“诗画合一”的跨媒体理解与检索
编者按:王维的千古名句“大漠孤烟直,长河落日圆”,展现了其将诗画浑然一体的创作功底。苏轼更是曾以一题跋来评价王维的《蓝田烟雨图》:
味摩诘之诗,诗中有画;
观摩诘之画,画中有诗。
《蓝田烟雨图》虽已失传,“诗中有画、画中有诗”,却流传了下来,并代表了古代跨媒体理解领域,文本与图像之间映射关系的最高水平。
古人在品诗赏画时,是通过脑中的神经网络来寻找诗与画之间的联系,而在现代计算机世界中,由于媒体类型更加多元化,在文本、图像之外,还增加了声音、视频等融合了时序信息的数据,因此,更需要一种有效的手段来实现跨媒体的理解与检索。
今天,来自电子科技大学的申恒涛教授,将为大家讲述,如何在多个领域数据源之间,实现“诗画合一”。
文末,大讲堂特别提供文中提到所有文章的下载链接。

在多媒体大数据的背景下,我们迎接着挑战,也邂逅着机遇。纵观互联网的发展,从90年代的门户网站时代,到二十一世纪之初的搜索引擎时代、社交网络时代,直至当下的移动大媒体时代,多媒体智能计算研究被赋予了越来越大的科学、社会和商业价值。
我们未来媒体研究中心的定位是“多媒体大数据+人工智能”,用人工智能的技术分析处理多媒体大数据。

本次报告在对跨媒体研究总体介绍之后,将详细介绍video captioning和adversarial modality classifier的相关研究。
目前比较常见的多媒体数据包括文本数据、图像数据、视频数据以及音频数据。由于互联网的全面普及,多媒体大数据具备体量大、来源丰富、类型多样等特点,比如:

每一分钟,苹果用户下载大约51,000个应用程序,Skype用户拨打110,040个网络电话,Facebook用户要完成4,166,667个赞,YOUTUBE用户上传300小时的视频,Instagram用户对1736111张图片点赞,PINTEREST用户分享9722张图片。这意味着有海量的多媒体数据在源源不断地产生着,如果这些数据能够被充分地利用起来,将整体提高目前的人工智能水平,而如果使用不当,将影响公共安全。因此,多媒体大数据除了具备广泛的应用场景之外,还关乎国家经济、乃至社会安全。
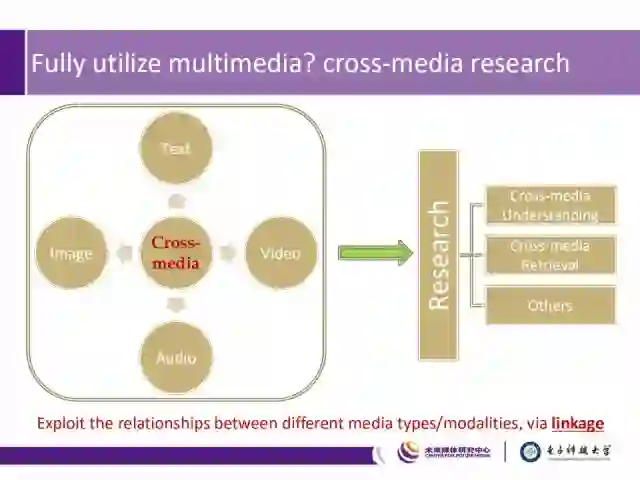
那么如何充分利用多媒体数据呢?因此衍生出了一个重要的研究方向:跨媒体研究,包括跨媒体理解、跨媒体检索以及时空大数据搜索等。而跨媒体研究的本质,主要是挖掘不同模态媒体数据之间的联系,以完成模态之间的迁移。

以机器人为例,一个机器人在运作的过程中,使用了视觉数据、语音数据以及传感器数据,而正是这些不同类型数据的协同,才赋予了机器人拟人化的能力。

而互联网上对同一个事件的描述,则会有不同来源的多种媒体数据。如图所示,对纽约飓风Sandy的事件描述,涵盖了视频数据、图像数据以及文本数据。
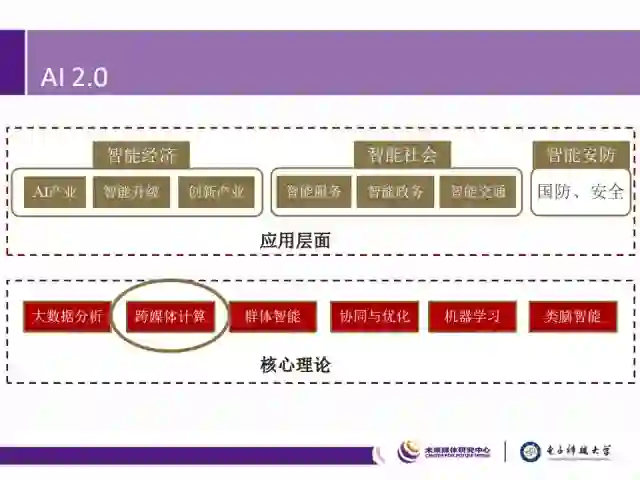
因此,跨媒体计算成为了AI 2.0时代的核心理论之一。
跨媒体理解:video captioning
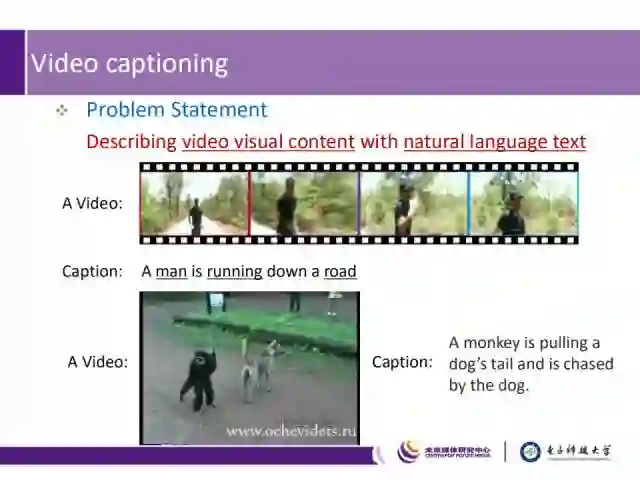
Video captioning是一种使用自然通顺的语言对视频进行描述,从而表达视频内容的技术。如上图所示。

