论文推荐 | 基于单阶段小样本学习的艺术风格字形图片生成
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

本文简要介绍 ACM SIGGRAPH Asia 2019 所录用(将发表于ACM Transactions on Graphics (TOG), vol. 38, no. 6, Article No. 185,2019)的一篇长文《Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning》。该论文主要针对艺术特效字形图片生成问题,提出了一种基于单阶段少量样本学习的模型,实现了仅利用少量样本就可以生成整个艺术特效字体库,并且生成的字形图片与给定的少量样本在艺术特效风格上具有一致性。
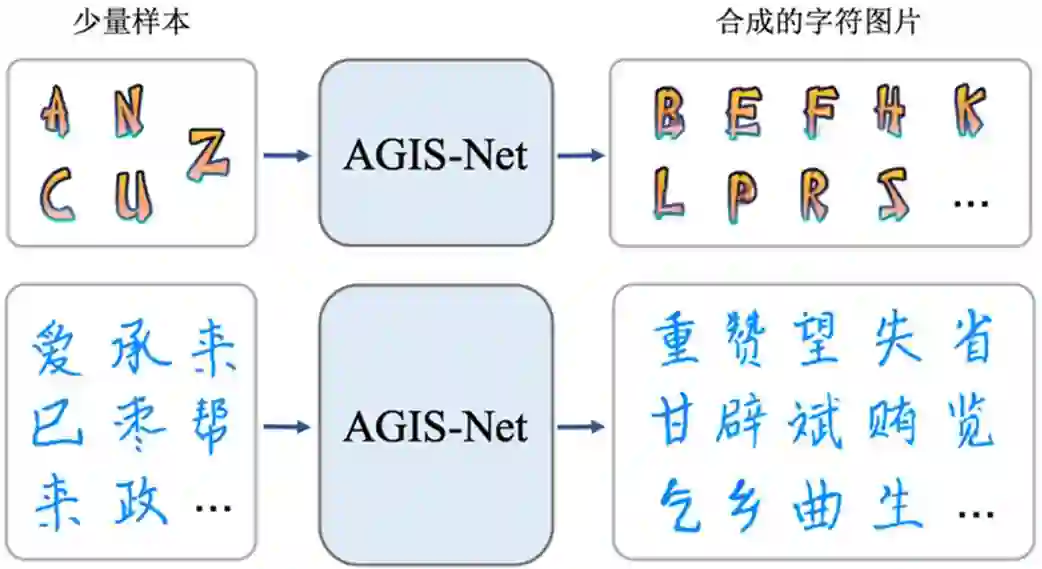
一、研究背景
随着计算机技术和移动互联网的迅速发展,计算机字库尤其是艺术字体字库在日常生活中越来越常见,人们对更具个性化的艺术字体需求却越来越大。但是由于其比普通印刷字体更复杂,所以设计制作一套艺术字体十分耗时耗力。近年来,人工智能技术的发展让计算机自动完成字体设计、字库生成变为可能。基于少量样本的艺术特效字体库自动生成任务主要有三大难点:一是艺术特效字体相比于印刷字体,具有更多的细节、纹理和形状变化;二是必须要从少量样本中高效地提取出风格特征;三是必须要把提取的风格特征正确地迁移到目标字符上,且保证风格一致。