用的,这有助于政治顾问在下一次做出更好的决策。
例子 2: 反事实公平
这里是一个关于反事实的现实应用:评估个人决策的公平性。考虑一下这个反事实问题:
已知 Alice 在工作中没有得到晋升,已知她是一名女性,已知我们可以观察到的关于她的情况和表现的一切事情,那么,如果 Alice 是男性,她的晋升概率又会如何?
还是这样,问这个问题的主要原因是为了确定性别会对我们看到的结果有多大程度的影响。要注意的是,这是一个单独的公平概念,而不是在总体上评定晋升在统计上是否公平。或许晋升系统在整体上是相当公平的,但是在 Alice 的特例中,不公平的特例发生了。
反事实问题基于一个特殊的数据点,在这个例子中是 Alice。
关于这个反事实问题的另一个需要注意的点就是干预(Alice 的性别被奇迹般地改成了男性)并不是我们在实际中可以实现或者进行试验的东西。
我的胡子和我的博士学位
这里有一个例子,我会在讨论中用到,并且这个例子会贯穿这篇文章:我想理解我长胡子的程度和我获得博士学位有什么程度的关联:
已知我是有胡子的,我拥有博士学位,以及我们现在所知的关于我的一切,那么,如果我从未长过胡子,我会以多大的概率获得博士学位。
在我开始描述如何把这个表述为一个概率问题之前,让我们首先思考一下,我们直觉的期望答案是什么?在这个宏大的计划中,我的胡子或许不是我获得博士学位的一个主要因素。即使有什么事情阻止我留胡子,我也会苦苦追寻我的博士学习,并且可能完成学位。所以:
我们期望这个反事实问题的答案会是一个很高的概率,是一个接近于 1 的概率。
观察性查询研究
让我们从最简单的可以尝试回答我的反事实问题的地方开始:收集一些个体数据,他们是否有胡子,是否已婚,是否健壮,是否拥有博士学位,等等。下面是一个描述这么一个数据集的卡通图示:
