CVPR & AAAI 2020 | 人脸活体检测最新进展
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Fisher Yu余梓彤
https://zhuanlan.zhihu.com/p/114313640
本文已由原作者授权,不得擅自二次转载
今年活体检测(FAS)比较火热,这块的文章投稿和录用量剧增,AAAI录了2篇(上年0篇),CVPR也录了大概6篇(上年4篇)。本文主要讲解 奥卢大学Oulu, 西工大NPU,自动化所NLPR,Aibee,明略科学院等合作的3篇文章(一篇Oral,一篇Spotlight,一篇Poster)。
------------------------------------------
值得一提的是,基于 中心差分卷积 ( Central Difference Convolution CDC )[1] 和 对比深度损失 ( Contrastive Depth Loss )[2],该团队斩获CVPR2020 ChaLearn Face Anti-spoofing Attack Detection Challenge 活体检测国际大赛的 Track多模态 冠军 + Track单模态 亚军,具体代码也已开源:
https://github.com/ZitongYu/CDCN
一、CDCN [1], CVPR2020

看文章的组织架构,你会发现跟谷歌的MixNet有点类似,就是先设计新的搜索操作子,然后引进NAS里,取得更好的性能。也就是说,文章的重心是放在新型卷积操作的设计。
主要的贡献是:
1. 提出了中心差分卷积CDC,在基本不增加参数和运算量的前提下,大大提高了网络对细节信息的表征能力,及对环境变化的鲁棒性。
2. 第一个尝试用NAS来解决FAS问题,假定现有的架构的 repeated block 并不是最优的。
--------------------------------------
首先我们来看看Fig.1,使用普通卷积非常容易受到光照camera型号等影响,而使用CDC后网络更能捕捉到spoofing的本质特征,且不容易受到外部环境的影响。
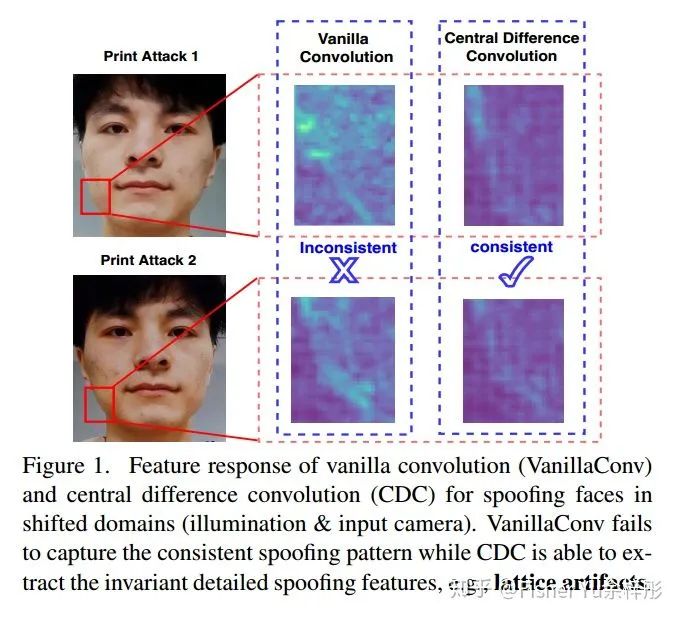