目前已有Azadi 等人 [1] 初步实现了英文字符的艺术特效风格迁移,但仍然存在两个问题:1)该方法只能应用于26个英文大写字母,无法在汉字等包含大量字符的语言系统上使用;2)该模型的参数量非常大,训练困难。
二、方法原理简述
与其他风格迁移工作类似,这篇文章将带艺术特效的字形图片分解为风格和内容:风格包括字形风格和色彩纹理风格,其中字形风格为文字的笔画粗细、衬线等印刷字体风格,色彩纹理风格表示文字的笔画颜色、纹理变化风格;内容即表示该文字为哪一个字母或汉字等。
将生成任务定义为一个映射函数。映射函数将一张内容参考图片xc和同一种风格参考图片组成的风格化图片参考集合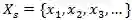
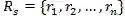
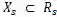
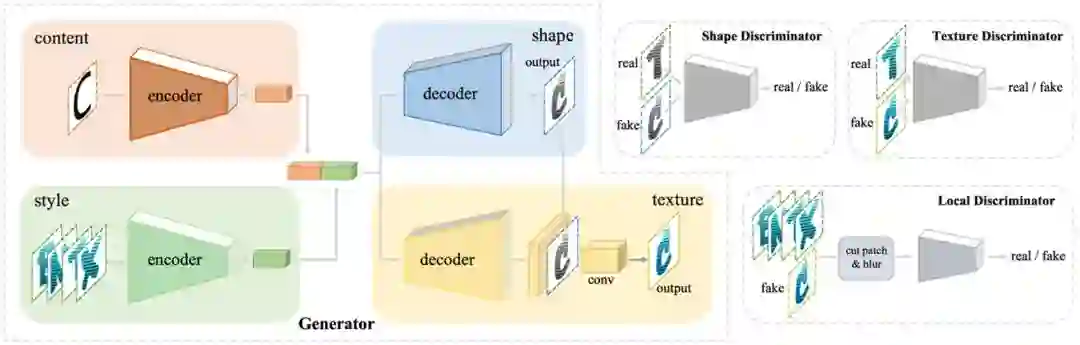
如图2所示,这篇文章提出的 AGIS-Net(艺术特效字形图片合成网络)的整体框架包含一个生成器 G,以及3个判别器:形状判别器Dsha,纹理判别器 Dtex,和局部判别器 Dlocal.
