演讲 | Yann LeCun清华演讲:深度学习与人工智能的未来
机器之心原创
作者:高静宜
2017 年 3 月 22 日下午,Facebook 人工智能研究院院长、纽约大学终身教授 Yann LeCun 在清华大学大礼堂为校内师生以及慕名而来的业内人士呈现了一场主题为《深度学习与人工智能的未来(Deep Learning and the Future of AI)》的精彩公开课。
随着 AlphaGo 事件的不断发酵,神经网络成为时下人工智能产学领域万众瞩目的研究焦点,也成为普罗大众的热门话题。事实上,神经网络作为一种算法模型,很早就已经被广泛关注和研究,也曾长时间内陷入发展突破的低潮期。不过,在以 Geoffrey Hinton、Yann LeCun 和 Yoshua Bengio 为代表的众多神经网络活跃研究者的坚持和努力下,人们对卷积神经网络的研究得到开拓性进展,深度学习进入大众视野,神经网络终于在 2006 年迎来了复兴。
Yann LeCun 作为深度学习运动的领军人物,Facebook 人工智能研究院院长兼纽约大学教授,其一举一动都能引发业界的广泛关注。这次,由清华大学经济管理学院发起,清华 x-lab、Facebook 主办的主题讲座邀请了 Yann LeCun,作为《创新与创业:硅谷洞察》学分课程中的第一节公开课的讲者,针对深度学习技术的历史发展进程与人工智能的未来趋势进行了深入的解析,并分享了一些精彩观点。
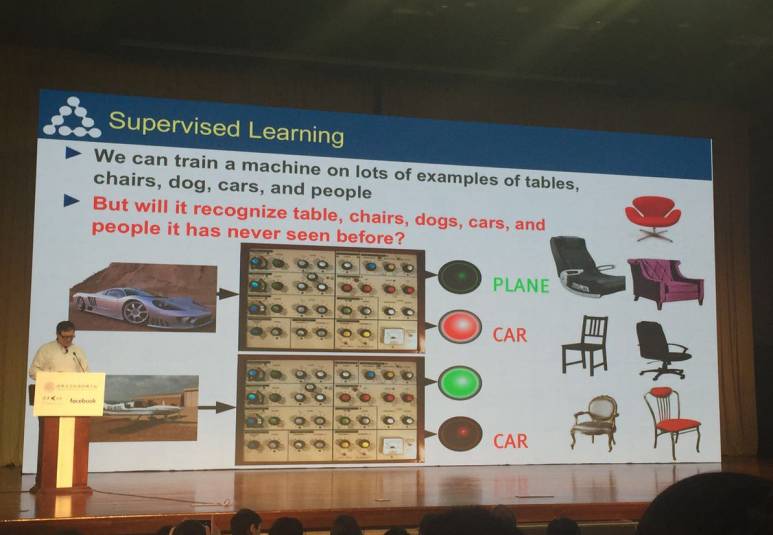
一开场,Yann LeCun 就通过回顾去年的 AlphaGo 事件引出今天讲座的主题《深度学习与人工智能的未来》,并向在场观众抛出了一个问题:人类可以利用大量的样本去训练机器,可是机器能够识别出它从未见过的事物吗?
带着这个问题,Yann LeCun 讲述了深度学习的发展过程以及他个人在领域内的探索历程。
首先,Yann LeCun 回顾了 1957 年的感知器以及 50 年代末期的传统模式识别模型,并对传统模式识别、主流现代模式识别以及深度学习特征提取方式进行了比对;随后,他又对多层神经网络、反向传播算法、卷积神经网络结构(归一化——滤波器组——非线性计算——池化)等算法概念进行解析;并且展示了 1993 年完成的 LeNET1 Demo。

传统的模式识别是固定的/人工设计的特征提取器:数据→特征提取器→可训练的分类器
主流的现代模式识别使用了无监督的中级特征:数据→特征提取器→中级特征→可训练的分类器
深度学习方法则使用了训练出来的分层的表征:数据→低级特征→中级特征→高级特征→可训练的分类器
然而,当时业界仍对神经网络的未来仍存迟疑态度。Yann LeCun 举了一件关于他在贝尔实验室两位同事 Jackel (Larry Jackle现任 NVIDIA 机器学习顾问,曾在加拿大多轮多的一场 NVIDIA 的分享会讲过这个故事,并亲自协助完成了机器之心技术分析师对那场分享会的报道,感兴趣的读者可点击阅读原文查看此文章。)和 Vapnik 的趣事。在 1995 年的一次晚餐中,Jackel 曾经跟 Vapnik 打赌说,在 2000 年 3 月 14 日之前,人们将会理解大型神经网络,并给出明确的限定,事实证明,Jackel 的想法错了。而 Vapnik 打赌认为 2005 年 3 月 14 日后,没有人将会使用类似于 1995 年的那些神经网络,事实证明,Vapnik 也错了。
当事人 Larry Jackle 现任 NVIDIA 机器学习顾问,曾在加拿大多轮多的一场 NVIDIA 的分享会讲过这个故事,并亲自协助机器之心技术分析师对那场分享会的报道。