接着我们来看看CDC的公式:
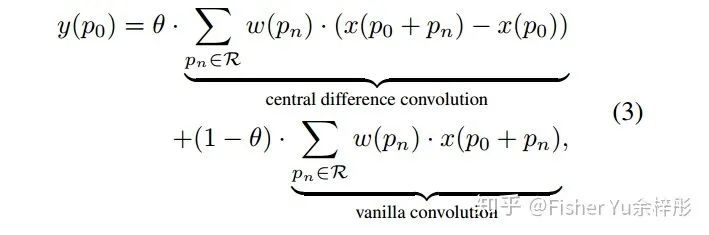
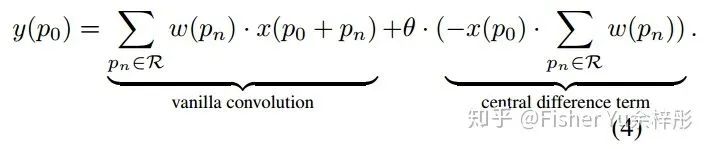








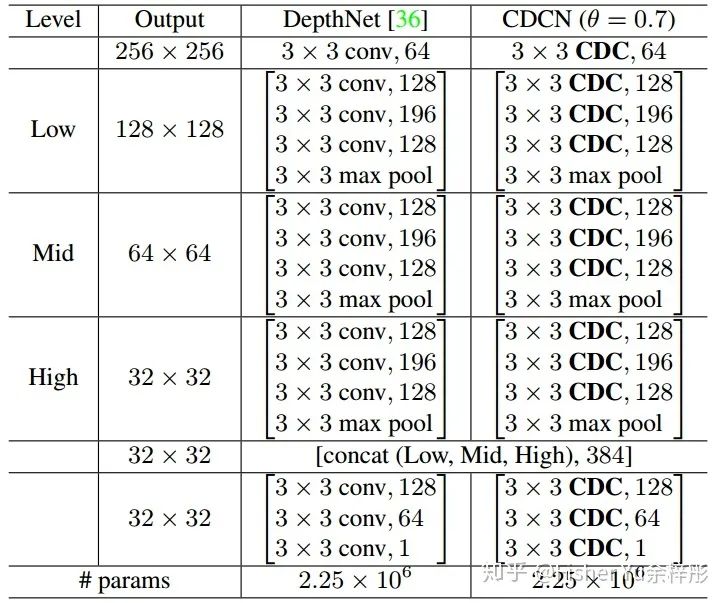
上图展示的是文章中用的 Baseline network [4],是18年CVPR中MSU提出来的,我们只用了其单帧伪深度预测的那部分结构。为了公平对比,我们不改变任何的网络架构,只将原始卷积全部换成CDC,结果如下图所示:
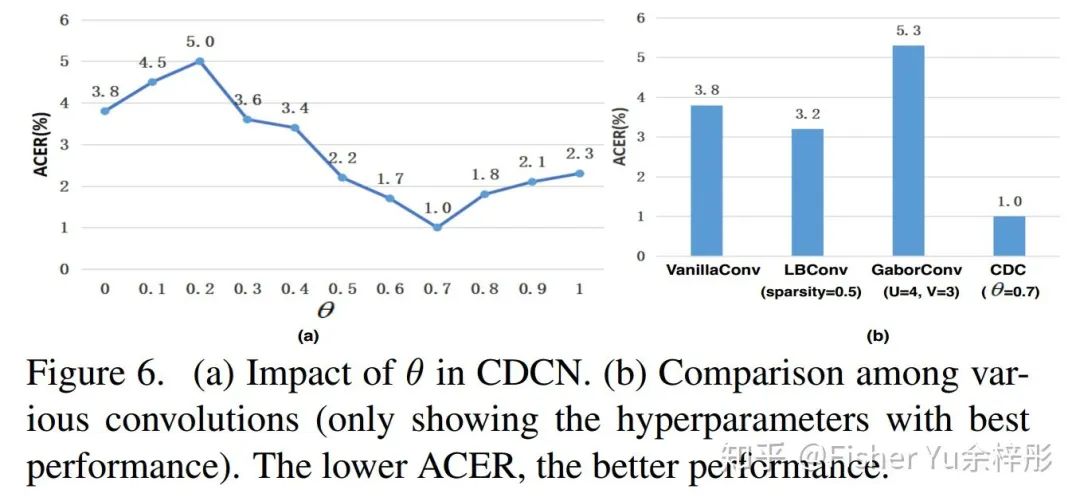
Fig. 6 (a) 可见,在OULU-NPU的 protocol-1上,baseline( 
另外我们也探讨了CDC与现有的 LBConv [5] 和 GaborConv [6] 的性能差异,如 Fig. 6 (b) 所示,CDC在活体检测任务中性能远超它们。
----------------------------------------------
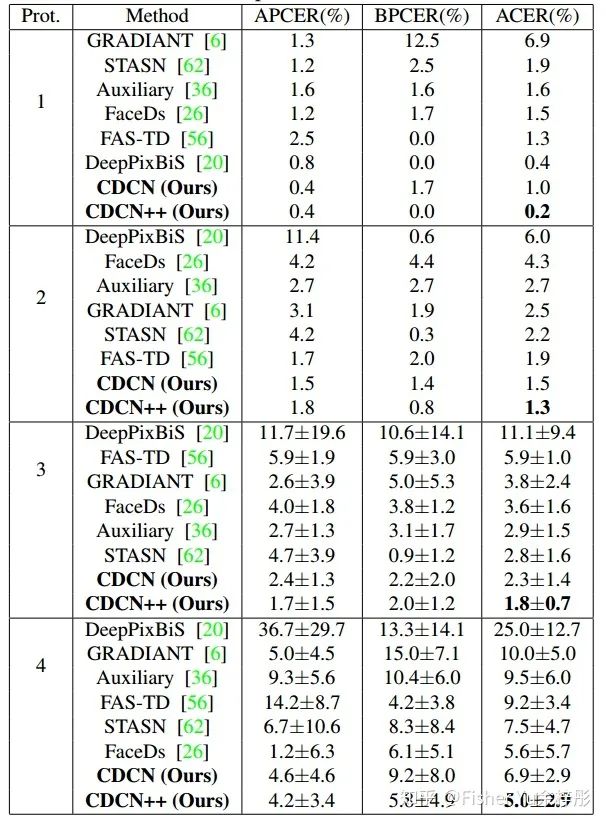
最后,我们把基于CDC的搜索空间,用PC-DARTS [7] 进行low-level, mid-level和high-level的cell架构搜索;在搜出来的backbone里再添加上多级注意力模块,进一步整合multi-level 特征,得到 CDCN++。贴个在 OULU-NPU 数据集上的实验结果供参考:
未来展望:
一方面,我们会继续对CDC进行拓展完善;另一方面,后续会开拓CDC在其他视觉任务的应用,比如 多媒体质量评价,人脸篡改检测FaceForencis 等等。当然,也希望未来的NAS search space里都把CDC考虑进去,毕竟普通vanilla卷积只是CDC的一种特例,使用CDC进行搜索,具有更大的可能性。
二、FAS-SGTD [2], CVPR2020 (Oral)
代码链接:
https://github.com/clks-wzz/FAS-SGTD

前几年的活体工作,对时空信息探索得较粗糙,基本都是ResBlock直接过去,然后接个LSTM,虽然都搞个CAM来可视化一下,但真的很难知道学到了什么,为什么会性能好。FAS-SGTD致力于从 空间Spatial 和 时间Temporal 层面来揭秘活体检测。