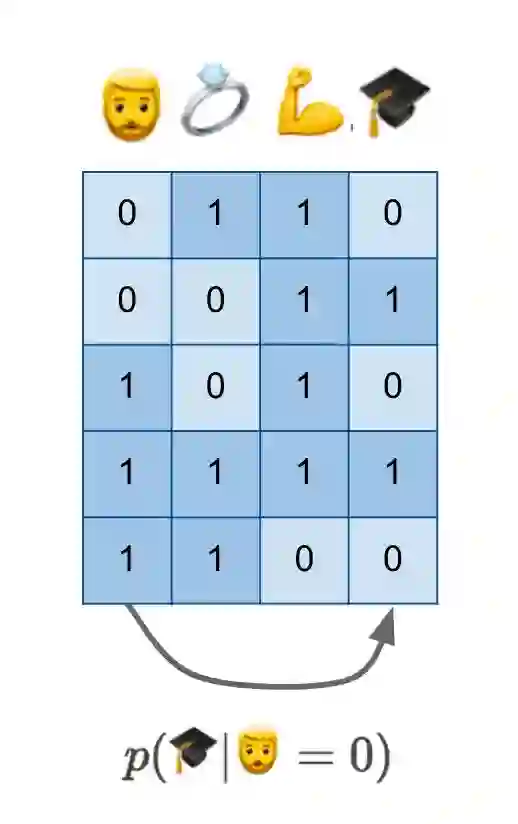
如果我们有这些数据并且用它们做常规的统计机器学习,不做因果推理,我们可能会尝试估计 p(🎓|🧔=0),即有胡子的情况下拥有博士学位的条件概率。正如我在图的底部展示的,这就像是从一列的数值来预测另一列的数值。
但愿你们现在了解了足够多的关于因果推理的东西,知道 p(🎓|🧔=0) 不是我们要寻求的量。如果没有关于因果结构的额外知识,它就无法推广到假设的场景和我们所关注的干预。可能还存在隐藏的混淆因素。或许较高的自闭症谱系得分会让你更有可能长胡子,它也许会让你更有可能获得博士学位。这两个量是否存在因果关系,并不是很明显。
干预查询
在前面的两篇文章中我们已经了解到,如果我们想要推理干预,就必须以一个不同的条件分布来表达,p(🎓|do(🧔=0))。我们还知道,为了推理这种分布,我们需要的不仅仅是一个数据集,我们还需要一个因果图。我们在图中增加一些其他的东西:
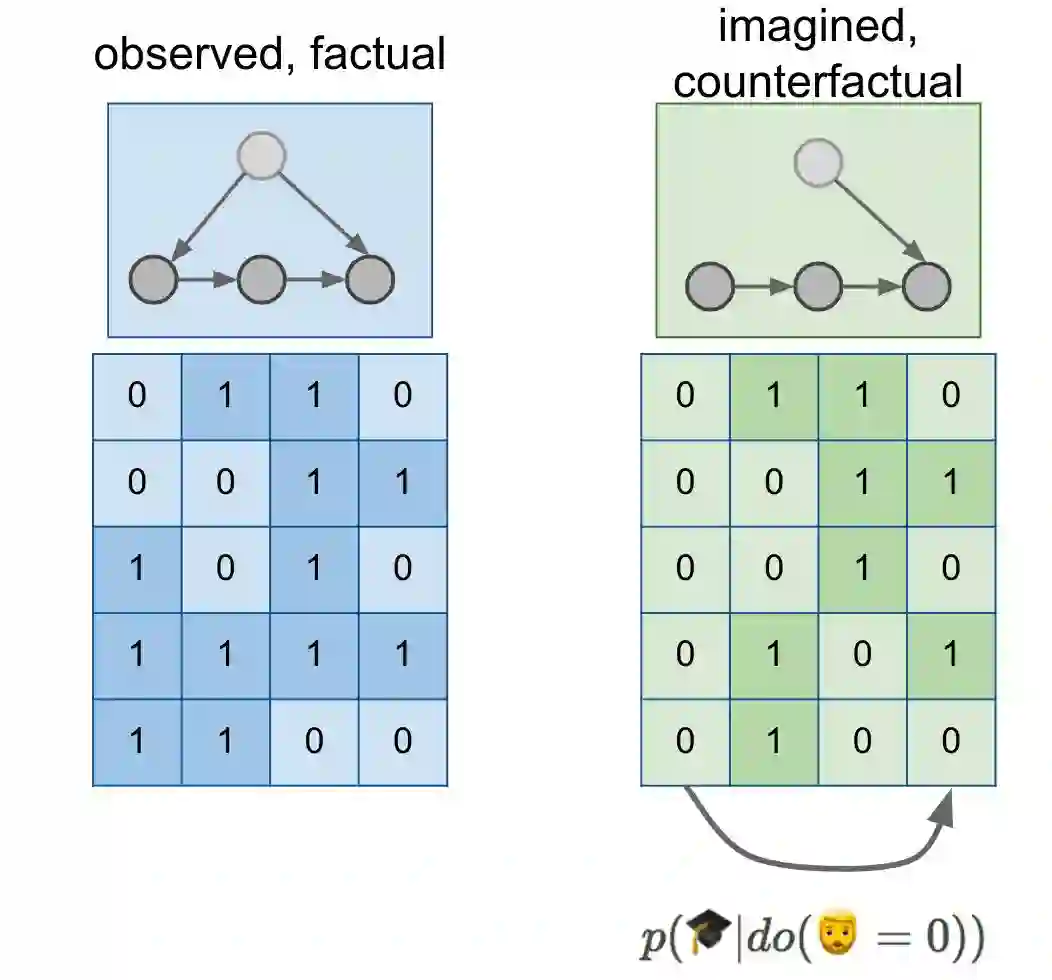
这里,为了说明问题,我在数据上面绘制了一个卡通因果图,它只是从以前的图中复制过来的,并不代表胡须和博士学位的一般理论。但我们这里假设这个因果图已经描述了现实。
这个因果图让我们可以推断出另一个世界中的数据分布,如果你愿意的话,可以推算并行宇宙,在那里每个人都以某种方式被神奇地挂掉了胡须。你可以想象从这个分布中采样数据集,如绿色的表所示。我们可以测量这个绿色分布中博士学位和胡须之间的关联,这正是 p(🎓|do(🧔=0)) 的含义。如表格下方的箭头所示,p(🎓|do(🧔=0)) 是关于从绿色数据集中的一个列预测另一个列的概率。
