Keras】基于SegNet和U-Net的遥感图像语义分割

-欢迎加入AI技术专家社群>>
上两个月参加了个比赛,做的是对遥感高清图像做语义分割,美其名曰“天空之眼”。这两周数据挖掘课期末project我们组选的课题也是遥感图像的语义分割,所以刚好又把前段时间做的成果重新整理和加强了一下,故写了这篇文章,记录一下用深度学习做遥感图像语义分割的完整流程以及一些好的思路和技巧。
数据集
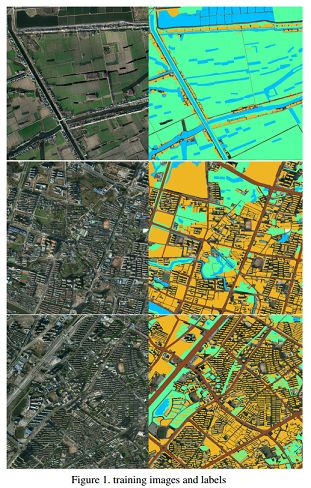
首先介绍一下数据,我们这次采用的数据集是CCF大数据比赛提供的数据(2015年中国南方某城市的高清遥感图像),这是一个小数据集,里面包含了5张带标注的大尺寸RGB遥感图像(尺寸范围从3000×3000到6000×6000),里面一共标注了4类物体,植被(标记1)、建筑(标记2)、水体(标记3)、道路(标记4)以及其他(标记0)。其中,耕地、林地、草地均归为植被类,为了更好地观察标注情况,我们将其中三幅训练图片可视化如下:蓝色-水体,黄色-房屋,绿色-植被,棕色-马路。更多数据介绍可以参看这里。
现在说一说我们的数据处理的步骤。我们现在拥有的是5张大尺寸的遥感图像,我们不能直接把这些图像送入网络进行训练,因为内存承受不了而且他们的尺寸也各不相同。因此,我们首先将他们做随机切割,即随机生成x,y坐标,然后抠出该坐标下256*256的小图,并做以下数据增强操作:
原图和label图都需要旋转:90度,180度,270度
原图和label图都需要做沿y轴的镜像操作
原图做模糊操作
原图做光照调整操作
原图做增加噪声操作(高斯噪声,椒盐噪声)
这里我没有采用Keras自带的数据增广函数,而是自己使用opencv编写了相应的增强函数。
img_w = 256 img_h = 256 image_sets = ['1.png','2.png','3.png','4.png','5.png']def gamma_transform(img, gamma): gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)] gamma_table = np.round(np.array(gamma_table)).astype(np.uint8) return cv2.LUT(img, gamma_table)def random_gamma_transform(img, gamma_vari): log_gamma_vari = np.log(gamma_vari) alpha = np.random.uniform(-log_gamma_vari, log_gamma_vari) gamma = np.exp(alpha) return gamma_transform(img, gamma) def rotate(xb,yb,angle): M_rotate = cv2.getRotationMatrix2D((img_w/2, img_h/2), angle, 1) xb = cv2.warpAffine(xb, M_rotate, (img_w, img_h)) yb = cv2.warpAffine(yb, M_rotate, (img_w, img_h)) return xb,yb def blur(img): img = cv2.blur(img, (3, 3)); return imgdef add_noise(img): for i in range(200): #添加点噪声 temp_x = np.random.randint(0,img.shape[0]) temp_y = np.random.randint(0,img.shape[1]) img[temp_x][temp_y] = 255 return img def data_augment(xb,yb): if np.random.random() < 0.25: xb,yb = rotate(xb,yb,90)
if np.random.random() < 0.25: xb,yb = rotate(xb,yb,180)
if np.random.random() < 0.25: xb,yb = rotate(xb,yb,270)
if np.random.random() < 0.25: xb = cv2.flip(xb, 1)
# flipcode > 0:沿y轴翻转 yb = cv2.flip(yb, 1) if np.random.random() < 0.25: xb = random_gamma_transform(xb,1.0) if np.random.random() < 0.25: xb = blur(xb) if np.random.random() < 0.2: xb = add_noise(xb) return xb,ybdef creat_dataset(image_num = 100000, mode = 'original'): print('creating dataset...') image_each = image_num / len(image_sets) g_count = 0 for i in tqdm(range(len(image_sets))): count = 0 src_img = cv2.imread('./data/src/' + image_sets[i])
# 3 channels label_img = cv2.imread('./data/label/' + image_sets[i],cv2.IMREAD_GRAYSCALE)
# single channel X_height,X_width,_ = src_img.shape
while count < image_each: random_width = random.randint(0, X_width - img_w - 1) random_height = random.randint(0, X_height - img_h - 1) src_roi = src_img[random_height: random_height + img_h, random_width: random_width + img_w,:] label_roi = label_img[random_height: random_height + img_h, random_width: random_width + img_w]