其具备广泛的应用场景:
在医疗界,通过充分利用不同模态的信息并从中受益,可以用来帮助各种行为能力受限的人;
在工业界,不同模态数据的协同,可应用于无人系统,包括机器人、无人机、自动驾驶等;
在教育界,可应用于教育领域的辅助学习;
在新闻界,多种数据源信息的描述,还可提高新闻的可理解性;
在安全领域,由于安防数据的多样性,跨媒体研究将有助于对不同模态安防数据的全面分析,或可助力公共安全。
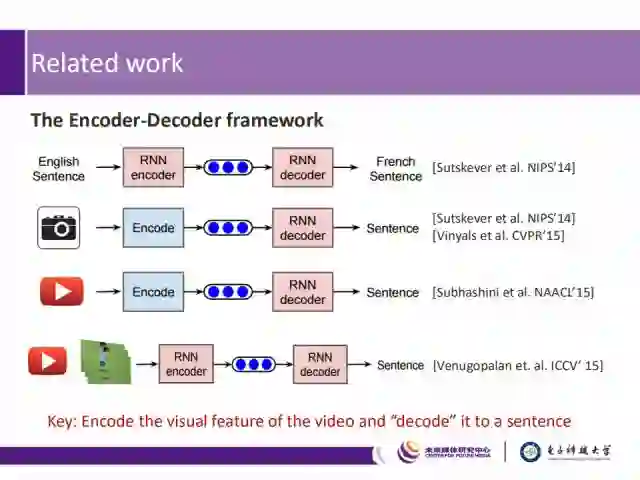
现有的跨媒体研究工作的关键在于:对视频的视觉特征进行有效的编码提取,并解码输出成语句。
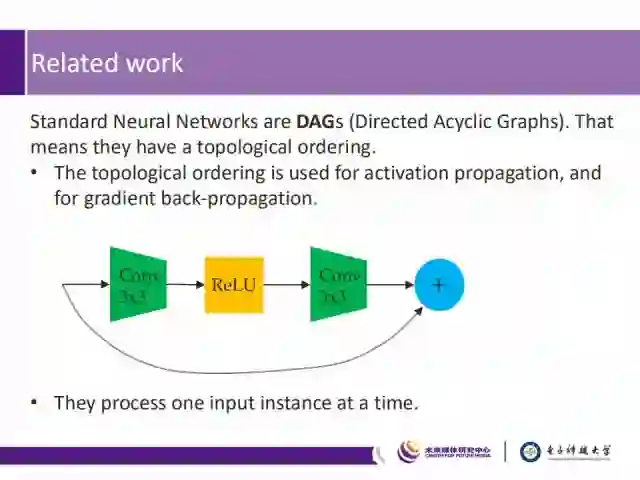
标准的神经网络皆是有向非循环图结构,采用拓扑顺序来进行前向传播、以及梯度反向传播,且单次只能有一个输入样例。
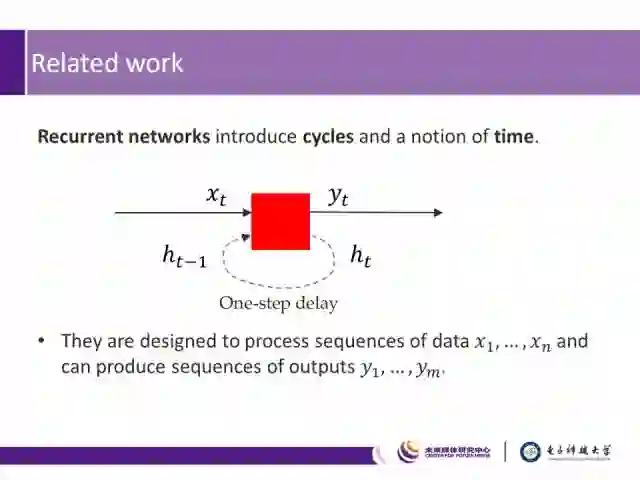
而循环神经网络引入了循环和时间概念,通过延迟的方式,解决了标准神经网络单次只能处理单条数据的问题,能够对多条数据序列同时进行处理。
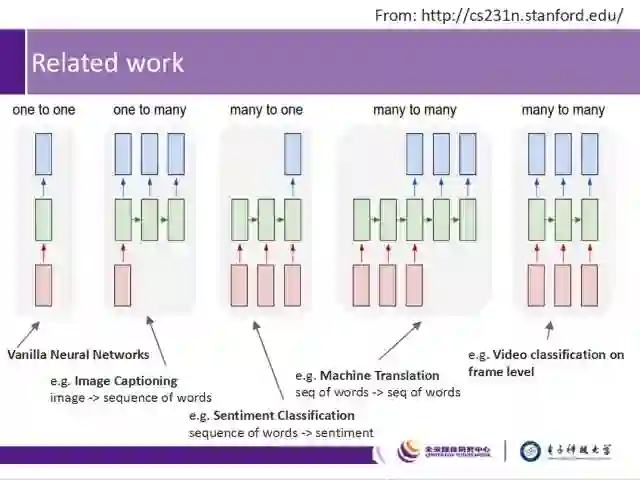
相关工作还有:
1)以Vanilla Neural Networks为例的一对一神经网络;
2)以Image Captioning为例的一对多神经网络,被用于从图像生成单词序列;
3)以sentiment Classification为例的多对一神经网络,被用于从单词序列生成Sentiment;
4)以机器翻译为例的多对多网络,被用于从单词序列生成单词序列;
5)以及,以frame level的视频分类为例的多对多网络。
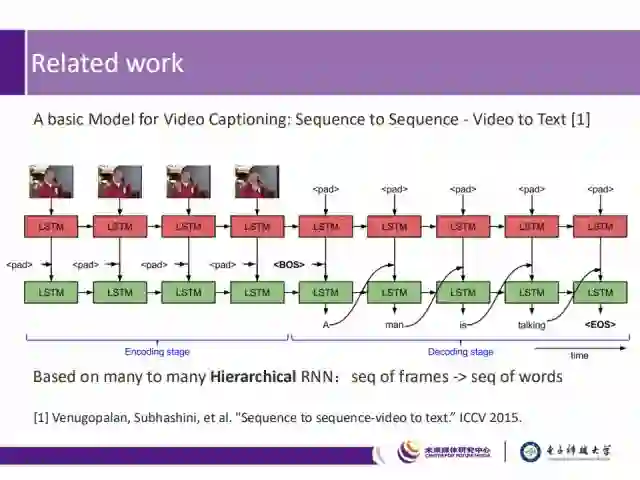
而video captioning领域的基础模型是ICCV 2015上的“Sequence to sequence-video to text”,是基于多对多的多层RNN网络来构建的。为了将视频中的事件解码为描述该事件的语句,这篇文章提出了一种双层LSTM方法,来学习如何表达视频帧序列。其中,上层LSTM(图中红色)用来建模输入视频序列的视觉特征,第二层LSTM(图中绿色)从文本输入以及视频序列的隐性特征,来建模最终的表达语言。图中<BOS>表示语句的开头,<EOS>表示句末的标签,<pad>表示该时间戳上输入为空。该模型可以同时学习视频帧的时序结构和生成语句的序列模型。
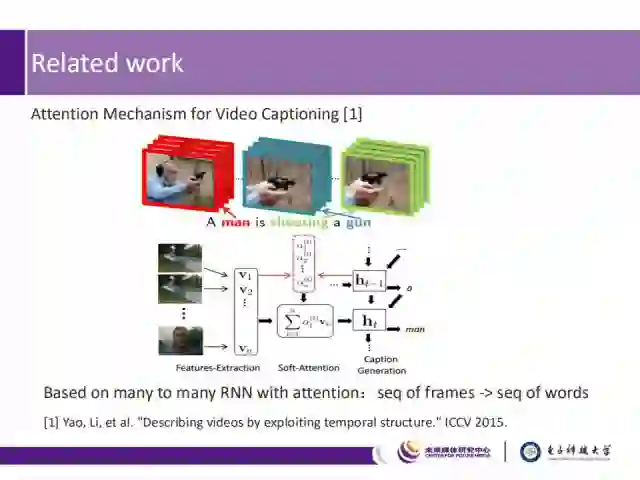
而在ICCV2015上的“Describing videos by exploiting temporal structure”,则为video captioning引入了注意力机制。在解码器中,通过采用动态的权重(也称为注意力权重),来对时序特征进行变换,然后利用变换后的特征和之前生成的单词来生成当前时刻的单词。其中,注意力权重反映了视频片段中每一帧的特征与上一时刻生成单词间的关联度。
如上图所示,通过对视频序列进行编码后,我们得到V(1), V(2), …, V(n)时序特征,根据解码器之前的状态及每一帧的特征V(i),获取到每一帧在当前时刻t时的注意力权重,然后采用为注意力权重加权的方式,对时序特征进行变换,最后根据这个特征和之前的状态来生成当前时刻的单词。