p(🎓|do(🧔=0)) 能表达我们寻求的反事实概率吗?好了,请记住,我们的期望是即使没有胡子,我也很有可能获得博士学位。然而,p(🎓|do(🧔=0)) 讨论了在刮掉胡须的干预之后随机个体的博士学位的情况。我们直观地期望 p(🎓|do(🧔=0)) 接近博士比例的基本程度 p(🎓),大概是 1-3%。
p(🎓|do(🧔=0)) 讨论了一个随机采样的个体,而反事实讨论的是一个特例。
反事实是「个性化」的,在这种意义下,如果替换成另一个人,结果可能会改变。我父亲留着小胡子,但是他没有博士学位。我觉得不让他长胡子也不会让他有更多的可能获得博士学位。所以,他的反事实概率是一个接近于 0 的概率。
反事实概率是因人而异的。如果你从随机个体中计算它们,然后对概率求平均值,就能得到 p(🎓|do(🧔=0)) 的期望。但是我们现在对多人的期望值不感兴趣,而只对计算每个个体的概率感兴趣。
反事实查询
为了彻底地解决反事实问题,我必须超越因果图,再引入另一个概念:结构方程模型。
结构方程模型
因果图对哪些变量对任何给定节点具有直接因果影响进行了编码——我们将这些变量称为节点的因果父项。结构方程模型更明确地指定了这种依赖性:对于每一个变量,它具有描述每个节点的值与其因果父项的值之间的精确关系的函数。
举个例子:下面是一个在线广告系统的因果图,此图取自 Bottou 等人的论文。
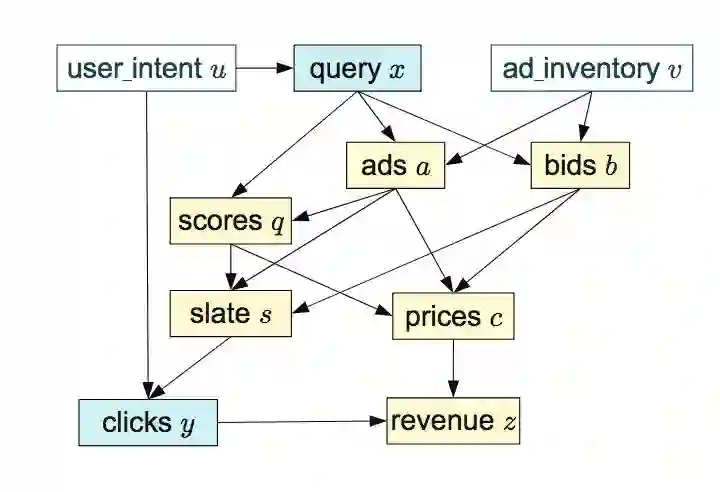
这些变量实际代表的是什么并不重要。图中所示的依赖可以用下面的方程来等价编码。