if mode == 'augment': src_roi,label_roi = data_augment(src_roi,label_roi) visualize = np.zeros((256,256)).astype(np.uint8) visualize = label_roi *50 cv2.imwrite(('./aug/train/visualize/%d.png' % g_count),visualize) cv2.imwrite(('./aug/train/src/%d.png' % g_count),src_roi) cv2.imwrite(('./aug/train/label/%d.png' % g_count),label_roi) count += 1 g_count += 1经过上面数据增强操作后,我们得到了较大的训练集:100000张256*256的图片。

卷积神经网络
面对这类图像语义分割的任务,我们可以选取的经典网络有很多,比如FCN,U-Net,SegNet,DeepLab,RefineNet,Mask Rcnn,Hed Net这些都是非常经典而且在很多比赛都广泛采用的网络架构。所以我们就可以从中选取一两个经典网络作为我们这个分割任务的解决方案。我们根据我们小组的情况,选取了U-Net和SegNet作为我们的主体网络进行实验。
SegNet
SegNet已经出来好几年了,这不是一个最新、效果最好的语义分割网络,但是它胜在网络结构清晰易懂,训练快速坑少,所以我们也采取它来做同样的任务。SegNet网络结构是编码器-解码器的结构,非常优雅,值得注意的是,SegNet做语义分割时通常在末端加入CRF模块做后处理,旨在进一步精修边缘的分割结果。有兴趣深究的可以看看这里
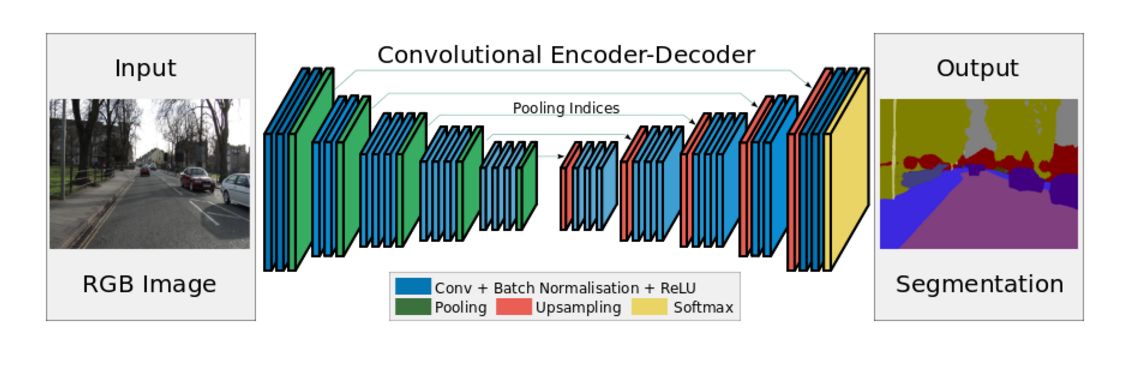
现在讲解代码部分,首先我们先定义好SegNet的网络结构。
def SegNet(): model = Sequential() #encoder model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(3,img_w,img_h),padding='same',activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2,2))) #(128,128) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(64,64) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(32,32) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(16,16) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) #(8,8) #decoder model.add(UpSampling2D(size=(2,2))) #(16,16) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(32,32) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(64,64) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(128,128) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(UpSampling2D(size=(2, 2))) #(256,256) model.add(Conv2D(64, (3, 3), strides=(1, 1), input_shape=(3,img_w, img_h), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(64, (3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(BatchNormalization()) model.add(Conv2D(n_label, (1, 1), strides=(1, 1), padding='same')) model.add(Reshape((n_label,img_w*img_h))) #axis=1和axis=2互换位置,等同于np.swapaxes(layer,1,2) model.add(Permute((2,1))) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy']) model.summary() return model 然后需要读入数据集。这里我们选择的验证集大小是训练集的0.25。
def get_train_val(val_rate = 0.25): train_url = [] train_set = [] val_set = []