当卷积网络度过瓶颈期并得到人们的认可后,深度卷积网络开始用于解决各类计算机视觉问题,如目标识别;而随着网络深度的不断增加,产生了 VGG、GoogLeNet、ResNet 等深度卷积神经网络结构,它们可以用于图像识别、语义分割、ADAS 等众多场景。
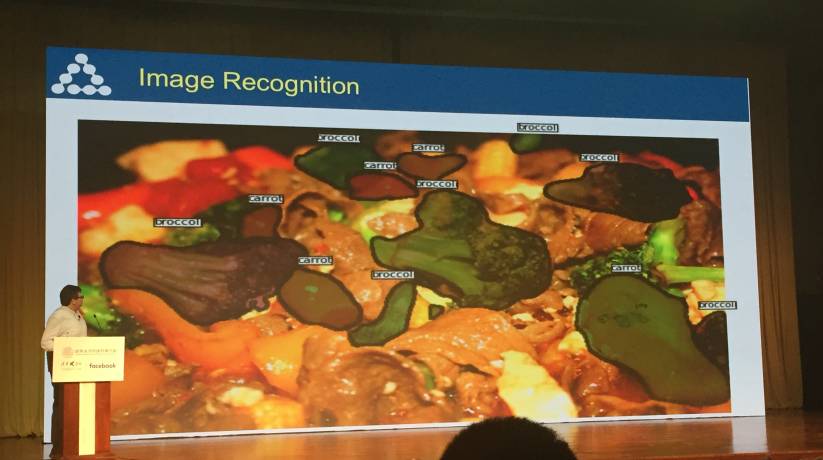
这里,Yann LeCun 特别提到了 Facebook 提出的通用目标分割框架 Mask R-CNN,并展示了它在 COCO 数据集上的结果。(详情可见:学界 | Facebook 新论文提出通用目标分割框架 Mask R-CNN:更简单更灵活表现更好)
在为在场观众带来全新、深入的深度学习技术解析后,Yann LeCun 又探讨了人工智能领域存在的一个障碍和难点——怎样使机器获得「常识」呢?


人工智能进步所面临的障碍:
机器需要学习/理解世界的工作方式:它们需要具备一定程度的常识
机器需要学习非常大量的背景知识:通过观察和行动
机器需要理解世界的状态:从而做出准确的预测和规划
机器学习更新和记忆对世界状态的估计:关注重要事件、记忆相关事件
机器需要推理和规划:预测哪些动作序列可以导致我们想要的世界状态
在人工智能领域,机器是如何跨越这种本质的障碍呢?Yann LeCun 给出了答案,即机器不仅需要学习、理解这个世界,学习大量的背景知识,还需要感知世界的状态,更新、记忆并评估世界的状态,而且还要有推理和计划的能力。这也就是所谓的「智能&常识=感知+预测模型+记忆+推理和规划」。
人们由于了解这个世界运作原理,所以会拥有常识,可是对于机器呢?它们能否具备所谓的「常识」呢?LeCun 举了几个例子进行说明。比如说「这个箱子装不下奖杯,因为它太大/太小了」这句话,当我们说「太大」时,我们知道「它」是奖杯;而当我们说「太小」时,那「它」就是「箱子」了。

机器是无法凭空具备常识的,它需要一些已知的信息,比如根据空间信息推断世界的状态、从过去和现在推断未来、从现在的状态推断过去的事件。那么,这个过程就涉及预测学习(predictive learning)这一个概念,也就是从提供的任何信息预测过去、现在以及未来的任何一部分。不过,这是很多人对无监督学习(unsupervised learning)的定义。

由此看见,无监督学习和预测学习是十分必要的,也是未来几年深度学习型领域的巨大挑战。通常,需要拿来去训练一个大型学习机器的样本数量取决于我们要求机器所预测的信息量。你需要机器回答的问题越多,样本数量就要越大。

「大脑有 10 的 14 次方个突触,我们却只能活大概 10 的 9 次方秒。因此我们的参数比我们所获得的数据会多得多。这一事实激发了这一思想:既然感知输入(包括生理上的本体感受)是我们每秒获取 10^5 维度约束(10^5 dimensions of constraint)的唯一地方,那么,就必须进行大量的无监督学习。」
预测人类提供的标签,一个价值函数(value function)是不够的。这里,Yann LeCun 用一个生动的比喻解释了不同机器学习算法进行预测需要多少信息,并展示了 2016 年 VizDoom 竞赛冠军使用的来自强化学习的 Actor-Critic 算法来生成序列的实例。

此处,Yann LeCun 提到了 Sutton 所提出的 Dyna 结构,这是一种集学习、规划、反应于一身的集成架构,即可以完成「在行动之前实现对脑内设想的尝试」。