对于上图中的每一个节点,我们现在有一个对应的函数 fi。每个函数的参数就是它的实例化变量的因果父项,例如 f1 计算得到了来自于因果父项 u 的 x,f2 计算得到了来自于其因果父项 x 和 v 的 a。为了允许变量之间的不确定关系,我们还允许每个函数 fi 具有另外的一个输入ϵi,你可以认为ϵi 是一个随机数。通过随机输入ϵi,f1 的输出可以在给定固定值 u 的情况下是随机的,因此产生条件分布 p(x|u)。
结构方程模型(SEM)需要因果图,因为可以通过查看每个函数的输入来重建因果图。它还能得到联合分布,因为可以通过按顺序评估函数从 SEM 中进行「采样」,在需要的地方插入随机函数。
在结构方程模型中,一个变量的干预(例如 q),可以通过删除对应的函数 f4,使用另一个函数来代替进行建模。例如,做 do Q=q0) 会对应着~f4(x,a)=q0 的常数赋值。
回到胡子的例子
现在我们已经了解了结构方程模型是什么,我们可以回到胡子和学位的例子中了。让我们在图中增加一些其他东西:
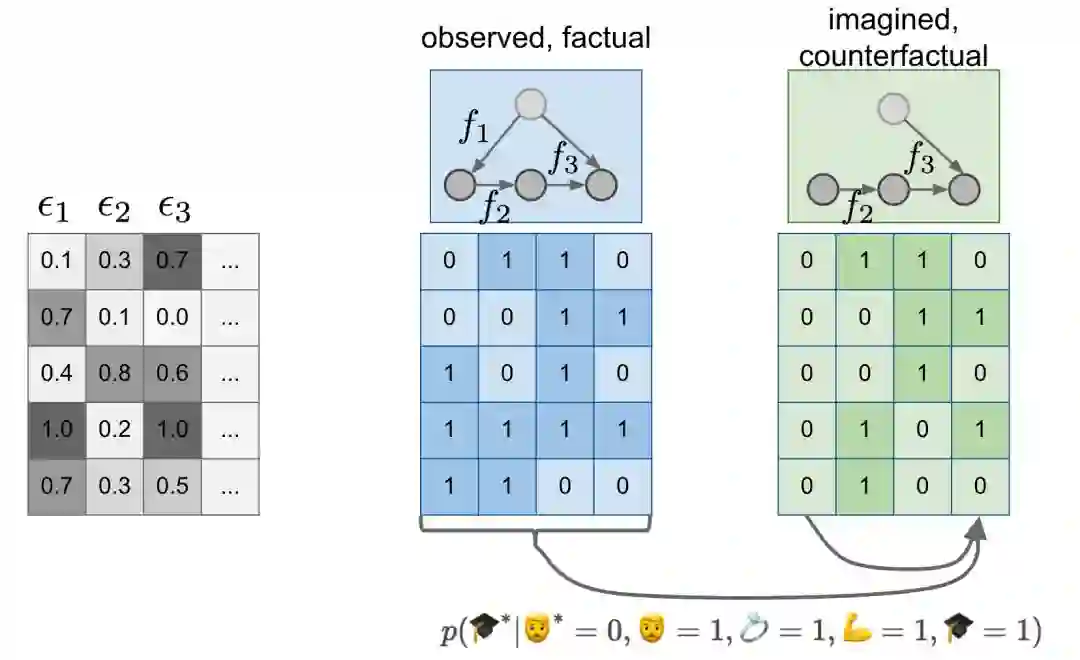
我现在用确定的结构方程模型来建模,在因果图上用函数 f1,f2,f3 标记。请注意,绿色的结构方程模型和蓝色的结构方程模型是一样的,只是我删除了 f1 函数,并用一个常量赋值进行替代。但是 f2 和 f3 在蓝色模型和绿色模型中是一样的。
然后我明确了ϵi 噪声变量的存在,并且在灰色的表格中展示了它们的数值。如果将第一行ϵ输入到蓝色结构方程模型,则会获得第一个蓝色数据点(0110)。如果将相同的ϵ提供给绿色的 SEM,则会得到第一个绿色数据点(0110)。如果将第二行ϵ提供给模型,则会获得蓝色和绿色表中的第二行,依此类推......
