两篇AAAI论文,揭示微信如何做文章质量评估
本文介绍了微信搜索数据质量团队在 AA AI 2021 大会发 表的两篇研究。
随着社交媒体和移动信息流应用的发展,涌现出了许多用户生成内容模式下的自媒体应用,每个用户都可以作为内容生产者,产生了海量在线文章内容。这些自媒体应用提供推荐和搜索服务让内容消费者可以浏览他们感兴趣的内容。同时,自媒体内容创作的开放性同时也导致了文章质量的参差不齐。在推荐和搜索系统中,结果质量是影响用户体验的的重要因素,评估自媒体在线文章质量对在线推荐、搜索和广告等应用场景都具有重要意义。
文章质量可以从两个维度进行评价,一是从文章内容本身来进行质量的建模和识别,包括内容语义、写作逻辑等方面。二是根据文章在大众用户中的流行度和传播度来判断,文章的流行度和传播量反应了用户对文章的喜爱程度,内容消费者在阅读和传播过程中会对低质量内容进行筛选和过滤。
在 AAAI 2021 上,微信搜索数据质量团队在文章写作连贯性建模和实时传播度预测两个方面发表了研究论文,下面将分别进行介绍。
论文:Hierarchical Coherence Modeling for Document Quality Assessment

不同于其它文本分类任务(如文本主题分类、情感识别等)主要关注文本内容的语义,文章质量不止跟文章语义有关,也跟文章的写作水平有关。写作水平包括遣词造句和文章结构组织的连贯性、逻辑性。
其中,如何建模文章的写作连贯性 (coherence) 是一个困难的任务,有很多研究人员已经在这个问题上做出了他们的贡献。相关研究可以分为三类:(1) 基于实体的方法,识别句子中的实体,建模相邻句子中实体的联系;(2) 基于词汇的方法,建模相邻句子的词共现信息 (3) 基于神经网络的方法,利用神经网络学习词和句字语义的向量表示,建模语义向量的相似度。大部分现有方法都只关注到了相邻句子的相似性,但是相邻句子的相似性只是写作连贯性的一部分。
连贯性不只是两个相邻的句子描述相似的内容,多个相邻句子可能构成更复杂修辞结构,比如排比、并列等。在这些修辞结构中,相邻的句子不一定很相似,但是上下文整体是连贯的。除此之外,写作连贯性也不止存在于局部上下文,文章写作很可能存在层次结构,多个局部连贯的内容组成一个部分(段落),段落间的连贯性也是文章写作连贯性的一个重要部分。因此建模文章的写作连贯性还需要解决这样两个挑战:(1) 如何建模复杂多样的局部修辞结构?(2) 如何建模文章的层次连贯性?
针对上述挑战,微信搜索数据质量团队提出名为 Hierarchical Coherence Model (HierCoh) 的方法来建模文章质量。模型包括 4 个部分:Sentence Layers 通过 Transformer Encoder 建模词向量,并通过 Attention Pooling 得到句子表示向量;Hierarchical Coherence Layers 建模文章的层次连贯性得到连贯性向量;Document Layers 将句子表示向量汇聚在一起得到文章语义表示向量;最后将连贯性向量和语义向量合并起来输入到任务相关的输出层。
