CogLTX:将BERT应用于长文本

背景

解决这个问题的另一种思路是优化 Transformer 结构,这一条思路的工作有很多,例如 Longformer [1]、BlockBert、最近的 BigBird 等…… 但是这些工作通常只是将文本长度从 512 扩展几倍(基于现有的硬件条件),让 BERT 一次 “看到” 更多的文本;然而,人类并不需要如此强的瞬时阅读能力 —— 实际上人类同时在工作记忆里存储的元素通常只有 5-7 个 —— 也能阅读并理解长文本,那么人类是如何做到的呢?
认知中的工作记忆和调度
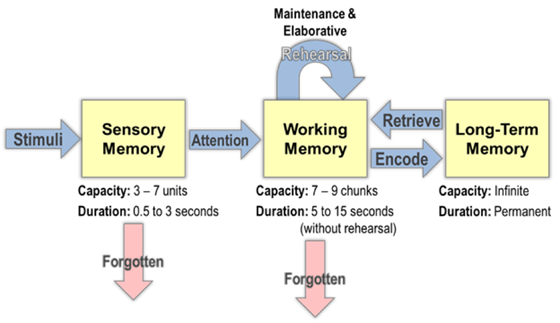
CogLTX 的工作流程
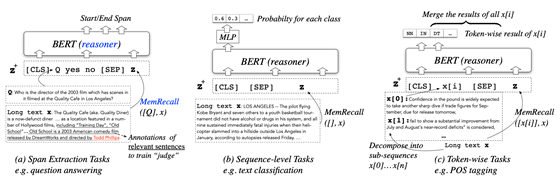
MemRecall 关键信息抽取
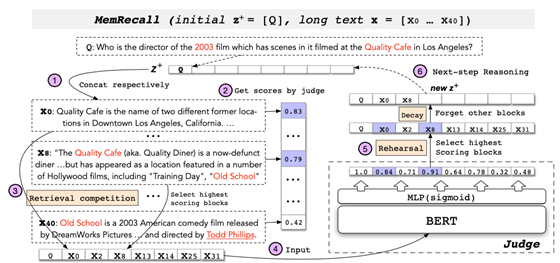
训练

实验
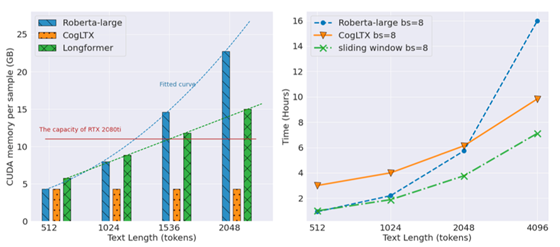
小结




登录查看更多
相关内容

Arxiv
5+阅读 · 2019年11月1日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
3+阅读 · 2019年2月11日
Arxiv
7+阅读 · 2019年2月3日
Arxiv
15+阅读 · 2018年10月11日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年11月1日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
3+阅读 · 2019年2月11日
Arxiv
7+阅读 · 2019年2月3日
Arxiv
15+阅读 · 2018年10月11日