我喜欢将第一个绿色数据点视为第一个蓝色数据点的平行孪生点。为了讨论干预,我谈论了在没有人留胡子的平行宇宙进行预测。现在想象一下,对于生活在我们可观测的宇宙中的每一个人,平行宇宙中都有一个对应的人是他的平行孪生点。你的平行孪生点的每一个方面都是和你一样的,除了一点:平行孪生点没有胡子,而且也没有任何由胡子带来的结果。
我们已经建立了双数据点的隐喻,我们可以说,反事实就是:
基于观测到的数据点的特征来预测未观测到的双数据点的特征。
关键是,由于我们在蓝色 SEM 和绿色 SEM 中使用了相同的ϵ,所以这是可能的。这引入了一个关于能够观测到的环境中的变量和不可观测的环境中的变量之间的一个联合分布。绿色表中的列不再独立于蓝色表中的列。你可以使用蓝色表中的列来开始预测绿色表中的值,正如下面的箭头所示。
在数学上,反事实就是下面的条件概率:p(🎓∗|🧔∗=0,🧔=1,💍=1,💪=1,🎓=1)
其中,具有∗的变量是未观测到的(也是不可观测的)变量,它们存在于反事实的世界,而没有*的变量是可观测的。
从数据来看,事实证明,没有胡子的镜子版本的我已经结婚并拥有博士学位,但并不像观察到的我那么健壮。
另一种画图的方式
这是另一张图,有些人可能会觉得更有吸引力,特别是那些熟悉 GAN、VAE 和类似的生成模型的人:
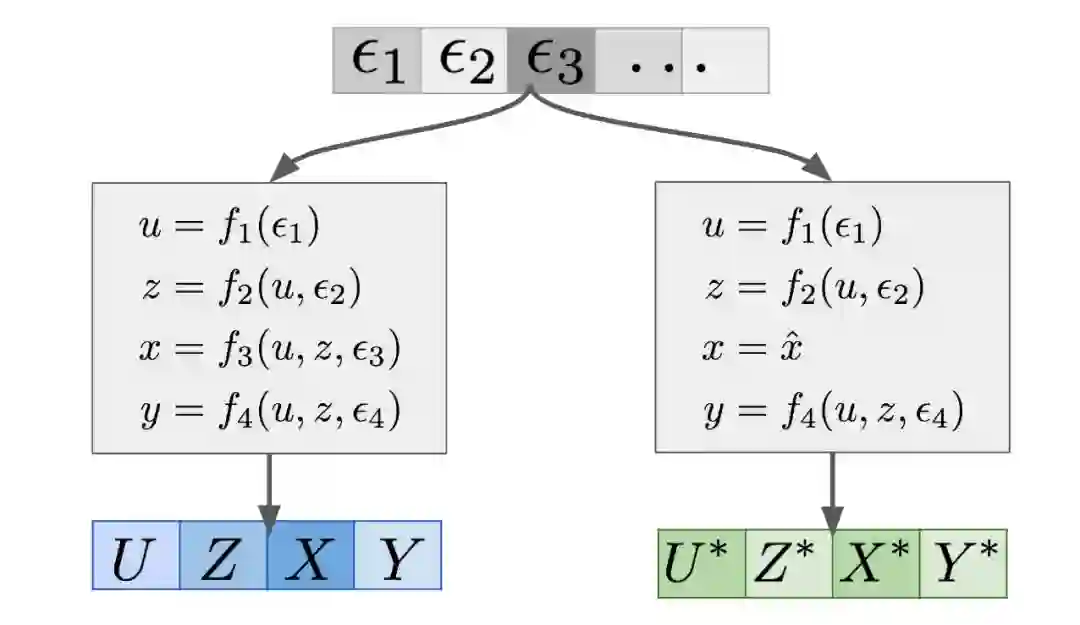
SEM 本质上是一种数据生成模型,在这个例子中,它使用了一些噪声数据 ϵ1,ϵ2,…然后将它们转变成观察变量 (U,Z,X,Y)。这个在上图的左边部分展示。现在,如果你想在干预 X=x^的情况下做反事实陈述,你可以构造一个残缺的 SEM,除了删除了 f3 并替换为一个常量赋值函数 x=x^之外,它与常规的 SEM 是完全一样的。这个修正版的 SEM 在上图中的右边。如果你将ϵ输入到残缺的 SEM 中,你会得到一个变量集 (U∗,Z∗,X∗,Y∗),如图中的绿色区域所示。这些就是孪生点的特征。(U,Z,X,Y) 和 (U∗,Z∗,X∗,Y∗) 中的这个联合生成模型定义了变量 (U,Z,X,Y,U∗,Z∗,X∗,Y∗) 的组成的集合上的联合分布。那么,现在你可以计算这个联合分布中的所有类型的条件概率和边际概率了。
p(y∗|X∗=x^,X=x,Y=y,U=u,Z=z) 是一个反事实预测。实际上,因为 X∗=x^的概率为 1,所以我们可以丢弃这个条件。