生成器 G包含两个编解码器分支。两个编码器的结构几乎一样,分别负责风格和内容的编码,由多个卷积层组成。风格编码器的输入为从风格参考集合中随机选取的几张风格图片;内容编码器的输入为无风格(如英语中Code New Roman 字体或中文中的平均骨架字体)的字符图片。对于两个解码器,一个负责字形风格的合成另一个负责色彩纹理风格合成,由多个上采样卷积层组成。与 Pix2pix[2] 类似在两个解码器中我们使用了跳连接(SKip Connections)(如图3)。每一层的输入是前一层的输出和两个编码器对应层特征的串联。然后,字形解码器输出字形灰度图像 ygray. 纹理风格解码器结构类似,但每一层输入额外串联了字形风格解码器对应层特征,跳连接的目的是充分利用不同尺度的特征。在纹理解码器的末尾,是对先前特征和灰度图像的串联后进行卷积操作。通过两个解码器的合作最终得到风格化的图像y.
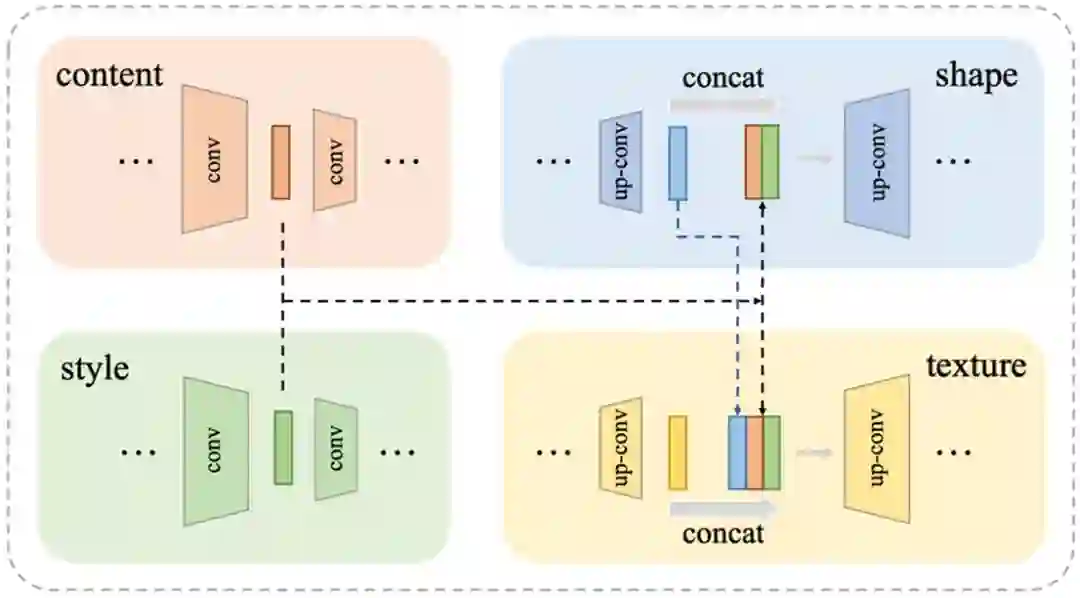
形状判别器 Dsha 用于判别字形灰度图像 ygray的真假;纹理判别器Dtex 负责判别风格化图像y的真假。在训练过程中,合成的灰度图像 ygray 和 y 分别作为两个判别器的Fake 输入,判别器的 Real 输入取决于当前目标字符是否在参考集合Rs中,如果在的话,为 Ground-truth图片,否则从风格化输入Xs中随机选择。
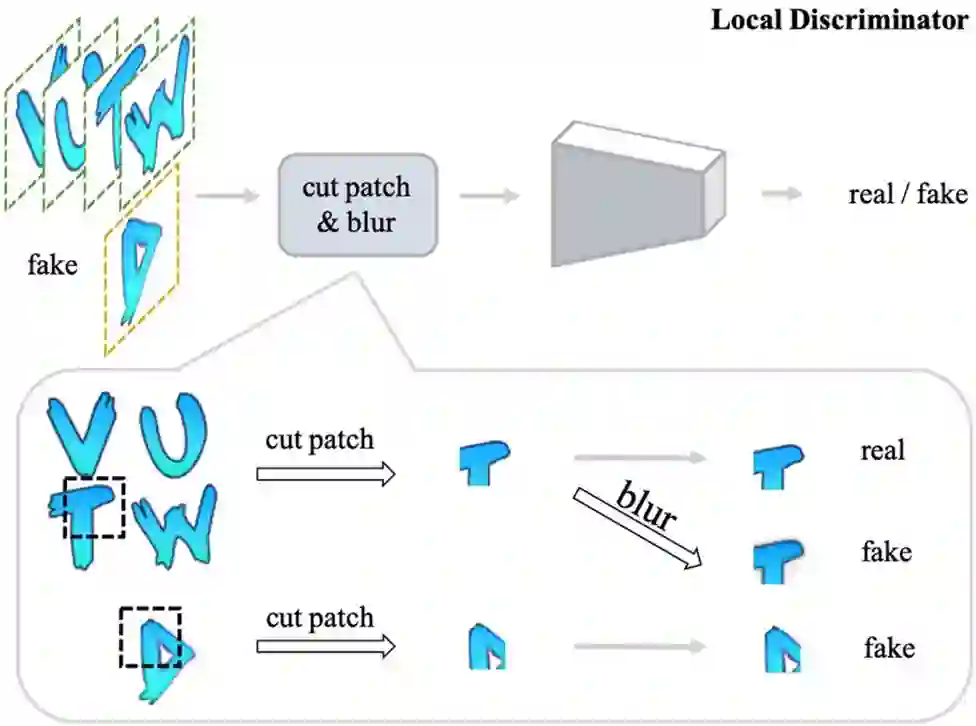
