【开发者的2018】GAN、AutoML、统一框架、语音等十大趋势

新智元编译
来源:medium
作者:Alex Honchar 翻译:刘小芹
【新智元导读】本文从开发者的角度,总结了GAN、AutoML、语音识别、NLP等已经可以用于实际产品的技术,以及值得关注的新趋势。作者认为,有ONNX这类的统一格式,Caffe Zoo等模型库,以及AutoML等自动化工具,制作基于AI的应用已经变得非常容易。

虽然生成对抗网络几年前就出现了,我对它是相当怀疑的。几年过去了,即使看到GAN在生成64x64分辨率的图像方面取得了巨大的进步,我对它仍是怀疑的。在阅读了一些数学文章之后,我更加怀疑了,因为这些文章说GAN并没有真正了解分布。但在2017年,事情有所改变。首先,一些新的有趣的架构(例如CycleGAN)和数学上改进的架构(例如Wasserstein GAN)让我实践了一些GAN网络,它们的表现一般,但在完成这两个程序之后,我确信我们可以,并且应该使用GAN来生成东西。
首先,我非常喜欢NVIDIA的一篇关于生成全高清图像的研究论文,生成的图像看起来非常真实(与一年前的64x64分辨率的令人毛骨悚然的人脸相比):

还有很多GAN在游戏行业的应用,例如用GAN生成游戏场景,英雄乃至整个世界。而且我认为我们必须意识到全新的造假水平正在出现,例如网上的完全虚假的人物(也许很快也会出现在线下)?
现代发展的问题之一(不仅仅在AI领域)是,做同样的事情有几十个不同的框架可选。当前,每家做机器学习的大公司都必须拥有自己的框架:谷歌,Facebook,亚马逊,微软,英特尔,甚至索尼和Uber都有自己的机器学习框,以及其他许多开源解决方案。在一个AI应用程序中,我们希望使用不同的框架,例如计算机视觉方面用Caffe2,NLP用PyTorch于一些推荐系统用Tensorflow / Keras。但是将这些应用合并起来需要花费大量的开发时间。
解决方案是开发一个唯一的神经网络格式,它可以很容易地从任何框架中获得,而且必须让开发者可以轻松部署,让科学家可以轻松使用。这就是ONNX:

事实上,ONNX只是一个非循环计算图表的简单格式,但在实践中它让我们得以部署复杂的AI解决方案,而且我个人认为它非常有吸引力——人们可以在PyTorch这样的框架中开发神经网络,它没有强大的部署工具,而且不依赖Tensorflow生态系统。
三年前,人工智能领域最让人兴奋的是Caffe Zoo。当时我正在做计算机视觉方面的工作,我尝试了所有模型,检查它们如何工作以及它们能做什么。然后,我将这些模型用于迁移学习或特征提取器。最近我使用了两种不同的开源模型,只是作为一个大型计算机视觉流程的一部分。这意味着什么呢?意味着开发者实际上没有必要自己训练网络,例如,训练ImageNet的对象识别或位置识别网络,这些基本的东西都可以下载然后插入到你的系统即可。除了Caffe Zoo之外,其他框架也有这样的Zoo,但是让我非常惊讶的是,你可以在计算机视觉,NLP甚至是iPhone的加速度计信号处理插入模型。
我认为这类Zoo只会越来越多,并且由于ONNX这样的生态系统的出现,它们会更加集中(也会使用ML区块链应用来去中心化)。
设计一个神经网络的体系结构是一件痛苦的事情,有时侯只是堆叠一些卷积层就能得到相当好的结果,但是大多数时候,你需要利用直觉和超参数搜索方法(例如随机搜索或贝叶斯优化)非常仔细地设计宽度,深度和超参数。如果不是计算机视觉方面的工作会尤其难,计算机视觉的话你可以微调在ImageNet上训练的DenseNet,但是一些3D数据分类或者多变量时间序列应用就很难。
使用另一个神经网络从头开始创建神经网络架构的方法有很多,但对我来说最友好、最清洁的是Google Research最新开发的AutoML:
用AutoML生成的计算机视觉模型比人类设计的网络工作得更好、更快!我相信很快就会出现很多关于这个话题的论文和开源代码。我认为我们会看到更多的博客文章或创业公司,说“我们的AI创造了学习其他AI的AI...”,而不是“我们已经开发了一个AI ...”。
对于这个概念,我在Anatoly Levenchuk的博客上看了很多。在下面的图片中,你可以看到一个可以称为“AI stack”的例子:
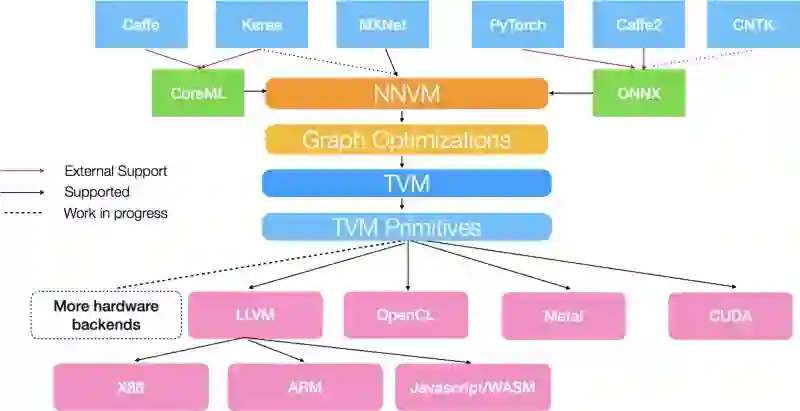
它不仅仅包括机器学习算法和你喜欢的框架,而且它的层更深,每个层都有自己的发展和研究。
我认为AI开发行业已经足够成熟,有许多不同领域的专家。你的团队中只有一名数据科学家是远远不够的——你需要不同的人员做硬件优化,神经网络研究,AI编译器,解决方案优化,生产实施等等。在他们之上必须有不同的团队领导,有软件架构师(必须分别为每个问题设计上面的stack)和管理者。
如果把准确度设为95%以上,AI可以解决的问题就很少:识别1000个类别的图像,识别文本是积极还是消极情绪,以及围绕图像识别和文本识别的更复杂的一些事情。我认为还有一个领域,即语音识别和生成。事实上,一年前DeepMind发布的WaveNet的表现相当不错,而且现在还有百度的DeepVoice 3,以及最近谷歌开发的Tacotron2:
这一技术很快会开源(或者被一些聪明人复制),并且每个人都能够以非常高的精度识别语音以及生成语音。那么等待我们的是什么呢?是更聪明的私人助理,自动阅读器和自动转录工具,以及,假冒的声音。
今天的所有bot都有一个很大的问题:99%根本不是AI,只是硬编码。因为我们没法简单地用数百万次对话数据来训练一个encoder-decoder LSTM,然后就得到智能系统了。这就是为什么Facebook Messenger或Telegram中的大多数bot都只有硬编码的命令的原因,或者最多还有一些基于LSTM和word2vec的句子分类神经网络。但现在最先进的NLP技术已经超出这个水平。例如Salesforce已经做了一些有趣的研究,他们构建了NLP和数据库的接口,克服现代 encoder-decoder 自回归模型的局限,不仅为文字或句子训练嵌入,而且包括字符(characters)。
我相信伴随着这些发展,我们至少可以用更智能的信息检索和命名实体识别来增强bot的能力,以及在一些封闭的领域开发完全深度学习驱动的bot。
前不久,Uber AI Lab发表了一篇博客,展示了他们的时间序列预测方法。 这是将统计特征和深度学习表示相结合的好例子:
例如使用34-layer 1D ResNet诊断心律失常的模型。它最酷的部分是性能:不仅比常见的统计模型更好,甚至诊断准确率优于专业心脏病专家!
如何训练神经网络?说实话,我们大多数人只是使用一些“Adam()”和标准的学习率。更聪明的人会选择最合适的优化器,并调整学习率。我们总是低估优化,因为我们只需按下“train”按钮,然后等待网络收敛。但是在计算能力,内存和开解决方案方面,我们都拥有或多或少的平等机会,优胜者是那些能够用最短时间获得最佳性能的——这一切都来源于优化。
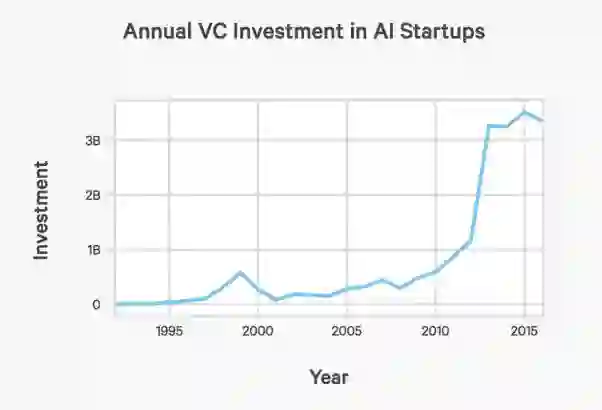
来源:cdn.aiindex.org/2017-report.pdf
上图说明了什么呢?考虑到已经发布的开源工具和算法有多少,开发一些新的有价值的东西并且为之获得大量资金并不容易。我认为2018年对于创业公司来说不是最好的一年——竞争对手会更多,把开源的网络作为移动应用程序来部署,也可以称之为创业公司。
有几种技术已经可以用于实际产品:时间序列分析,GAN,语音识别,以及NLP的一些进步。我们不需要自己设计分类或回归的基本体系结构,因为AutoML能够帮我们做这些事情了。我希望通过一些优化改进,AutoML能够更快。加上ONNX和Model Zoo,只需两行代码就能为我们的app加入基本的模型。我认为至少在目前最先进的水平上,制作基于AI的应用程序已经变得非常容易,这对整个行业来说都是好事!
原文:https://medium.com/swlh/ai-in-2018-for-developers-2f01250d17c

新智元2018新年寄语
2017年有几个关键词,第一是探索极限,探索人类智能和机器智能的极限。第二是城市升级,无论智能交通还是中国要用人工智能作为支柱产业,可能都会面临国家经济体系的升级。第三是产业跃迁,我们要接地气,每个产业都用AI技术赋能,爆发出来颠覆传统体系的潜力。
2017,新智元见证人工智能成为时代主流,中国企业成为全球互联网主角,新智元平台也实现超35万平台用户产业链互联。与掌握AI技术的智者同行,是新智元之幸。2018,我们不忘初心再出发,一起构建AI开放平台,助力中国智能+

最后,祝愿新智元的朋友们能够利用AI工具赋能社会、赋能人类。
——新智元创始人兼CEO 杨静

加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信aiera2015入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
2018,加入新智元社群,一起构建AI开放平台,助力中国智能+