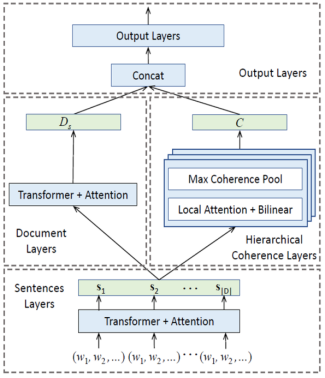
图 1. HierCoh 模型框架图
层次连贯性建模
HierCoh 中最重要的部分是层次连贯性建模部分。该部分首先提取每个句子的局部上下文(local context block) 语义,然后得到句子跟该上下文的多维连贯性表示向量。研究者将句子视为最低级(low-level)的语义单元,然后基于这样一个假设得到高级 (high-level) 语义单元:如果连续的几个低级语义单元具有高连贯性,那么他们可以被视为一个高级语义单元。然后用同样的方式得到高级语义单元的连贯性,以及更高级的语义单元和他们的连贯性。研究者用 Local Attention 来提取局部上下文,用双线性层来建模多维连贯性,并提出了 Max-coherence Pooling 来提取高级语义单元。
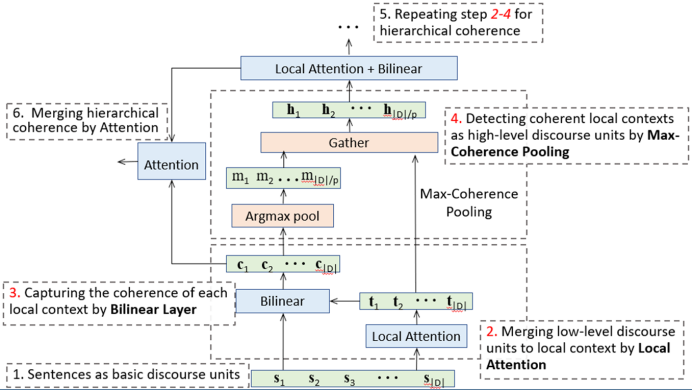
图 2. Hierarchical Coherence Layer
Local Attention. 将 CNN 中的局部连接结构和 Attention 机制相结合,相比采用线性变化做卷积计算,Local Attention 更适合将相邻句子的语义汇聚成上下文语义。
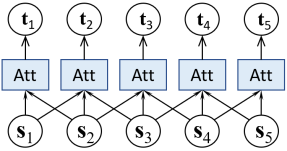
图 3. Location Attention
Bilinear Tensor Layer. 双线性层中包含一个参数张量,参数张量中的每个切片矩阵可以视为是一种修辞关系的表示,因此通过双线性层得到的多维连贯性向量就表示了多种修辞关系的概率。
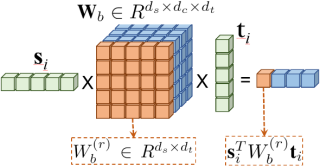
图 4. Bilinear Layer
Max-Coherence Pooling. 以步长 p 在大小为 k 的窗口内将低级语义单元合并为高级语义单元,首先计算窗口内每个 local context block 的平均连贯性向量,然后取最大连贯性向量的最大维度(即概率最大的修辞关系的概率)作为该 local context 的连贯性分数,然后取窗口内连贯性分数最大的 local context 作为高级语义单元。
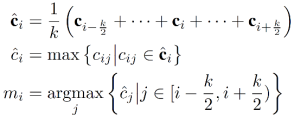
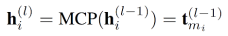
然后重复 Local Attention 和 Bilinear Tensor Layer 即可得到高阶连贯性。最后用 Attention 将多级连贯性融合成连贯性向量,就得到了文章的多层次连贯性表示。
实验验证
该模型在两个经典的文章质量评估任务上进行了验证:自动作文打分和在线新闻质量判别。
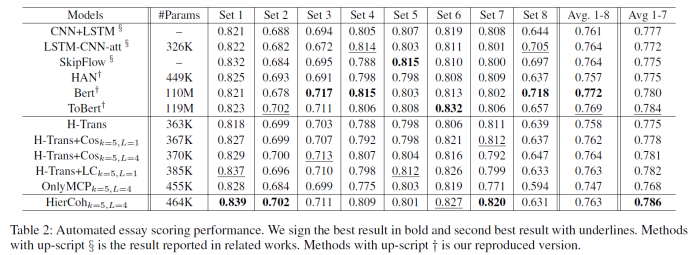