大多数现有的方法中,解码器为生成的所有单词都应用注意力机制,包括non-visual words(如“the”、“a”)。然而,事实上,对这些non-visual words使用自然语言模型已经能够很好地进行预测,为其强加注意力机制反而会误导解码器、并降低video captioning的整体性能。
针对这一问题,我们提出了一种层级LSTM框架(hLSTMat),它带有可调节功能的时间注意力机制,通过注意力机制选取一些特定的帧,并利用层级的LSTM来建模视频帧的低层视觉信息和高层语境信息,然后根据可调节的时间注意力机制,来选择解码是依赖于视觉信息还是语境信息。
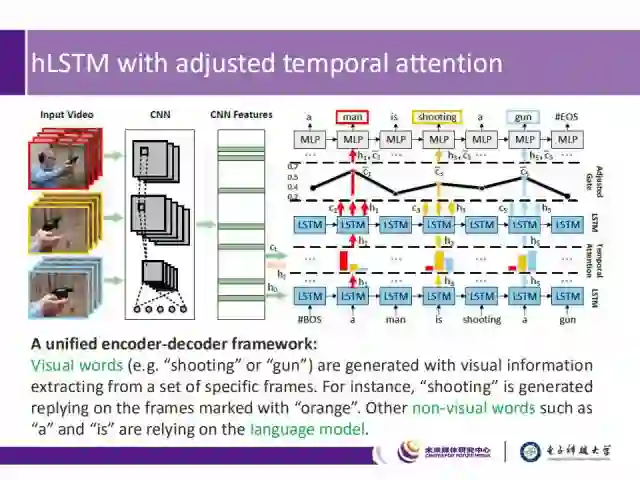
我们针对visual words和non-visual words,提出了一种统一的编码-解码框架:
1) 针对有实际意义的单词,从一系列特定视频帧中提取视觉信息,例如,shooting是从橘色的视频帧中生成的。
2) 而针对non-visual words,我们仍旧依赖于语言模型。
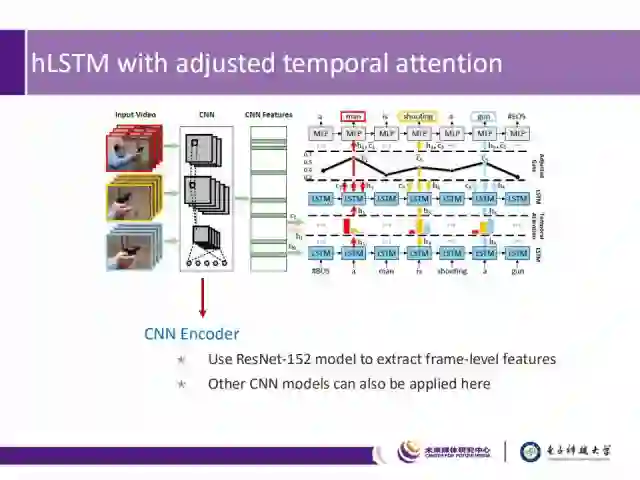
首先介绍CNN编码器:
这里使用ResNet-152模型来提取frame-level的特征,同样也可以使用其他CNN模型。
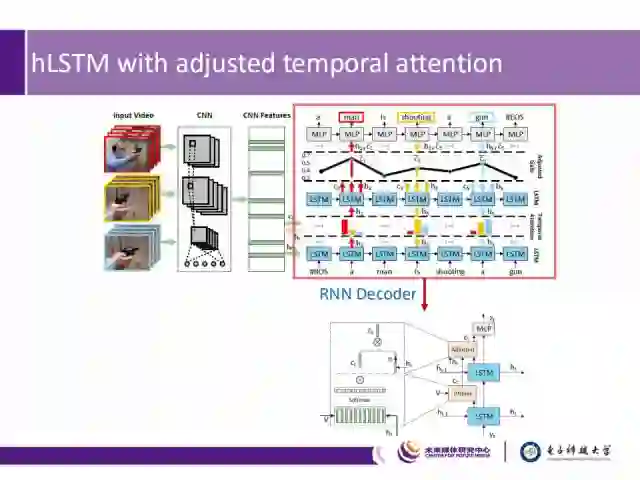
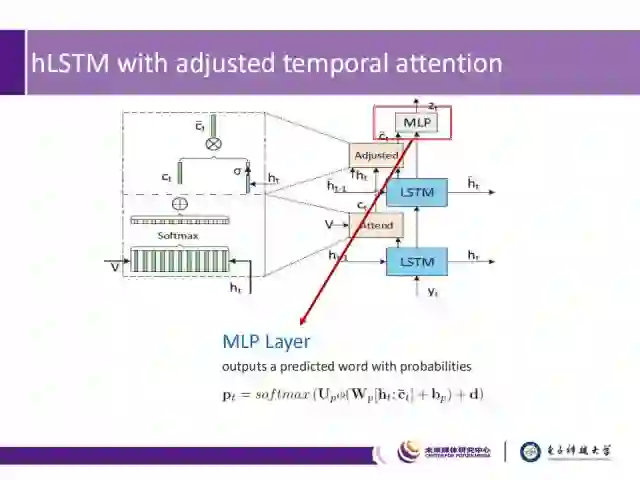
接下来我们介绍RNN解码器:其中包含两层LSTM、两种Attention以及一层MLP。如图中下部分所示:
1) 底层的LSTM可以高效地解码视觉特征;
2) 顶层的LSTM则主要挖掘语境信息;
3) 时间注意力机制(图中Attend)用于引导关注哪些重要的帧;
4) 可调节的时间注意力机制(图中Adjusted)用于决定采用视觉信息还是语境信息;
5) MLP层则用于最终的单词的预测。
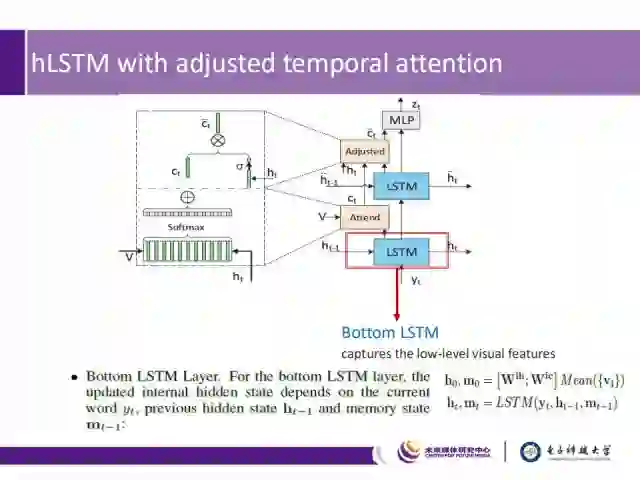
底层LSTM
它用来捕捉低层视觉特征。在该层中,时刻t的状态h_t、m_t根据当前的词语的特征y_t、前一时刻的隐含状态h_(t-1)和前一时刻的记忆m_(t-1)进行更新。初始状态为h_0、m_0。整个更新过程用公式表示为:
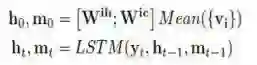
其中W^ih和W^ic是该层需要学习的参数,Mean(∙)表示对给定的视频段特征集{V_i}进行平均池化的操作。
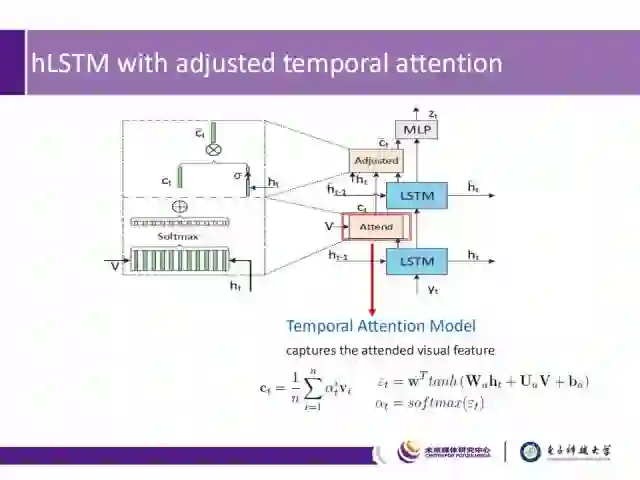
时间注意力机制层
用来引导关注哪些重要的帧,捕捉关注的视觉特征。在时刻t中,我们采用动态的权值对时序特征进行求和,得到的特征用来表示每个时刻下视频段的视觉特征。根据视频段特征V(V={V_i})及底层LSTM时刻t的隐含状态h_t,经由单层神经网络获取到未归一化的关联分数ε_t,并采用softmax函数来得到最终的动态权值。整个权值获取的过程用公式可表示为:
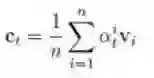
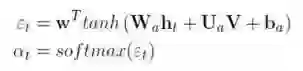
其中,W^T、W_a、U_a和b_a是需要学习的参数。