主要的贡献有:
1. 为了更好表征spatial信息,提出基于空间梯度幅值的 Residual Spatial Gradient Block (RSGB)。
2. 为了更好表征temporal信息,提出多级短长时时空传播模块 Spatio-Temporal Propagation Module (STPM)。
3. 为了让网络更好地学习到细节的spoofing patterns,提出了细粒度的监督损失:Contrastive Depth Loss (CDL) 。
4. 提出了新型数据集 Double-modal Anti-spoofing Dataset (DMAD) ,第一次对 真实传感器感知的Depth 和 PRNet产生的伪Depth 作为监督信号时的性能差异进行实验分析。
---------------------------------------------
我们先来看看经典的 Fig.1 和 Fig.2,形象地阐述了Living face 和 presentation attacks 的一些时空差异:
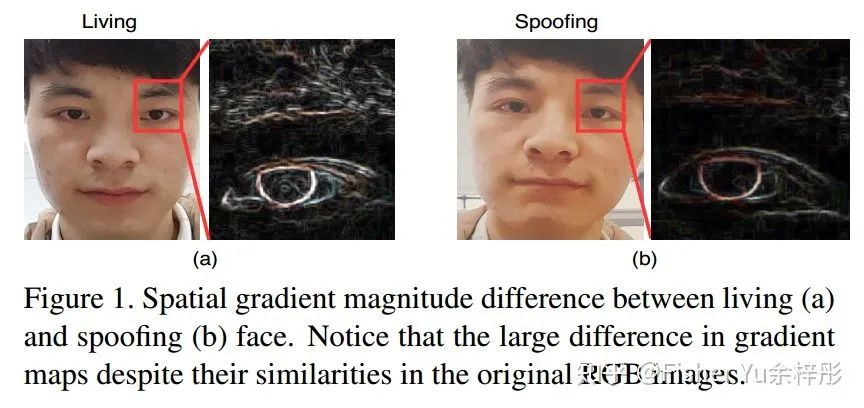
从上图经典 Sobel 算子出来的 spatial gradient magnitude map 可见,真实人脸具有更细致可靠的空间特征。
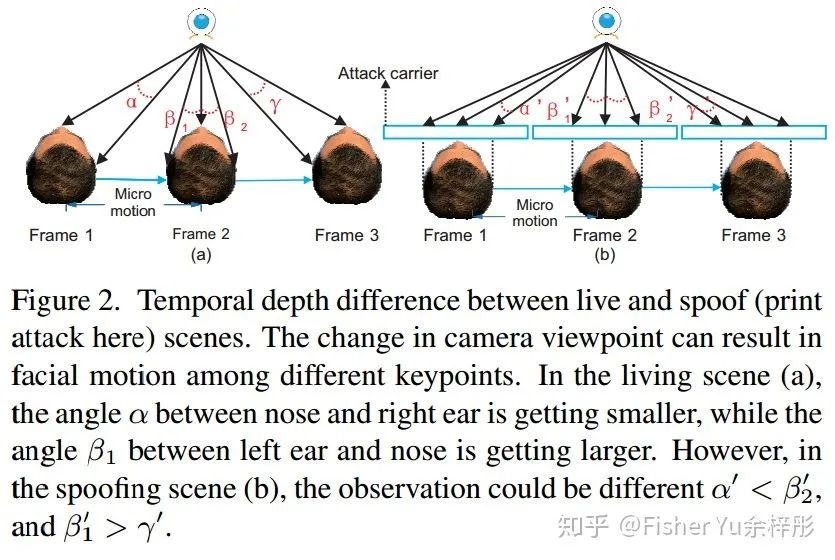
从上图简单的 Structure from motion 简单示意图可见,帧间的micro motion能够更好地重构出有用的立体信息,而真实人脸和假脸的立体信息也是有差异的。
----------------------------------------------
残差空间梯度模块 RSGB:
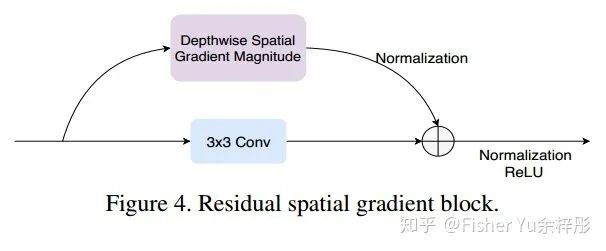