for pic in os.listdir(filepath + 'src'): train_url.append(pic) random.shuffle(train_url) total_num = len(train_url) val_num = int(val_rate * total_num)
for i in range(len(train_url)):
if i < val_num: val_set.append(train_url[i]) else: train_set.append(train_url[i])
return train_set,val_set
# data for training
def generateData(batch_size,data=[]): #print 'generateData...' while True: train_data = [] train_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 #print (filepath + 'src/' + url) #img = load_img(filepath + 'src/' + url, target_size=(img_w, img_h)) img = load_img(filepath + 'src/' + url) img = img_to_array(img) # print img # print img.shape train_data.append(img) #label = load_img(filepath + 'label/' + url, target_size=(img_w, img_h),grayscale=True) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label).reshape((img_w * img_h,)) # print label.shape train_label.append(label) if batch % batch_size==0: #print 'get enough bacth!\n' train_data = np.array(train_data) train_label = np.array(train_label).flatten() train_label = labelencoder.transform(train_label) train_label = to_categorical(train_label, num_classes=n_label) train_label = train_label.reshape((batch_size,img_w * img_h,n_label)) yield (train_data,train_label) train_data = [] train_label = [] batch = 0
# data for validation
def generateValidData(batch_size,data=[]): #print 'generateValidData...' while True: valid_data = [] valid_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 #img = load_img(filepath + 'src/' + url, target_size=(img_w, img_h)) img = load_img(filepath + 'src/' + url) #print img #print (filepath + 'src/' + url) img = img_to_array(img) # print img.shape valid_data.append(img) #label = load_img(filepath + 'label/' + url, target_size=(img_w, img_h),grayscale=True) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label).reshape((img_w * img_h,)) # print label.shape valid_label.append(label) if batch % batch_size==0: valid_data = np.array(valid_data) valid_label = np.array(valid_label).flatten() valid_label = labelencoder.transform(valid_label) valid_label = to_categorical(valid_label, num_classes=n_label) valid_label = valid_label.reshape((batch_size,img_w * img_h,n_label)) yield (valid_data,valid_label) valid_data = [] valid_label = [] batch = 0 然后定义一下我们训练的过程,在这个任务上,我们把batch size定为16,epoch定为30,每次都存储最佳model(save_best_only=True),并且在训练结束时绘制loss/acc曲线,并存储起来。