现在是时候指出 Pearl 的符号,do 算符现在被广泛接受了。
我们也可以使用这个表达来标识干预条件概率 p(y|do(x)):
p(y|do(X=x^))=p(y∗|X∗=x^)
我们可以看到,干预条件仅仅包含具有*的变量,所以它并不需要 f (U,Z,X,Y,U∗,Z∗,X∗,Y∗) 的联合分布,仅仅需要具有*的变量的边际分布。因此,为了讨论 p(y|do(X=x^)),我们不需要引入 SEM 或者ϵ。
另外,请注意下面的等式:
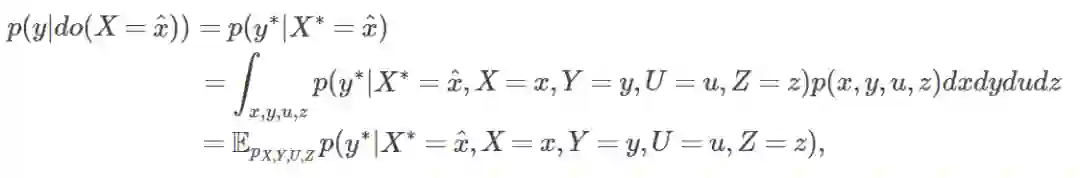
换句话说,干预条件概率 p(y|do(X=x^)) 是可观测群体的反事实的平均值。
总结
反事实通常被认为是不科学的,主要是因为它们不是经验上可测试的。在一般的机器学习中,我们习惯于对数据集进行基准测试,并且我们的预测质量总是可以在某些测试数据集上进行测试。在因果机器学习中,并非所有东西都可以直接测试或根据经验进行基准测试。对于干预,如果可以的话,最好的测试是运行随机对照试验直接测量 p(y|do(X=x)),然后使用这个经验数据来评估你的因果推论。但是有一些干预在现实中是不可能的。想一想关于性别或种族干预的公平性推理的所有工作。那么该怎么做呢?
在反事实的世界中,这是一个更大的问题,因为直接观察你做出预测的变量是完全不可能的。除了微小的变化之外,你不能回到过去并以完全相同的情况重新运行历史。根据星际迷航(Star Trek)的说法,你无法前往平行宇宙(至少在 24 世纪之前)。反事实判断仍然是假设的、主观的、不可测试的、不可证实的。对于满足每个人的反事实,可能没有 MNIST 或 Imagenet 这样的基准,尽管存在一些好的数据集,它们适用于可以进行显式测试的特定场景,或者使用模拟器代替「真实」数据。
尽管它不可测试且难以解释,但人们总是使用反事实陈述,而且直观地感觉它们对于智能行为非常有用。能够确定导致特定情况或结果的原因,这对于学习、推理和智能肯定是有用的。因此,我现在的策略是忽略关于反事实的哲学辩论,并且继续使用它,如果这种预测必须被做出,我知道该使用什么工具。

原文链接:https://www.inference.vc/causal-inference-3-counterfactuals/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com