后面文章提交后才发现,跟 Kaiming 的这篇CVPR2019 "Feature Denoising for Improving Adversarial Robustness" [8] 想法有点撞车了。不过出发点是相反的,文[8]中是为了尽量不受 Adversarial 扰动的影响,所以在 feature map level 进行 denosing 残差操作;而 本文RSGB更关注局部细节信息,故在 feature map level 进行 sobel 残差操作。做计算机视觉任务的有趣地方就是,不同任务需要涉及 task-aware knowledge, 很难有像 machine learning一样通杀。
--------------------------------------------
多级短长时时空传播模块 STPM:
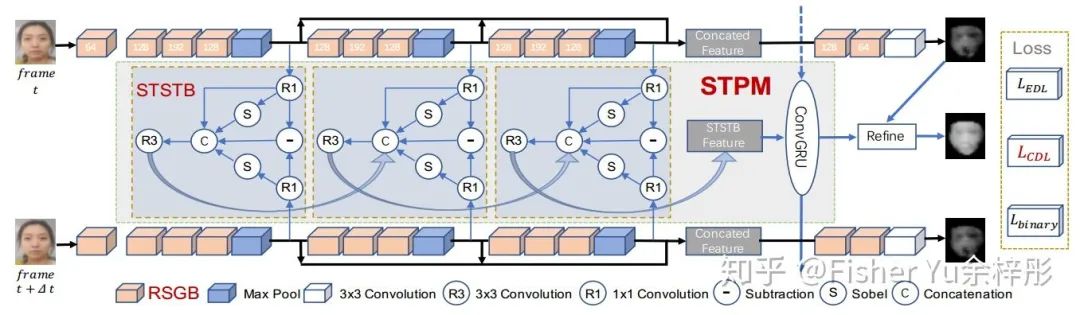
不同于OFF [9] 的是,我们考虑到了未来帧的spatial gradient features,这对多帧活体检测任务是非常重要的,具体关于STPM的消融实验请阅读原文。
---------------------------------------------
对比深度损失 CDL:
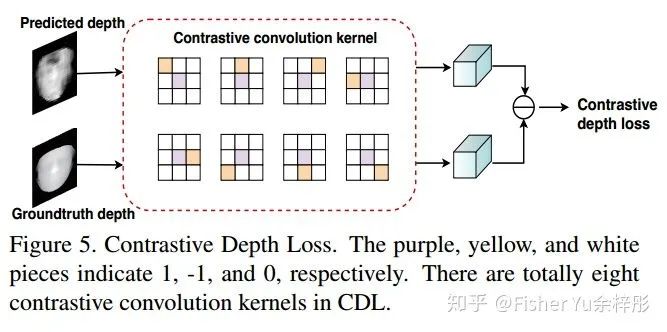
在Pixel to Pixel 的传统MSE loss基础上,加上 Local to Local 的CDL,能保证网络学到更细粒度的特征表达。
-------------------------------------------
双模态活体检测数据集 DMAD:

内含多种material材质,且包含多帧的真实depth信息,对于研究 Temporal Depth 很棒~
--------------------------------------------
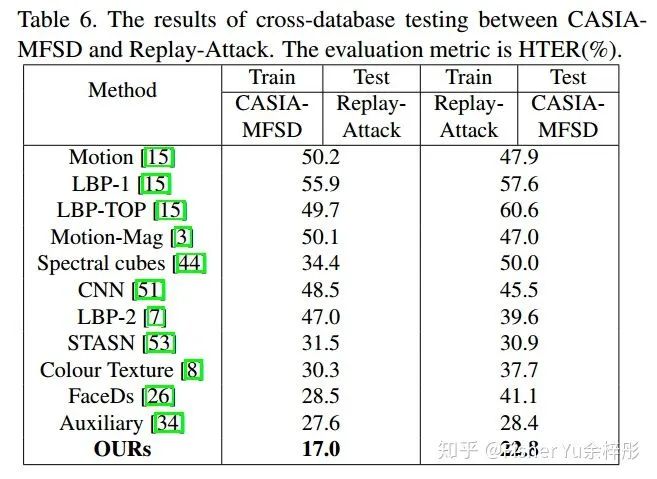
最后来贴个很challenging的跨数据集的实验结果,FAS-SGTD 非常鲁棒:
三、AIM-FAS [3], AAAI2020 (Spotlight)
代码及Protocol链接:
https://github.com/qyxqyx/AIM_FAS

本文的出发点是,由于市面上的 zero-shot 和 domain generalization 的FAS文章并不能全面地定义人脸防伪在实际应用中的问题。比如说,1) 现有的protocol没有充分对跨domain跨攻击跨模态进行组合定义; 2) 实际应用中一般可快速得到少量新场景的数据,应当充分利用这些few data来进行可靠地部署。