def train(args): EPOCHS = 30 BS = 16 model = SegNet() modelcheck = ModelCheckpoint(args['model'],monitor='val_acc',save_best_only=True,mode='max') callable = [modelcheck] train_set,val_set = get_train_val() train_numb = len(train_set) valid_numb = len(val_set) print ("the number of train data is",train_numb) print ("the number of val data is",valid_numb) H = model.fit_generator(generator=generateData(BS,train_set),steps_per_epoch=train_numb//BS,epochs=EPOCHS,verbose=1, validation_data=generateValidData(BS,val_set),validation_steps=valid_numb//BS,callbacks=callable,max_q_size=1) # plot the training loss and accuracy plt.style.use("ggplot") plt.figure() N = EPOCHS plt.plot(np.arange(0, N), H.history["loss"], label="train_loss") plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss") plt.plot(np.arange(0, N), H.history["acc"], label="train_acc") plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc") plt.title("Training Loss and Accuracy on SegNet Satellite Seg") plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend(loc="lower left") plt.savefig(args["plot"])然后开始漫长的训练,训练时间接近3天,绘制出的loss/acc图如下:
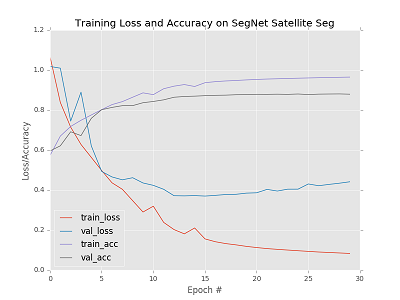
训练loss降到0.1左右,acc可以去到0.9,但是验证集的loss和acc都没那么好,貌似存在点问题。
先不管了,先看看预测结果吧。
这里需要思考一下怎么预测整张遥感图像。我们知道,我们训练模型时选择的图片输入是256×256,所以我们预测时也要采用256×256的图片尺寸送进模型预测。现在我们要考虑一个问题,我们该怎么将这些预测好的小图重新拼接成一个大图呢?这里给出一个最基础的方案:先给大图做padding 0操作,得到一副padding过的大图,同时我们也生成一个与该图一样大的全0图A,把图像的尺寸补齐为256的倍数,然后以256为步长切割大图,依次将小图送进模型预测,预测好的小图则放在A的相应位置上,依次进行,最终得到预测好的整张大图(即A),再做图像切割,切割成原先图片的尺寸,完成整个预测流程。
def predict(args): # load the trained convolutional neural network print("[INFO] loading network...") model = load_model(args["model"]) stride = args['stride']
for n in range(len(TEST_SET)): path = TEST_SET[n]
#load the image image = cv2.imread('./test/' + path)
# pre-process the image for classification #image = image.astype("float") / 255.0 #image = img_to_array(image) h,w,_ = image.shape padding_h = (h//stride + 1) * stride padding_w = (w//stride + 1) * stride padding_img = np.zeros((padding_h,padding_w,3),dtype=np.uint8) padding_img[0:h,0:w,:] = image[:,:,:] padding_img = padding_img.astype("float") / 255.0 padding_img = img_to_array(padding_img)
print 'src:',padding_img.shape mask_whole = np.zeros((padding_h,padding_w),dtype=np.uint8)
for i in range(padding_h//stride):
for j in range(padding_w//stride): crop = padding_img[:3,i*stride:i*stride+image_size,j*stride:j*stride+image_size] _,ch,cw = crop.shape
if ch != 256 or cw != 256:
print 'invalid size!' continue crop = np.expand_dims(crop, axis=0) #print 'crop:',crop.shape pred = model.predict_classes(crop,verbose=2) pred = labelencoder.inverse_transform(pred[0]) #print (np.unique(pred)) pred = pred.reshape((256,256)).astype(np.uint8) #print 'pred:',pred.shape mask_whole[i*stride:i*stride+image_size,j*stride:j*stride+image_size] = pred[:,:] cv2.imwrite('./predict/pre'+str(n+1)+'.png',mask_whole[0:h,0:w])预测的效果图如下:

一眼看去,效果真的不错,但是仔细看一下,就会发现有个很大的问题:拼接痕迹过于明显了!那怎么解决这类边缘问题呢?很直接的想法就是缩小切割时的滑动步伐,比如我们把切割步伐改为128,那么拼接时就会有一般的图像发生重叠,这样做可以尽可能地减少拼接痕迹。
U-Net
对于这个语义分割任务,我们毫不犹豫地选择了U-Net作为我们的方案,原因很简单,我们参考很多类似的遥感图像分割比赛的资料,绝大多数获奖的选手使用的都是U-Net模型。在这么多的好评下,我们选择U-Net也就毫无疑问了。
U-Net有很多优点,最大卖点就是它可以在小数据集上也能train出一个好的模型,这个优点对于我们这个任务来说真的非常适合。而且,U-Net在训练速度上也是非常快的,这对于需要短时间就得出结果的期末project来说也是非常合适。U-Net在网络架构上还是非常优雅的,整个呈现U形,故起名U-Net。这里不打算详细介绍U-Net结构,有兴趣的深究的可以看看论文。
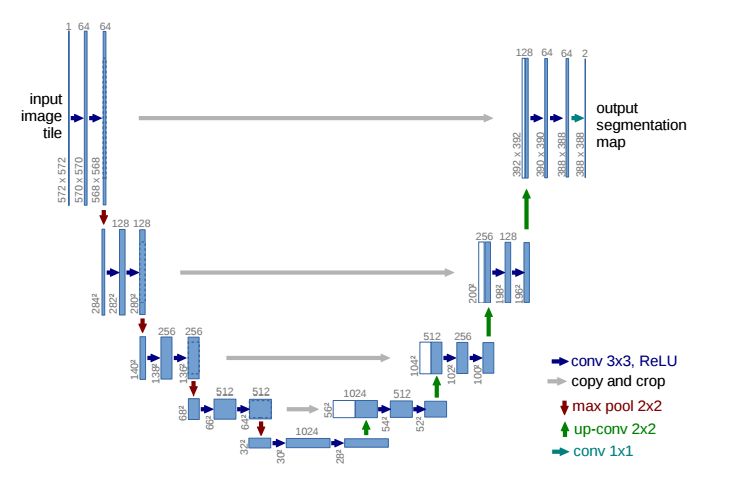
现在开始谈谈代码细节。首先我们定义一下U-Net的网络结构,这里用的deep learning框架还是Keras。
注意到,我们这里训练的模型是一个多分类模型,其实更好的做法是,训练一个二分类模型(使用二分类的标签),对每一类物体进行预测,得到4张预测图,再做预测图叠加,合并成一张完整的包含4类的预测图,这个策略在效果上肯定好于一个直接4分类的模型。所以,U-Net这边我们采取的思路就是对于每一类的分类都训练一个二分类模型,最后再将每一类的预测结果组合成一个四分类的结果。
定义U-Net结构,注意了,这里的loss function我们选了binary_crossentropy,因为我们要训练的是二分类模型。
def unet(): inputs = Input((3, img_w, img_h)) conv1 = Conv2D(32, (3, 3), activation="relu", padding="same")(inputs) conv1 = Conv2D(32, (3, 3), activation="relu", padding="same")(conv1) pool1 = MaxPooling2D(pool_size=(2, 2))(conv1) conv2 = Conv2D(64, (3, 3), activation="relu", padding="same")(pool1) conv2 = Conv2D(64, (3, 3), activation="relu", padding="same")(conv2) pool2 = MaxPooling2D(pool_size=(2, 2))(conv2) conv3 = Conv2D(128, (3, 3), activation="relu", padding="same")(pool2) conv3 = Conv2D(128, (3, 3), activation="relu", padding="same")(conv3) pool3 = MaxPooling2D(pool_size=(2, 2))(conv3) conv4 = Conv2D(256, (3, 3), activation="relu", padding="same")(pool3) conv4 = Conv2D(256, (3, 3), activation="relu", padding="same")(conv4) pool4 = MaxPooling2D(pool_size=(2, 2))(conv4) conv5 = Conv2D(512, (3, 3), activation="relu", padding="same")(pool4) conv5 = Conv2D(512, (3, 3), activation="relu", padding="same")(conv5) up6 = concatenate([UpSampling2D(size=(2, 2))(conv5), conv4], axis=1) conv6 = Conv2D(256, (3, 3), activation="relu", padding="same")(up6) conv6 = Conv2D(256, (3, 3), activation="relu", padding="same")(conv6) up7 = concatenate([UpSampling2D(size=(2, 2))(conv6), conv3], axis=1) conv7 = Conv2D(128, (3, 3), activation="relu", padding="same")(up7) conv7 = Conv2D(128, (3, 3), activation="relu", padding="same")(conv7) up8 = concatenate([UpSampling2D(size=(2, 2))(conv7), conv2], axis=1) conv8 = Conv2D(64, (3, 3), activation="relu", padding="same")(up8) conv8 = Conv2D(64, (3, 