顶层LSTM
主要挖掘语境信息,捕捉视频段的高层语义特征。在该层中,时刻t的状态¯h_t、¯m_t根据底层LSTM的隐含状态h_t、前一时刻的隐含状态¯h_(t-1)和前一时刻的记忆¯m_(t-1)进行更新。同样地,整个更新过程用公式表示为:
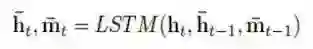
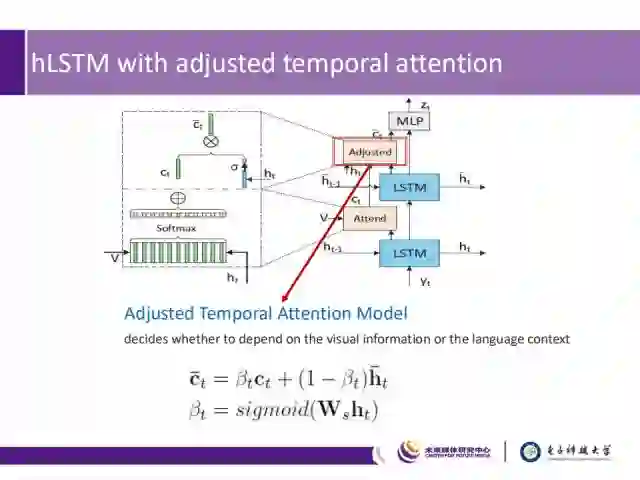
可调节的时间注意力机制层
用来决定采用视觉信息还是语境信息进行最后的单词生成。在该层中,通过添加校正门β_t来控制选取不同信息进行视觉单词和非视觉单词的预测。整个过程用公式表示如下:
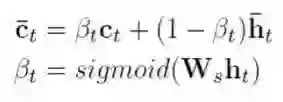
其中,W_s是需要学习的参数。
MLP层
用来输出单词预测的概率,获取最终生成的单词。具体公式如下:
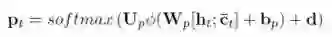