由于在少量样本学习任务中,可以利用的风格化图片很少,所以为了解决训练样本不充分和不平衡的问题,这篇文章提出了 Local Texture Refinement loss。首先从风格化输入图片集合和合成图片中随机剪取小块,作为局部判别器的输入,从而使得训练样本相对充分和平衡。为了使生成器合成细节更好的结果,此文将风格化输入图片对应的 Real Patch 添加高斯模糊得到另一个 Fake 样本,因此可以在清晰样本和模糊样本之间建立一定联系,进而 Dtex能够强制G生成更清晰的字符图片。
为了稳定模型收敛过程,此文模型在合成特效字形数据上进行预训练。模型采用端到端的训练方式,除了 GAN [3] 模型标准的对抗损失(Adversarial Loss)以及 Local Texture Refinement loss 之外,此文还使用了 L1 loss 和 Contextual Loss [4]. 在少量样本学习(Few-shot Learning) 过程中,与对抗损失类似,如果目标字符不在风格化参考集合中,将没有Ground Truth 图片,L1 和 Contextual 损失都为 0 (预训练时都不为0)。
三、主要实验结果

此文在 MC-GAN [1] 提出的英文合成数据上和此文提出的中文合成数据上进行了预训练,图5是与经典方法BicycleGAN [5] 和 MS-Pix2pix[6] 的学习能力对比可视化结果。