3), activation="relu", padding="same")(conv8) up9 = concatenate([UpSampling2D(size=(2, 2))(conv8), conv1], axis=1) conv9 = Conv2D(32, (3, 3), activation="relu", padding="same")(up9) conv9 = Conv2D(32, (3, 3), activation="relu", padding="same")(conv9) conv10 = Conv2D(n_label, (1, 1), activation="sigmoid")(conv9) #conv10 = Conv2D(n_label, (1, 1), activation="softmax")(conv9) model = Model(inputs=inputs, outputs=conv10) model.compile(optimizer='Adam', loss='binary_crossentropy', metrics=['accuracy'])
return model读取数据的组织方式有一些改动。
# data for training
def generateData(batch_size,data=[]): #print 'generateData...' while True: train_data = [] train_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 img = load_img(filepath + 'src/' + url) img = img_to_array(img) train_data.append(img) label = load_img(filepath + 'label/' + url, grayscale=True) label = img_to_array(label)
#print label.shape train_label.append(label) if batch % batch_size==0: #print 'get enough bacth!\n' train_data = np.array(train_data) train_label = np.array(train_label) yield (train_data,train_label) train_data = [] train_label = [] batch = 0
# data for validation
def generateValidData(batch_size,data=[]): #print 'generateValidData...' while True: valid_data = [] valid_label = [] batch = 0 for i in (range(len(data))): url = data[i] batch += 1 img = load_img(filepath + 'src/' + url) #print img img = img_to_array(img) # print img.shape valid_data.append(img) label = load_img(filepath + 'label/' + url, grayscale=True) valid_label.append(label) if batch % batch_size==0: valid_data = np.array(valid_data) valid_label = np.array(valid_label) yield (valid_data,valid_label) valid_data = [] valid_label = [] batch = 0 训练:指定输出model名字和训练集位置
python unet.py --model unet_buildings20.h5 --data ./unet_train/buildings/预测单张遥感图像时我们分别使用4个模型做预测,那我们就会得到4张mask(比如下图就是我们用训练好的buildings模型预测的结果),我们现在要将这4张mask合并成1张,那么怎么合并会比较好呢?我思路是,通过观察每一类的预测结果,我们可以从直观上知道哪些类的预测比较准确,那么我们就可以给这些mask图排优先级了,比如:priority:building>water>road>vegetation,那么当遇到一个像素点,4个mask图都说是属于自己类别的标签时,我们就可以根据先前定义好的优先级,把该像素的标签定为优先级最高的标签。代码思路可以参照下面的代码:

def combind_all_mask(): for mask_num in tqdm(range(3)):
if mask_num == 0: final_mask = np.zeros((5142,5664),np.uint8)
#生成一个全黑全0图像,图片尺寸与原图相同 elif mask_num == 1: final_mask = np.zeros((2470,4011),np.uint8) elif mask_num == 2: final_mask = np.zeros((6116,3356),np.uint8) #final_mask = cv2.imread('final_1_8bits_predict.png',0) if mask_num == 0: mask_pool = mask1_pool
elif mask_num == 1: mask_pool = mask2_pool
elif mask_num == 2: mask_pool = mask3_pool final_name = img_sets[mask_num]