我们在MSVD数据集和MSR-VTT数据集上进行了测试,其中,MSVD数据集涵盖1970个视频序列,80,000个“视频-文本”描述对,我们将这1970个视频序列分为训练集(1200)、验证集(1000)、测试集(670)三组。MSR-VTT数据集包含10,000个网络视频序列,且每一段视频都有大约20句自然语句标注,共计200,000个“视频-文本”描述对。
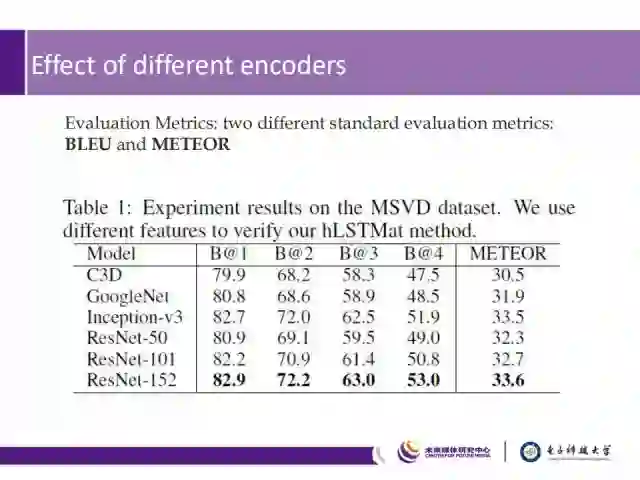
我们对编码器尝试了不同的网络,并使用BLEU和METEOR两个衡量指标对MSVD数据集进行测试,实验表明,在使用ResNet-152编码网络时,其性能最好。
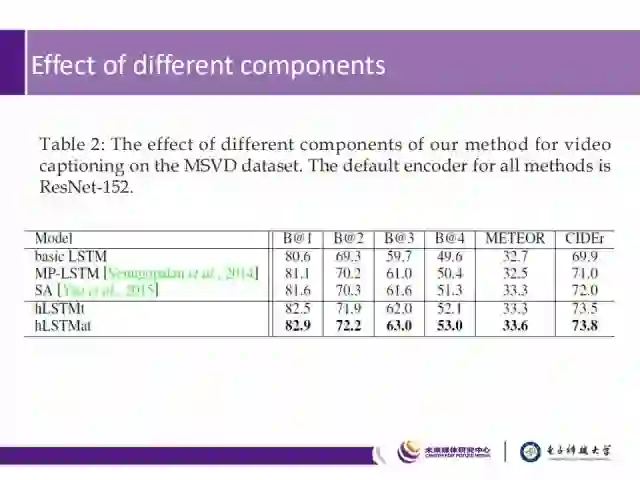
我们对模型也进行了对比,在MSVD dataset数据集上,使用ResNet-152网络进行测试,实验结果表明,hLSTMat和hLSTMt优于当时性能最好的SA和MP-LSTM,且hLSTMat优于hLSTMt,可以看出可调节的注意力机制能够提高video captioning的性能。
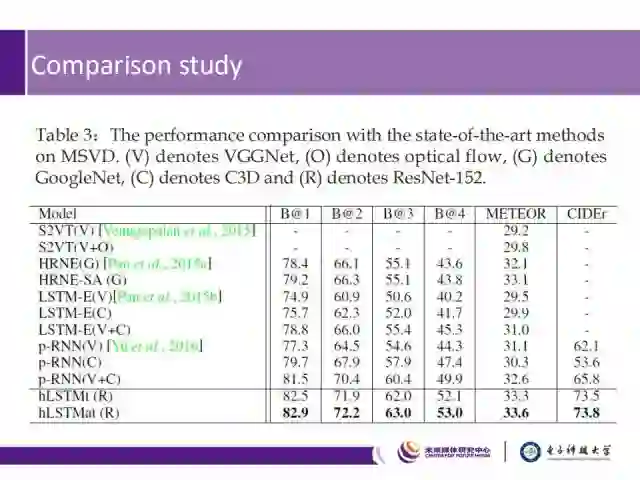
我们在MSVD数据集上和其他方法进行了对比,其中一些方法之使用了单一深度网络来生成视频特征,而其他一些(如S2VT,LSTM-E和p-RNN)则混合了多种网络产生的特征,当使用静态帧级特征时,我们得出如下结论:
1) 相对于只提取空间信息的p-RNN,我们的方法在B@4评价标准上有8.7%的提升,在METEOR上有2.5%的提升;
2) HRNE的层级结构减小了输入流的长度,并能够在更高层次上组合多种连续输入,提高了网络的学习能力,并使得模型能够编码更丰富的多粒度时间信息,实验表明我们的方法明显优于HRNE和HRNE-SA。
3) 表中的VGGNet(V)和GoogleNet(G)主要生成空间信息,而光流(O)和C3D(C)主要捕捉时间信息,从组合实验可以看出,将时间和空间信息结合考虑,能够提升网络的整体video captioning性能。

如图是在MSR-VTT数据集上的对比实验,结果也表明我们的方法取得了state-of-the-arts的性能。

上图展示了针对MSVD数据集中的人物、动物、场景描述效果,将我们的方法与groundtruth进行了对比。

跨媒体检索:adversarial modality classifier


网络上充斥着来自不同数据源的多模态多媒体数据;因此,亟需能够适应各种模态的信息检索系统,例如,在搜索“Dunkirk”电影时,应返回影评的相关文本数据、包含相关视频片段的视频数据、以及相关音频数据;而跨媒体检索指的是:给定一个模态的输入,来查找其他模态中与之最相近的匹配结果。
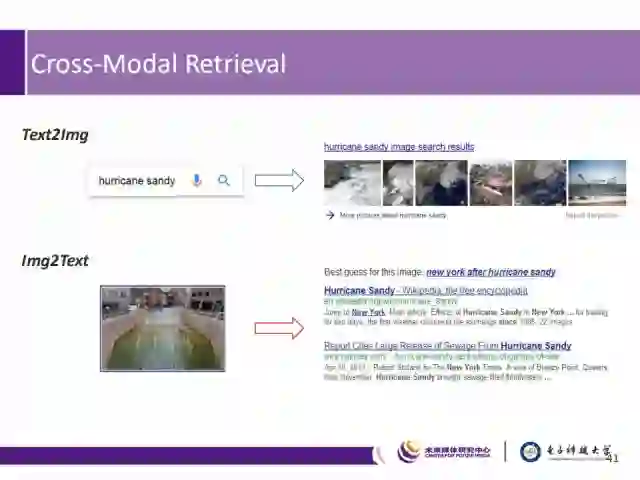
以上图中两个例子来说明跨媒体检索,如Text2Img和Img2Text。
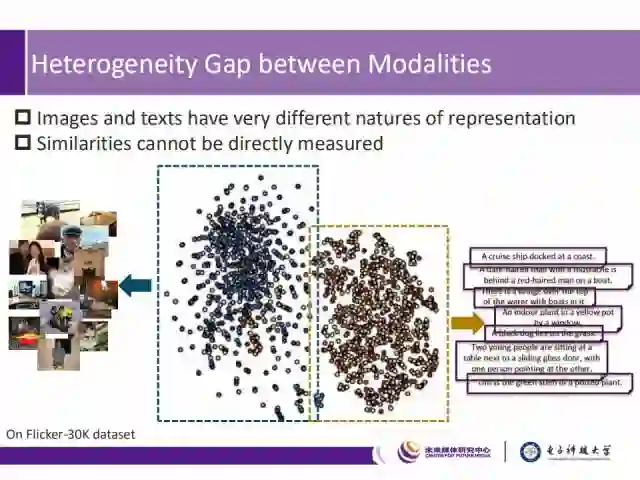
不同模态之间的数据及模型具备异质性,由图中特征空间的分布结果可以看出,图像和文本数据的特征表达具有本质性的差异,因而无法直接度量它们之间的相似度。
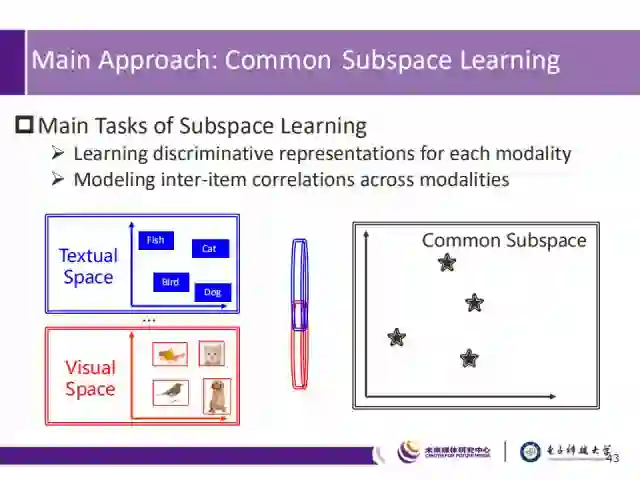
因此,常见的方法是公共子空间学习,为不同模态学习具有代表性的特征表示,同时,建模相同数据在不同模态之间的相关性。例如,图中以文本数据和视觉数据中的四种动物为例,寻找不同数据类型的同一输入在公共子空间中的相近落点,从而实现跨模态学习。