自动作文打分(Automated Eassy Scoring)采用该任务最常用的 APSP 文档集[1]。该数据集包含 8 个作文题目,每个题目下的作文得分被缩放到 [0,1] 区间内。解决该任务采用了 sigmoid 输出层,均方误差作为损失函数来训练模型。
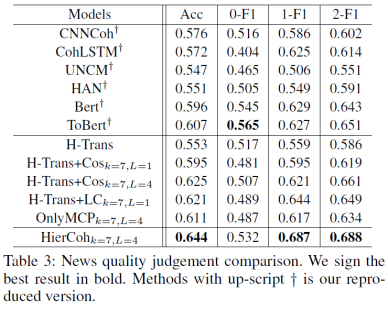
在自动作文打分任务上的结果如下表,可以看出 HierCoh 模型在作文题目 1-7 的集合上都取得了最优 / 较优的效果(作文集合 8 由于文章数量最少并且文章长度最长)。
此外,微信搜索数据质量团队采集了微信平台上的新闻文章,并将描述同一个主题或事件的新闻组成新闻对,雇佣标注人员标注了这两篇新闻的质量哪个更好。共分为 3 个类别,类别 0 表示两篇新闻质量相近,类别 1 表示第一篇新闻质量更好,类别 2 表示第二篇新闻质量更好。研究者用孪生网络结构来建模两篇文章,然后合并最终的文章表示向量到 softmax 输出层,得到三分类概率,并用交叉熵作为损失函数来训练模型。实验结果如下,HierCoh 模型取得了最优的效果。
论文:Fully Exploiting Cascade Graphs for Real-time Forwarding Prediction

传播量是衡量在线文章受欢迎程度的最重要指标之一。在线文章的传播量是指用户通过社交媒体转发在线文章的次数。在社交媒体中,用户与他们的朋友共享并交换有趣的文章内容。因此,在线内容的传播通常从作者开始,并通过社交网络传播,从而形成级联图。级联图通常是有向无环图。其中有向路径表示通过社交网络的内容传播过程。社交网络上的信息传播形成为社交网络强化模型和以社交中心为枢纽的模式。级联图的尺寸(节点数量)可被视为在线内容的转发量。因此可以通过对级联图建模,从而得到能准确预测传播量的模型。
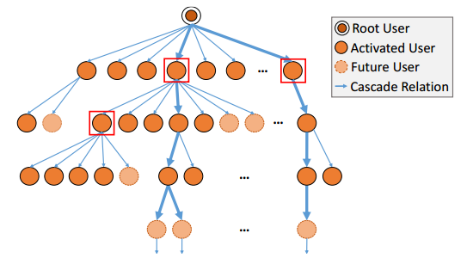
图 1. 级联图示例
但是,现有的方法要么无法有效建模级联图、要么忽略了级联图尺寸的宏观变化信息。尽管基于图卷积神经网络 (GCN) 的方法可以通过重复聚合邻居节点特征并更新节点特征最终遍历所有节点,但它对于建模深的级联路径来说是迂回曲折的。基于随机游走 (Random Walk) 的方法会随机选择片面的级联路径,可能会丢失社交中心的信息。另一方面,只聚焦于学习级联图的路径结构和节点信息,会忽略级联图尺寸的宏观变化信息。
为了解决这些挑战,微信数据质量团队提出了一个充分利用级联图信息进行转发量预测的方案。在该方案中,设计了针对级联图的图嵌入算法,能有效捕获对级联图中的深度传播路径和社交枢纽信息;还设计了级联图尺寸建模方法,该方法能有效应对级联图尺寸的急剧变化。作者还构建了一个大规模的真实世界评估数据集。充分的实验结果表明,与之前的转发量建模和图嵌入方法相比,所提出的方法在实时的转发量预测方面,准确率有了极大的提升。
具体方法
微信搜索数据质量团队提出了时间级联图建模(TempCas)方案,以解决上述挑战。该方案包含两部分:级联图嵌入和适应短期爆发的时间序列建模。方案总览如图 2 所示。