因此本文提出了:
1. 把FAS定义为一个 zero- & few-shot learning 的问题,并提出了 Adaptive Inner-update Meta Face Anti-Spoofing (AIM-FAS)。
2. 建立了新的 FAS benchmarks (OULU-ZF, Cross-ZF 和 SURF-ZF) 来进行zero- & few-shot 活体检测研究。
----------------------------------------------
先来看看什么是 zero- & few-shot FAS:
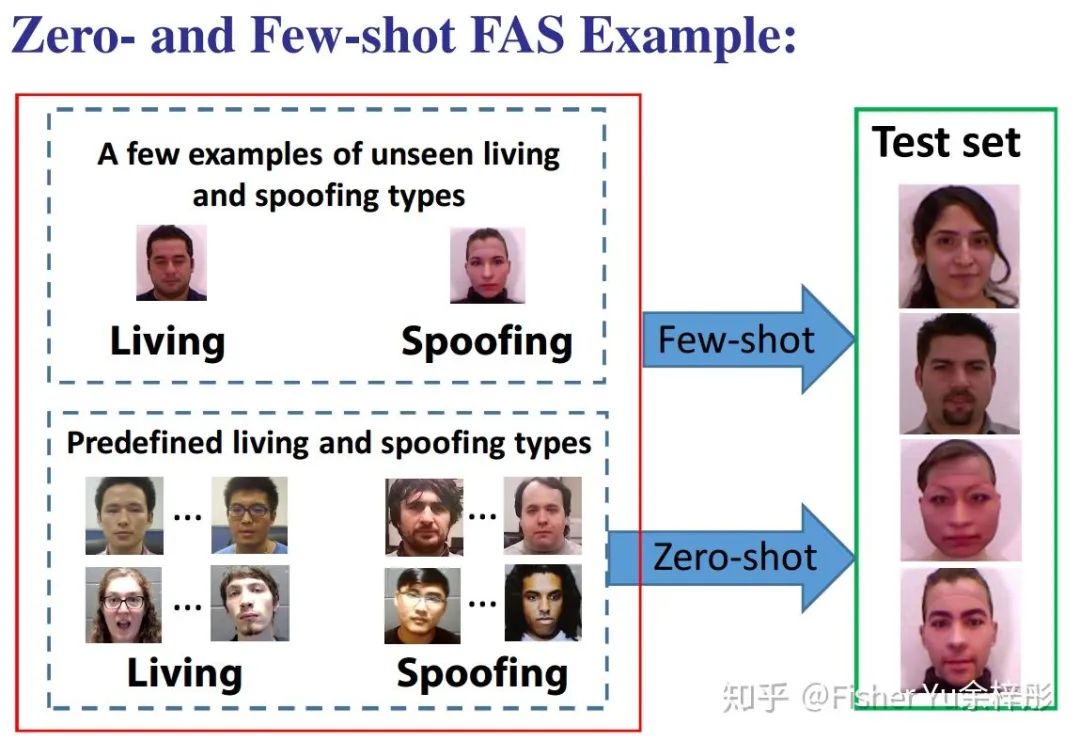
给定 Pre-defined 的Living 和 spoofing types 和 scenes 进行训练,直接在没见过的新场景(新攻击类型)下进行测试,这属于 Zero-shot;当引入少量新场景(新攻击类型)的数据进行训练,这时就变成 Few-shot。
--------------------------------------------
为了同时解决 zero- & few-shot FAS 问题,我们提出了能自适应在Inner-update阶段进行学习的meta learning方法,如下图所示:
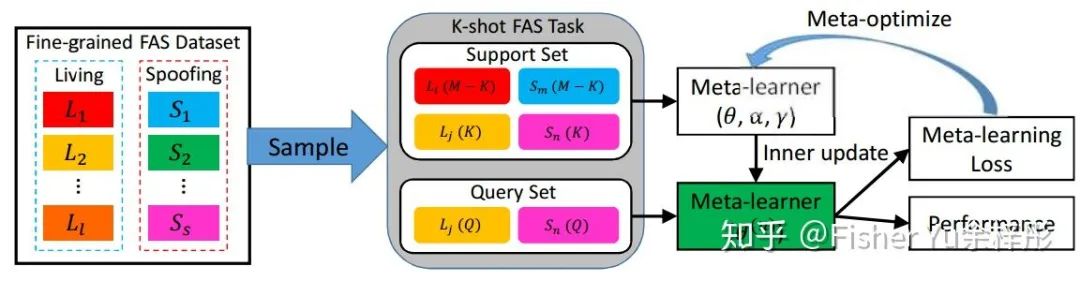
我们以更细粒度的方式重新组织了FAS的数据集,并以下面的步骤来产生 K-shot 任务:
1)从细粒度的FAS数据集中,采样 living 和 spoofing 各一类,作为 pre-defined living 类型 



2)对 pre-defined 的 living 或者 spoofing 类型,采样 

3)使用 


通过上述的方式,我们可以对 meta-learner 进行 zero- & few-shot 的 fusion training。这里的meta算法是基于经典的MAML,也是分为 Inner-update阶段 和 Optimizing阶段。