公共子空间学习衍生出了两个研究领域:特征提取以及相关性度量,而每个领域都有一系列研究方法。其中,特征提取分为浅层特征提取以及深度特征提取两类方法,而相关性度量则分为Pairwise和Rank-based两种方式。
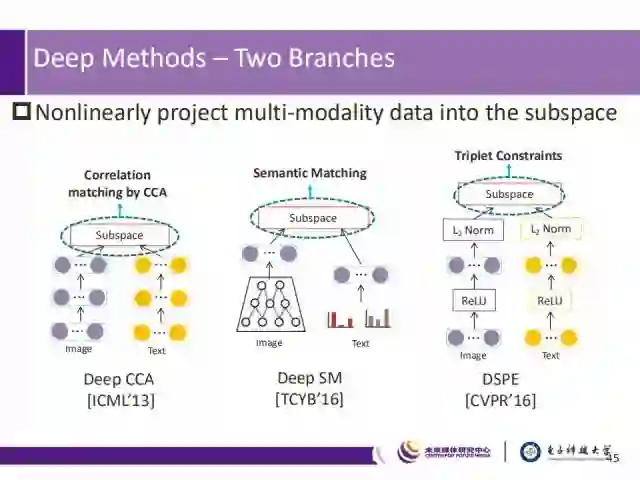
深度方法的两个分支
在跨媒体检索领域,常利用深度方法对不同模态的数据进行多层非线性特征提取,并将其映射到公共子空间,而后进行相似性度量。
而在相似性度量上,其存在两个分支:
1)从统计的角度出发,例如采用典型关联分析(Canonical Correlation Analysis,CCA)方法来获取不同模态数据的匹配关联程度。
2)从数据语义的角度来进行不同模态数据的匹配,在此基础上,通过加入三元组的限制条件,来提高匹配精度。遵循的原则为:在最小化同一语义数据在不同模态之间距离的同时,最大化不同模态不同语义数据之间的距离。

而现有的深度方法存在一定的局限性,只关注特征差异以及成对输入之间的相关性,很少考虑跨模态之间的不变性,但不得不承认,如果模态之间的偏差很大时,寻找跨模态之间的相关性是很难的。因此,最理想的情况是,寻找一种适应多模态的特征提取方式,也就是说,给定特征子空间中的某一点,使其并不能直接反映其来自哪一个模态,如图所示。
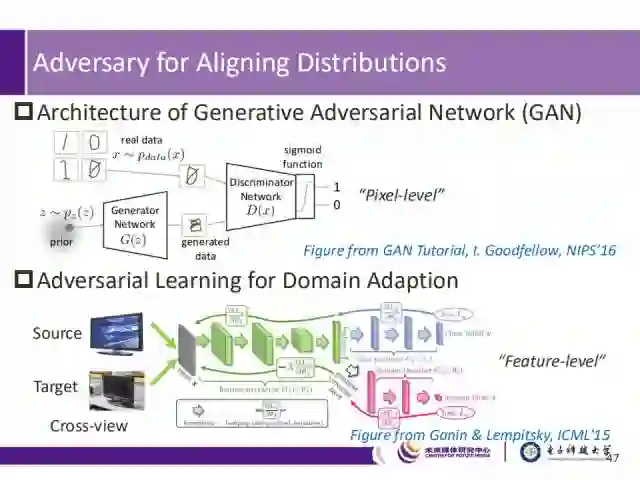
正是如此,我们可以在跨模态检索网络中引入对抗学习的思想。对抗学习被广泛应用于像素级别和特征级别的分布对齐中。如图中上半部分所示,在像素级别的分布对齐中,对抗学习主要用于真实图像和生成图像分布的对齐;此外,如图中下半部分所示,在特征级别的分布对齐中,对抗学习则用来生成Domain Adaption任务中与Domain无关的特征。
在ICML15的文章中,提出了一种实现方法:在常见的分类网络(绿色+蓝色)中加入域分类部分(粉色),该部分在训练的过程中,采用反转的梯度层进行反向传播梯度,因此保证了不同模态在特征子空间的分布相似。
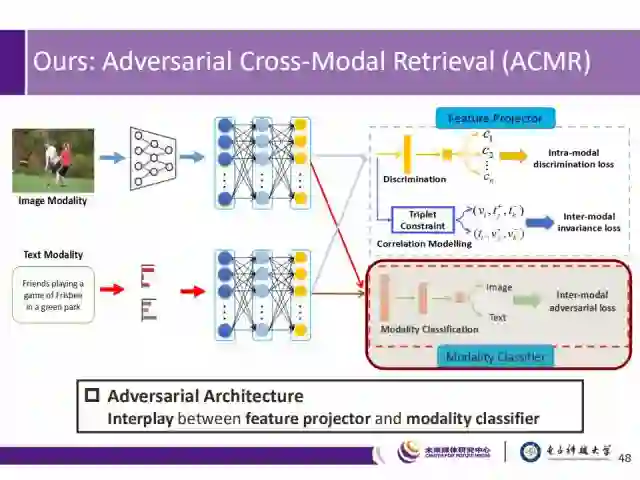
在此基础上,我们提出了一种对抗的跨模态检索(Adversarial Cross-Modal Retrieval,ACMR)方法,将对抗学习的思想应用于跨模态信息检索。整个算法流程如上图所示,它基于极大-极小的对抗机制,其中包含两个算法模块,其一是模态分类器,用来区分目标的模态,另一是特征生成器,用来生成能够适应不同模态的特征表达,以迷惑模态分类器。通过这两个模块的相互对抗,提高网络的综合性能。
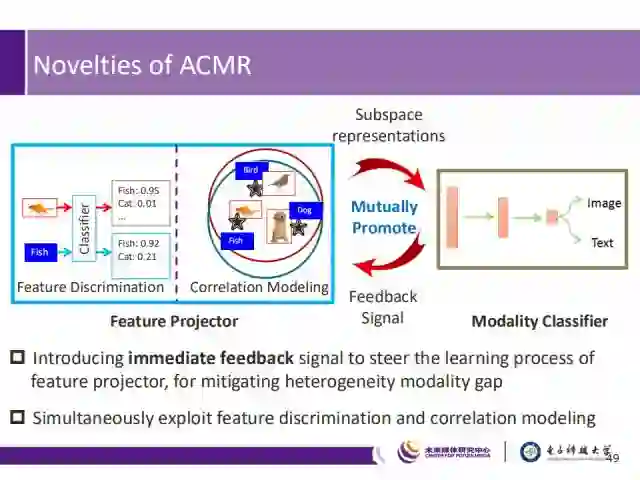
ACMR的创新点
1)为缓解不同模态间的差异,引入了立即的反馈信号,来引导特征生成器的学习过程,;
2)由于同时进行特征判别和相关性建模,能够生成更加有效的特征。
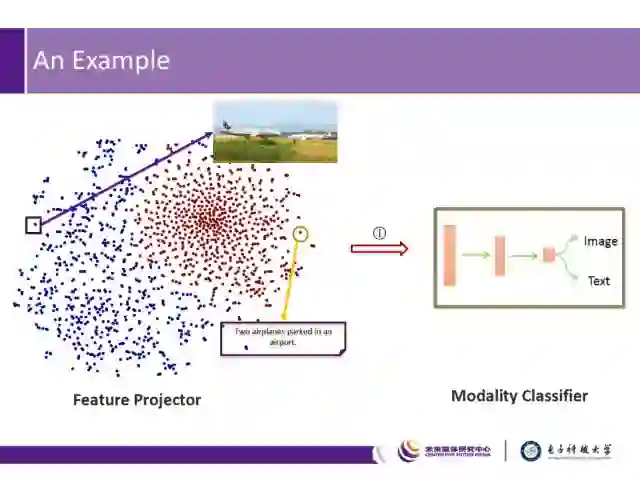
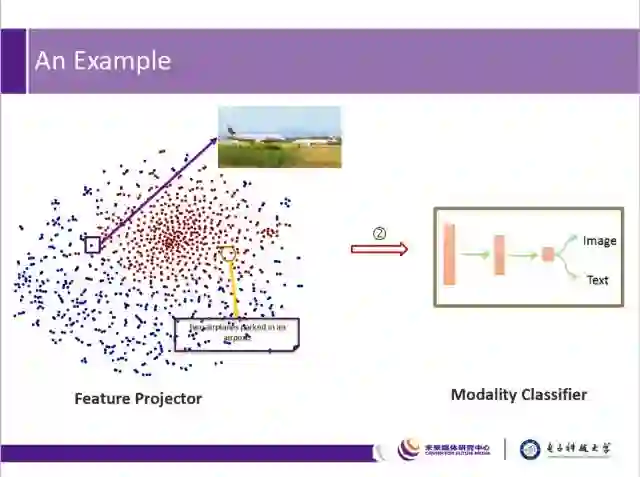
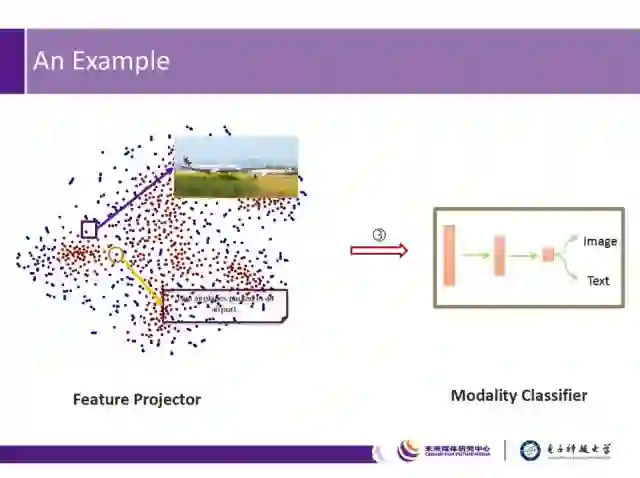
图中例子表明,通过特征生成器和模态分类器的不断对抗学习,对同一语义的图像和文本描述,将在特征空间中逐步接近,并最终学习到跨模态的特征表达。