for idx,name in enumerate(mask_pool): img = cv2.imread('./predict_mask/'+name,0) height,width = img.shape label_value = idx+1 #coressponding labels value for i in tqdm(range(height)): #priority:building>water>road>vegetation for j in range(width):
if img[i,j] == 255:
if label_value == 2: final_mask[i,j] = label_value elif label_value == 3
and final_mask[i,j] != 2: final_mask[i,j] = label_value elif label_value == 4
and final_mask[i,j] != 2
and final_mask[i,j] != 3: final_mask[i,j] = label_value elif label_value == 1
and final_mask[i,j] == 0: final_mask[i,j] = label_value cv2.imwrite('./final_result/'+final_name,final_mask) print 'combinding mask...'combind_all_mask() 模型融合
集成学习的方法在这类比赛中经常使用,要想获得好成绩集成学习必须做得好。在这里简单谈谈思路,我们使用了两个模型,我们模型也会采取不同参数去训练和预测,那么我们就会得到很多预测MASK图,此时 我们可以采取模型融合的思路,对每张结果图的每个像素点采取投票表决的思路,对每张图相应位置的像素点的类别进行预测,票数最多的类别即为该像素点的类别。正所谓“三个臭皮匠,胜过诸葛亮”,我们这种ensemble的思路,可以很好地去掉一些明显分类错误的像素点,很大程度上改善模型的预测能力。
少数服从多数的投票表决策略代码:
import numpy as npimport cv2import argparse RESULT_PREFIXX = ['./result1/','./result2/','./result3/']
# each mask has 5 classes: 0~4
def vote_per_image(image_id): result_list = []
for j in range(len(RESULT_PREFIXX)): im = cv2.imread(RESULT_PREFIXX[j]+str(image_id)+'.png',0) result_list.append(im) # each pixel height,width = result_list[0].shape vote_mask = np.zeros((height,width))
for h in range(height):
for w in range(width): record = np.zeros((1,5))
for n in range(len(result_list)): mask = result_list[n] pixel = mask[h,w] #print('pix:',pixel) record[0,pixel]+=1 label = record.argmax()
#print(label) vote_mask[h,w] = label cv2.imwrite('vote_mask'+str(image_id)+'.png',vote_mask) vote_per_image(3)模型融合后的预测结果:
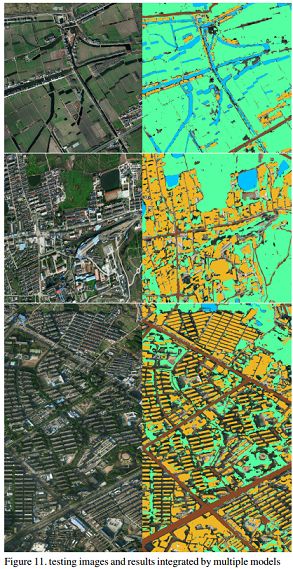
可以看出,模型融合后的预测效果确实有较大提升,明显错误分类的像素点消失了。
额外的思路:GAN
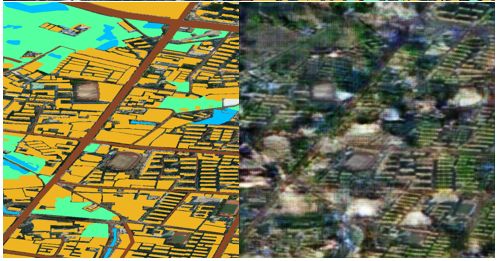
我们对数据方面思考得更多一些,我们针对数据集小的问题,我们有个想法:使用生成对抗网络去生成虚假的卫星地图,旨在进一步扩大数据集。我们的想法就是,使用这些虚假+真实的数据集去训练网络,网络的泛化能力肯定有更大的提升。我们的想法是根据这篇论文(pix2pix)来展开的,这是一篇很有意思的论文,它主要讲的是用图像生成图像的方法。里面提到了用标注好的卫星地图生成虚假的卫星地图的想法,真的让人耳目一新,我们也想根据该思路,生成属于我们的虚假卫星地图数据集。 Map to Aerial的效果是多么的震撼。



但是我们自己实现起来的效果却不容乐观(如下图所示,右面那幅就是我们生成的假图),效果不好的原因有很多,标注的问题最大,因为生成的虚假卫星地图质量不好,所以该想法以失败告终,生成的假图也没有拿去做训练。但感觉思路还是可行的,如果给的标注合适的话,还是可以生成非常像的虚假地图。
总结
对于这类遥感图像的语义分割,思路还有很多,最容易想到的思路就是,将各种语义分割经典网络都实现以下,看看哪个效果最好,再做模型融合,只要集成学习做得好,效果一般都会很不错的。我们仅靠上面那个简单思路(数据增强,经典模型搭建,集成学习),就已经可以获得比赛的TOP 1%了,当然还有一些tricks可以使效果更进一步提升,这里就不细说了,总的建模思路掌握就行。完整的代码可以在我的github获取。
Github:https://github.com/AstarLight/Satellite-Segmentation
原文:http://www.cnblogs.com/skyfsm/p/8330882.html

或点击“阅读原文”,查看详情