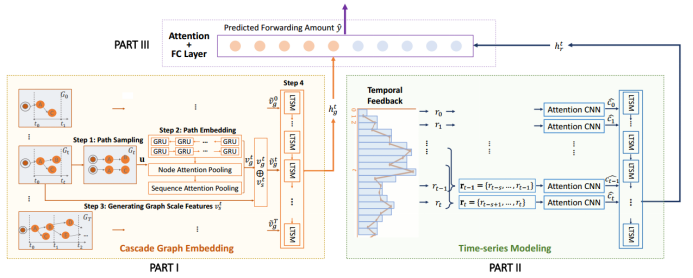
图 2. 方案总览
(1)级联图嵌入
给定一个级联图快照系列,级联图嵌入负责捕获级联图特征的三个方面,包括:扩散特征,尺寸特征和时间特征。本方案通过 4 个步骤捕获这三个特征。
步骤 1:级联路径采样。社交中心和深度级联路径对级联图影响最大,而其他叶节点等几乎没有传播影响。为了充分获得级联图扩散特征,社交中心和深度级联路径是捕获级联图扩散特征的关键。为此,研究者设计了一个启发式的路径采样策略,如算法 1 所示。

步骤 2:级联路径表示。在通过算法 1 进行路径采样之后,研究者通过 BiGRU 得到节点表示。再通过两层 Attention 机制获得级联路径的表示向量。
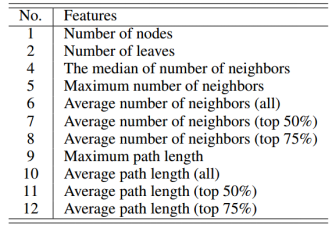
步骤 3:采样的路径涵盖了最具影响力的节点和路径,但可能会丢失许多琐碎节点(例如叶子节点)的信息,这些琐碎节点构成了级联图的主要部分,但扩散影响很小。因此,研究者提取琐碎节点信息作为补充信息(如下图所示),以使模型了解琐碎节点的结构和尺度。
步骤 4:最后,研究者通过一层 LSTM 来捕获级联图的特征的时间序列信息。
(2)适应短期爆发的时间序列建模
级联图尺寸的短期爆发对实时转发预测影响很大。研究者采用了一种 Attention CNN 机制来对短期暴发进行建模。在 Attention CNN 机制之后堆叠一个 LSTM 层来对历史短期暴发的影响进行建模。
实验
研究者从微信公众号平台上收集处理在线文章数据,构建了一个自媒体在线文章质量分类数据集。研究者从 2019 年 8 月 1 日至 2019 年 9 月 30 日随机抽样了 26,893 篇文章,并跟踪 75 小时内每篇文章的所有转发情况。除微信数据集外,为了更全面地评估模型,研究者还采用了微博转发数据集。
对比实验结果显示,所提方法 TempCas 在各项指标上均显著达到最佳。此外,将本方案的级联图嵌入部分(TempCasG)和其他图嵌入方案相比,本方案提出的级联图嵌入也达到了最优的转发量预测效果。
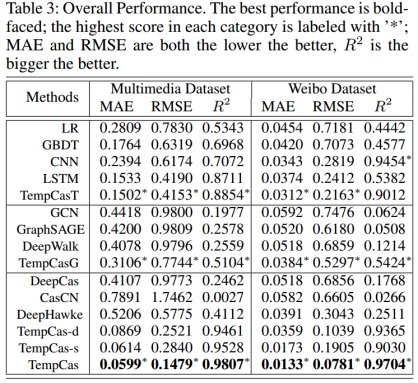
通过观察 Table 3,可以看到,与基于时间序列的转发量预测方法相比,基于级联图嵌入的转发量预测方法的准确率相对较弱。实际上,当面对热点在线内容时,基于级联图嵌入的方法比基于时间序列的方法更为准确。研究者对此进行了更进一步的探索以验证此结论。
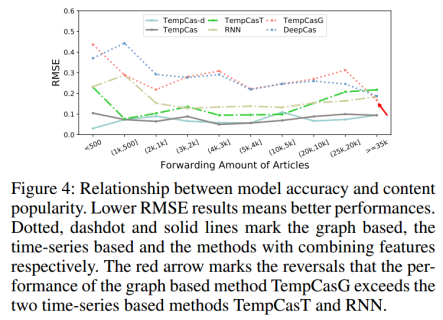
研究者将多个方案的 RMSE 预测结果与相应的最终转发量相关上,并绘制了 Figure 4。可以看到,当面对热点内容时,基于级联图嵌入的方法往往比基于时间序列的方法具有更好的性能。
亚马逊云科技白皮书《策略手册:数据、 分析与机器学习》
点击阅读原文,免费领取白皮书。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com