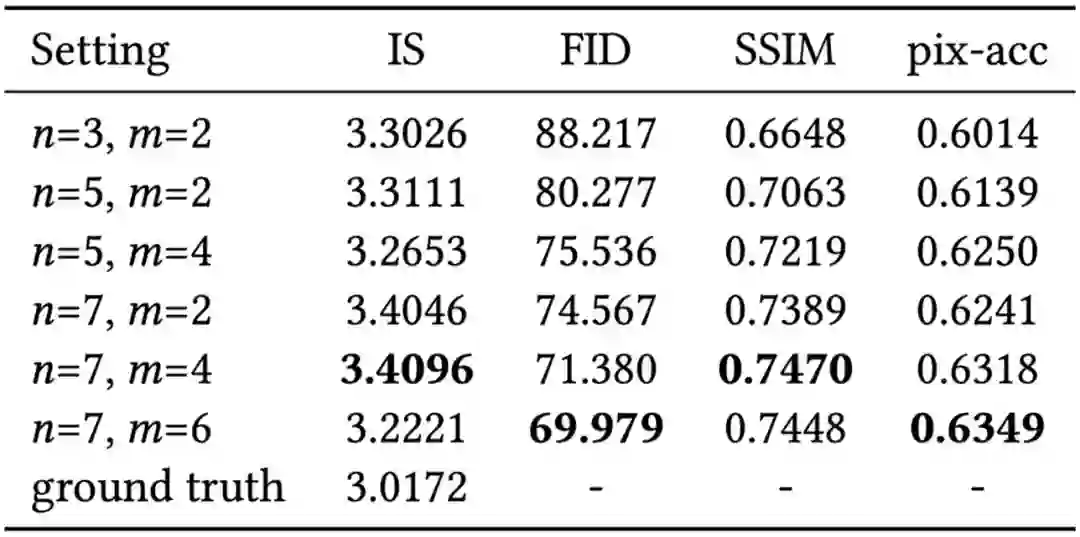

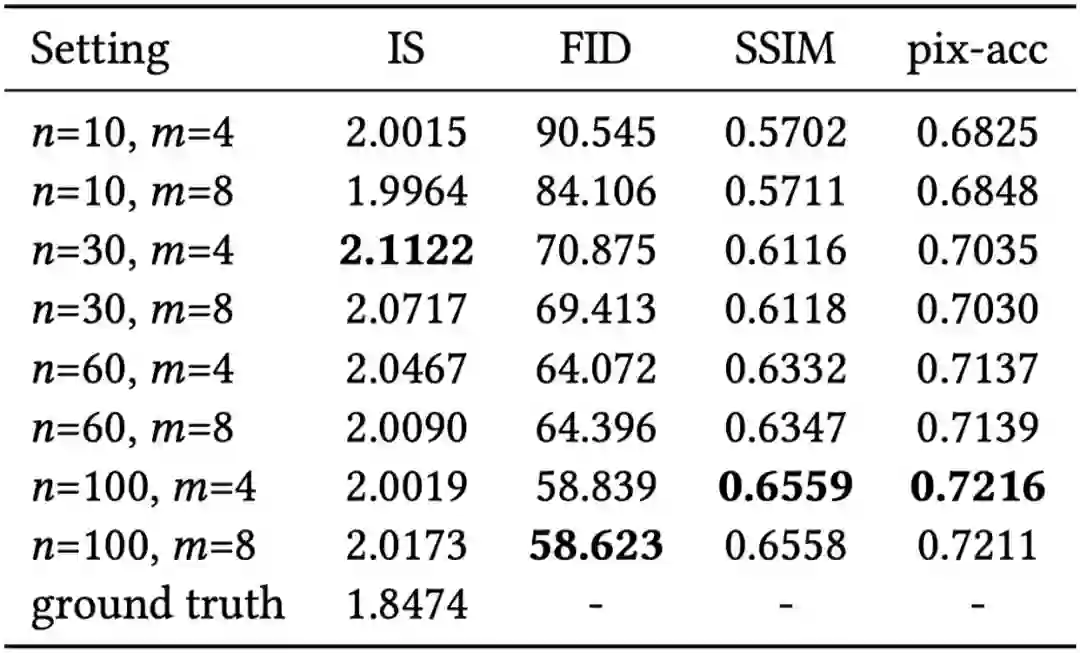
为了选择最优的参数n(参考集合大小)和m(输入集合大小),此文分别在中英文数据集上进行了参数对比实验,图6 和图 7 为可视化结果,表1 和表 2 分别为定量实验结果。

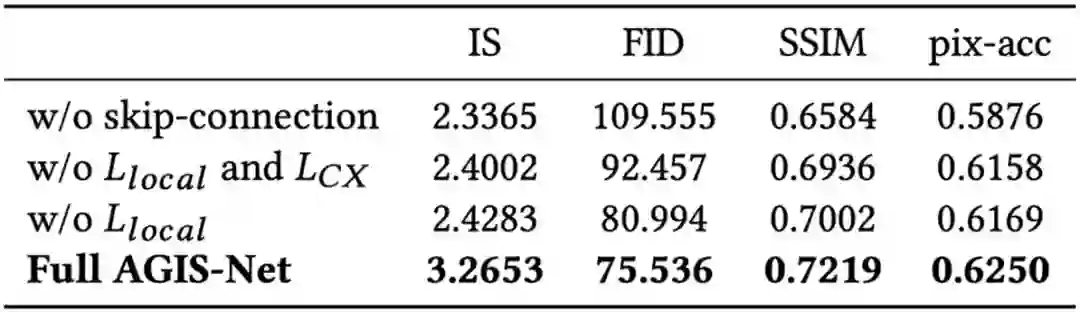
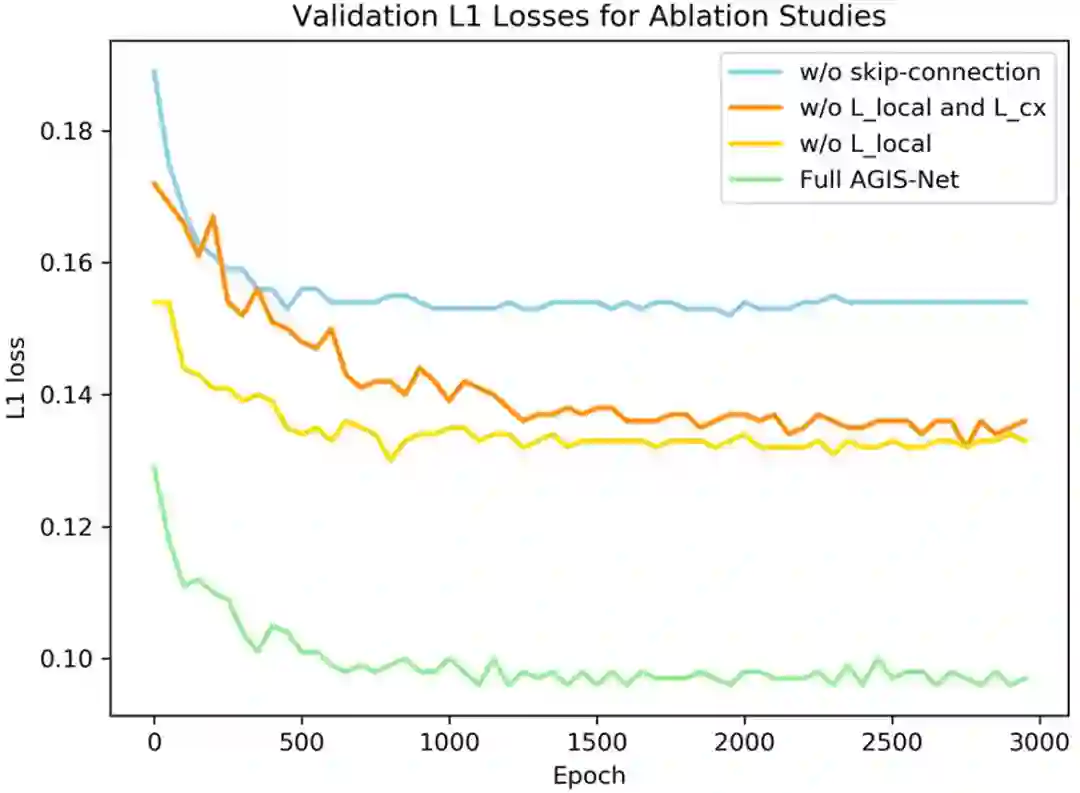
为了验证各模块的有效性,此文在英文艺术特效字形数据集上进行了消融实验,可视化和定量结果分别如图8,9 和表 3 所示。

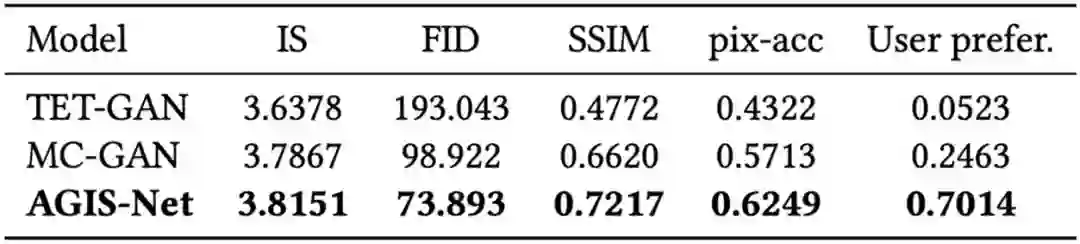

表5. 少量样本中文字符合成定量对比结果
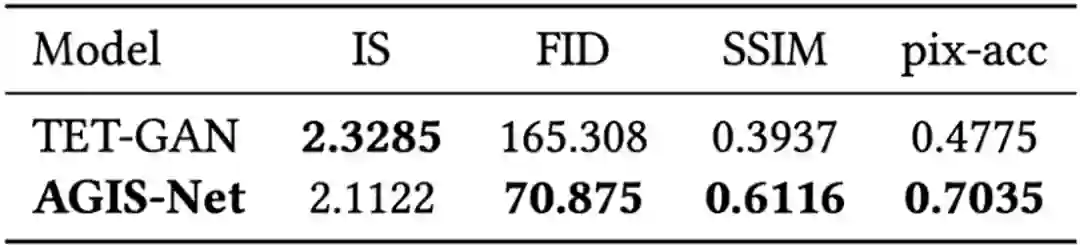
图 10 和表 4 展示了在英文艺术特效字形数据集上,此文方法与目前最好方法MC-GAN[1] 和 TET-GAN[7] 的定性和定量对比结果。类似地,图11 和表 5 为中文数据集上的结果。



为了进一步验证此文的泛化能力,此文进行了未探索字符(预训练和 Fine-tune 都没见过的字符)合成实验,结果如图12和13;并且在中文字形数据集上预训练进行跨语言字符合成实验,结果如图 14 所示。
四、总结
在此文中,作者为艺术特效字形图像合成提出了一种新颖的单阶段少量样本学习模型。提出的AGIS-Net 只需要少量的训练样本作为输入,然后就可以为任何其他字符合成与训练数据相同的艺术风格的高质量字符图像。此文还建立了一个新的大规模中文字形图像数据集,用于性能评估。在两个公开的数据集上进行的实验表明,此文模型能够生成高质量的艺术特效字形图像,同时保持内容信息和样式的一致性。
五、相关资源
1. AGIS-Net 论文地址:http://arxiv.org/abs/1910.04987
2. AGIS-Net 源代码及数据集地址:https://hologerry.github.io/AGIS-Net/
3. 此论文详细信息: Y. Gao, Y. Guan, Z. Lian, Y. Tang, J. Xiao. Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning. ACM Transactions on Graphics (TOG).vol. 38, no. 6, ArticleNo. 185, 2019 (to be presented at SIGGRAPH Asia 2019)
参考文献
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~