不同于MAML里的 Inner-update阶段的fixed学习率,我们让meta-learner根据不同的step进行自适应地调整学习率,这就是 Adaptive Inner-update Meta(AIM)的由来:

这里的 

---------------------------------------------
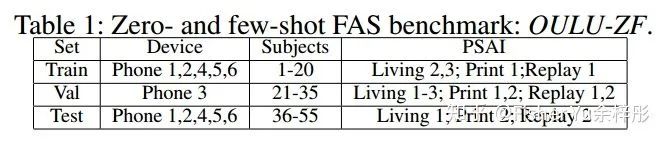
Zero- & few-shot FAS Benchmarks:
1) OULU-ZF:single domain
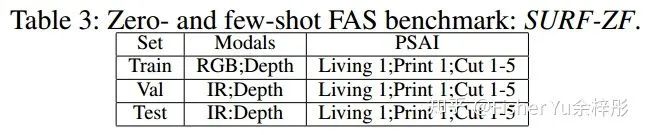
2) Cross-ZF: cross domain

3) SURF-ZF: cross modal
-----------------------------------------------
实验部分:
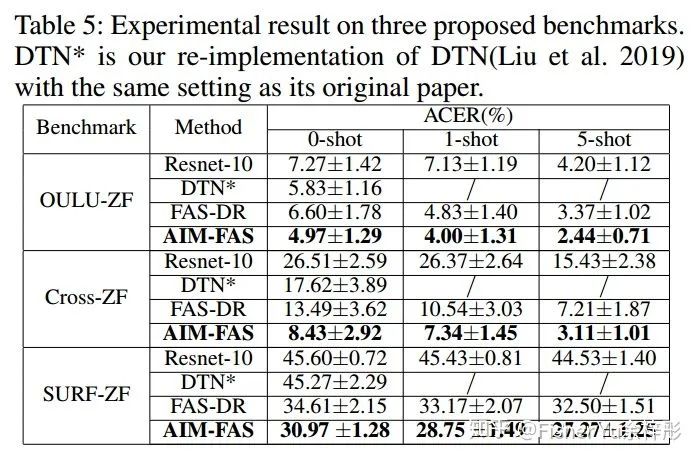
如Table 5所示,在提出的三个FAS benchmarks上,AIM-FAS能取得比之前专治zero-shot FAS的DTN [10] 更好的性能。注意到,SURF-ZF所有方法的性能都很低,可见跨模态测试是非常challenging。
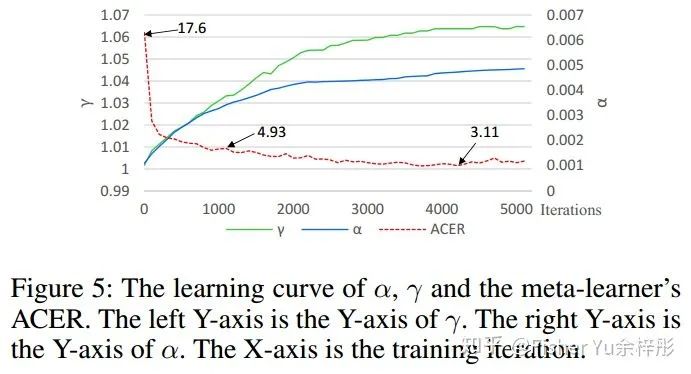
同时文中也给出来inner-update阶段的自适应参数曲线变化,随着学习step的增加,AIM-FAS倾向于使用更大的
-----------------------------------------------
Reference:
[1] Zitong Yu et al., Searching Central Difference Convolutional Networks for Face Anti-Spoofing, CVPR2020
[2] Zezheng Wang et al., Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing, CVPR2020 (Oral)
[3] Yunxiao Qin et al., Learning Meta Model for Zero- and Few-shot Face Anti-spoofing, AAAI2020 (Spotlight)
[4] Yaojie Liu et al., Learning deep models for face anti-spoofing: Binary or auxiliary supervision, CVPR2018
[5] Felix Juefei-Xu et al., Local binary convolutional neural networks, ICCV2017
[6] Shangzhen Luan et al., Gabor convolutional networks, TIP2018
[7] Yuhui Xu et al., PC-DARTS: Partial Channel Connections for Memory-Efficient Differentiable Architecture Search, ICLR2020
[8] Cihang Xie et al., Feature Denoising for Improving Adversarial Robustness, CVPR2019
[9] Shuyang Sun et al., Optical flow guided feature: A fast and robust motion representation for video action recognition, CVPR2018
[10] Yaojie Liu et al., Deep tree learning for zero-shot face anti-spoofing, CVPR2019
推荐阅读
2020年AI算法岗求职群来了(含准备攻略、面试经验、内推和学习资料等)
重磅!CVer-人脸相关 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-人脸相关 微信交流群,具体涵盖人脸检测、识别、关键点检测、表情识别、活体检测等人脸方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如活体检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