在特征判别的学习过程中,为增强不同模态数据在子空间中特征的可表示性,采取以下两种方式:
1) 利用给定的语义标签来辅助监督;
2) 分类器根据投影到公共空间的特征,来输出数据属于某一类的概率,从而进行语义类别区分。
而在训练的过程中,采用softmax交叉熵损失。

相关性建模
其遵循的原则为:在最小化同一语义数据在不同模态之间距离的同时,最大化不同模态不同语义数据之间的距离。
为了能高效地建模跨模态数据间的相关性,我们采用三元组形式的目标函数并结合限制条件,来提高匹配精度,具体方法如下:
对于每一个目标数据,首先从图像-文本对中找到与之匹配的正例,然后依照跨模态邻接矩阵和模态内相似矩阵中寻找出与之最难的匹配反例,从而使得同语义数据的相关性排序要优于不同语义数据。

结合模态间相关损失、模态内判别损失以及正则项,特征生成器的最终损失函数如图所示。

正如之前描述的那样,通过梯度反转层,我们将特征生成器的损失和模态分类器的损失结合起来,通过最小-最大优化过程来同时更新两个部分的参数。
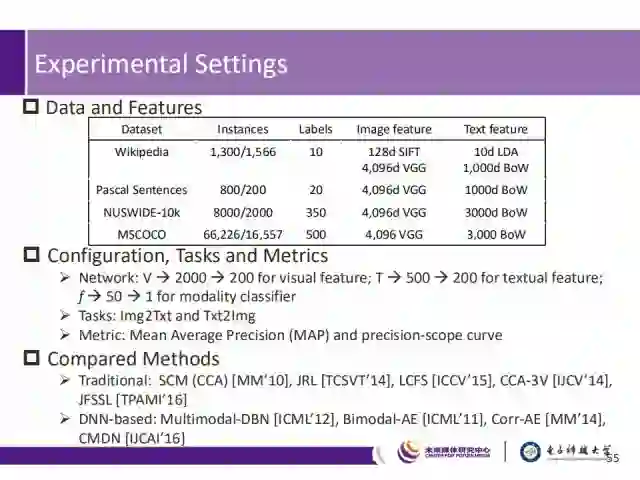
针对“图片到文本”、“文本到图片”两个检索任务,我们使用Wikipedia、Pascal Sentences、NUSWIDE-10k、MSCOCO四个数据集进行测试,数据及其特征详情见上表,表中“1300/1566”表示训练、测试的图片-文本对分别为1300和1566对。
为使得图片数据和文本数据可以映射到相同的特征空间,网络将图片CNN特征和文本BoW特征统一降到200维。对于模态分类器,设置3个全连接层,并将Softmax激活层添加在语义分类器和模态分类器的最后一层之后。这里采用MAP(平均准确率)和precision-scope曲线进行算法评估。
我们将所提的ACMR算法与5个传统算法(CAA、JRL、LCFS、CCA-3V、JFSSL)和4个基于深度神经网络的算法(Multimodal-DBN、Bimodal-AE、Corr-AE、CMDN)进行了比较。结果如下两张PPT所示。
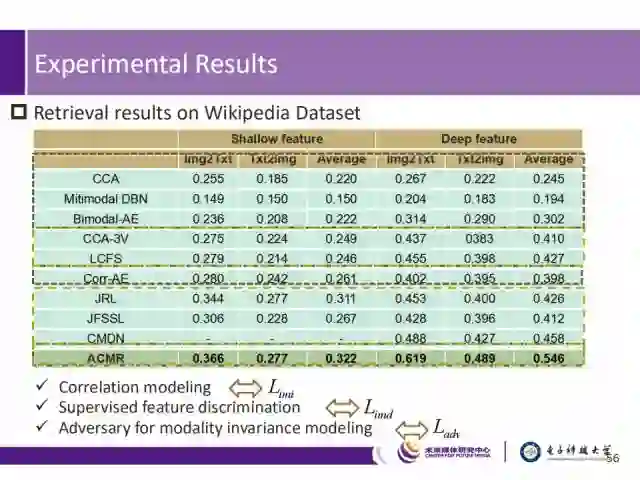
表中用于比较的CAA、Bimodal-AE、Corr-AE方法,使用了基于成对样本的相关性损失(correlation loss)来建模跨模态相似度,而有监督的CCA-3V, LCFS, JRL, JFSSL, CMDN方法,与ACMR一样使用了类标签信息。可以看出,在Wikipedia数据集上,ACMR方法效果最优。
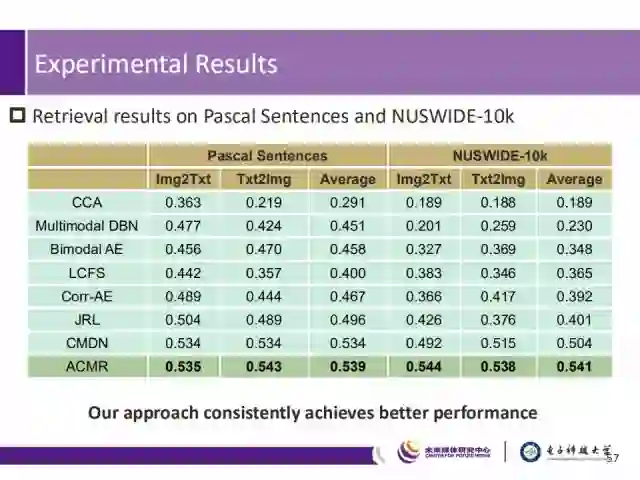
在Pascal、NUSWIDE-10K数据集上,可以看出我们的方法成为了state-of-the-arts。
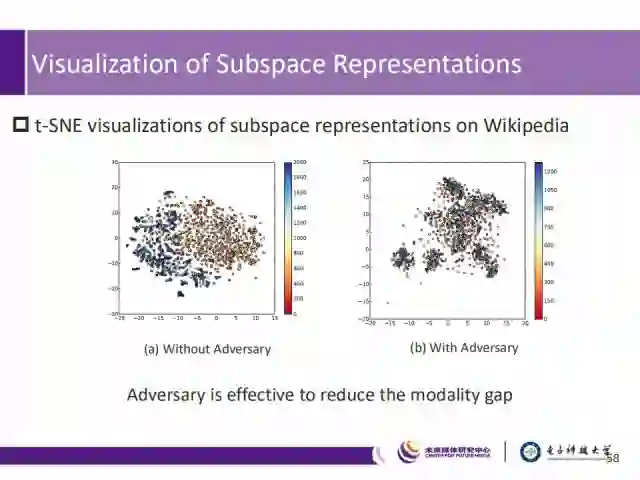
接下来我们用可视化的方式展示一下子空间特征的分布情况,可以看出,对抗学习具备缩小模态间差异以及混合不同模态间分布的能力。即在最小化同一语义数据在不同模态之间距离的同时,最大化不同模态不同语义数据之间的距离。

上图给出了一些在wikipedia数据集上的典型跨模态检索例子,比如输入一段关于战争的文本,相比Deep CAA算法,通过我们的方法检索,可以获取更合理的图片数据。

当然也会有一些错误的例子,如上图,“漂亮的金发女子”并未出现在待检索图片中,而针对文本“自行车”输入,一些图片中也未出现该类目标。qie这表明今后的工作将需致力于,在图片和文本中实现更加细粒度的检索。
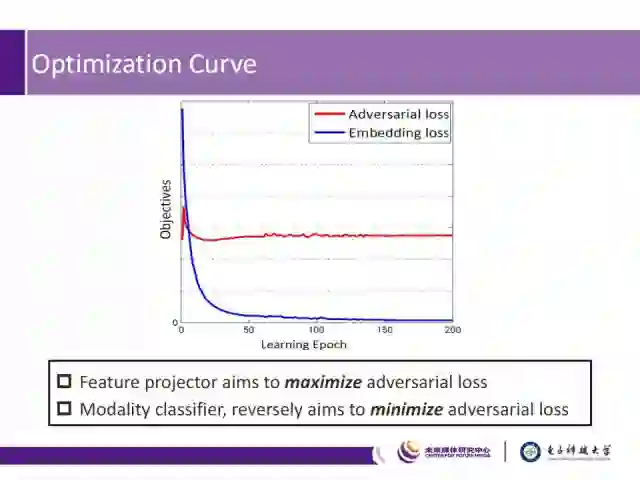
如图,通过对损失的可视化也可以看出,特征生成器旨在最大化两模态之间的对抗损失,相反,模态分类器则旨在最小化对抗损失,通过这两个模块之间的抗衡,最终提升网络的整体性能。

总结与展望:
本次报告中着重介绍了跨媒体理解与检索,图像、视频的captioning,以及对抗式跨媒体检索三方面技术,未来我们的研究方向将考虑如下三方面:
1. 对视觉及文本区域进行局部化
2. 利用哈希技术来辅助检索
3. 基于自然语言处理的实时多媒体交互。
文中申老师提到的文章下载链接为:
https://pan.baidu.com/s/1c3IeFlu
--end--

主编:袁基睿 编辑:杨茹茵
感谢中科视拓无人机视觉团队算法工程师刘壮,在撰稿过程中给予的技术支持。
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 ruyin712。
作者信息:
作者简介:

申恒涛,教授。他是国家、四川省“千人计划”特聘专家,电子科技大学计算机科学与工程学院院长,未来媒体研究中心主任、博导,澳大利亚昆士兰大学荣誉教授。他分别于2000年和2004年获得了新加坡国立大学计算机科学系一等荣誉学士和博士学位。随后加入昆士兰大学担任讲师,高级讲师,副教授,并于2011年底成为教授。他一直从事最前沿的计算机科学研究,研究方向包括多媒体搜索,计算机视觉,人工智能,和大数据管理。
申恒涛教授引领了国际高维复杂大数据索引的研究,在国际上率先实现了实时的近重复视频内容搜索系统。累计发表了200多篇高水平同行评审论文,其中120多篇发表在CCF A类会议或期刊上,如ACM Multimedia,CVPR,ICCV,AAAI,IJCAI,SIGMOD,VLDB,ICDE,TOIS,TIP,TPAMI,TKDE,VLDB Journal等, 并获得了7个国际会议最佳论文奖,包括A类会议ACM Multimedia 2017 最佳论文奖和ACM SIGIR 2017 最佳论文-Honorable Mention奖。 曾多次被很多国际会议或者研讨会邀请做大会报告。杰出的学术成就使其获得2010年澳洲计算研究与教育学会(Computing Research and Education Association of Australasia)授予的Chris Wallace Award,2012年澳大利亚研究理事会Future Fellowship,以及中华全国总工会颁发的2016年第六届“中国侨界贡献奖”。曾管理了14个科学研究项目,包括国家自然科学基金会的1个重点项目和澳大利亚研究理事会的8个项目。
申恒涛教授目前担任数据库领域重要期刊IEEE Transactions on Knowledge and Data Engineering编委,曾任IEEE Transactions on Multimedia和World Wide Web Journal 的客座编委。申恒涛教授担任过多个国际重要会议程序委员会联合主席,包括多媒体领域最高水平学术会议ACM Multimedia 2015;成功举办过数据库重要学术会议ICDE 2013和多媒体顶级会议ACM Multimedia 2015。也与世界许多知名大学建立了长期合作与互访关系,是昆士兰大学的荣誉教授(Honorary Professor),名古屋大学和新加坡国立大学的访问教授(Visiting Professor)。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站