之后,Yann LeCun 介绍了经典基于模型的最优化控制过程。即利用初始控制序列对世界进行仿真,调整控制序列利用梯度下降法对目标进行最优化,再进行反向传播。
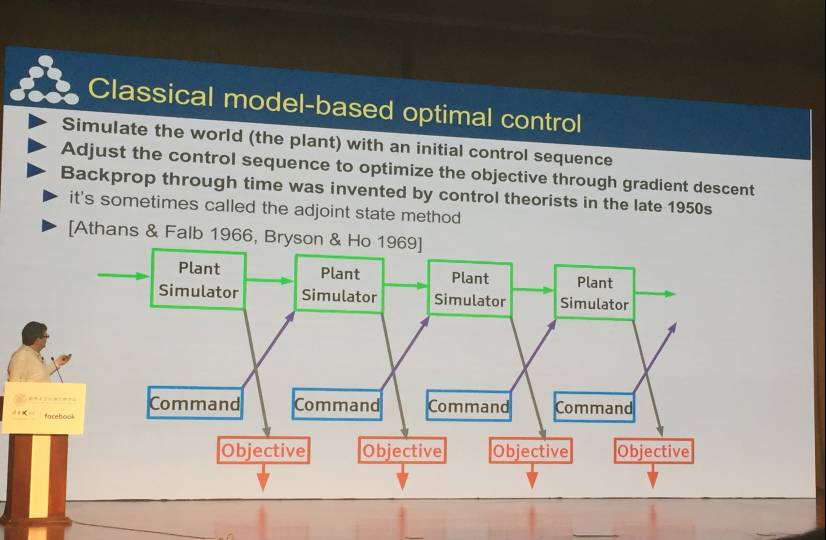
人工智能系统的架构,包括感知器、代理、目标、环境。
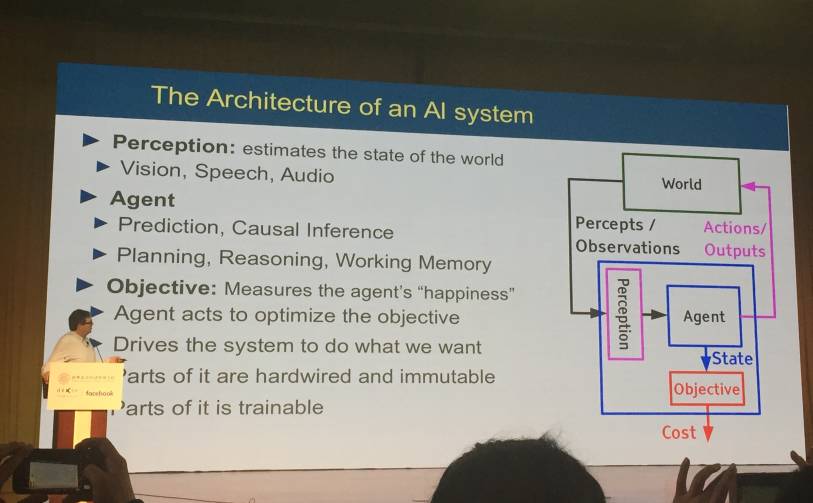
用一个公式概括了人工智能系统,即:预测+规划=推理。
智能的本质是预测的能力,要提前进行规划,我们需要模拟这个世界,然后采取行动以最小化预测损失。
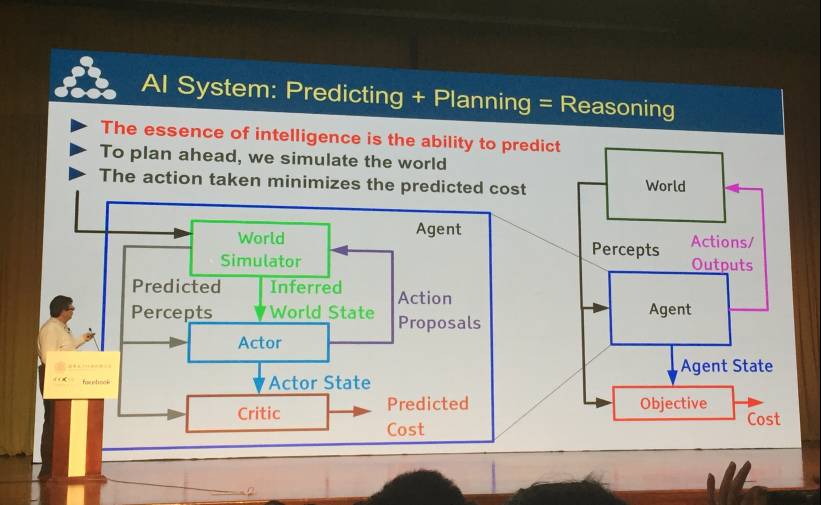
最终得出结论:基于模型的强化学习正是我们需要的。
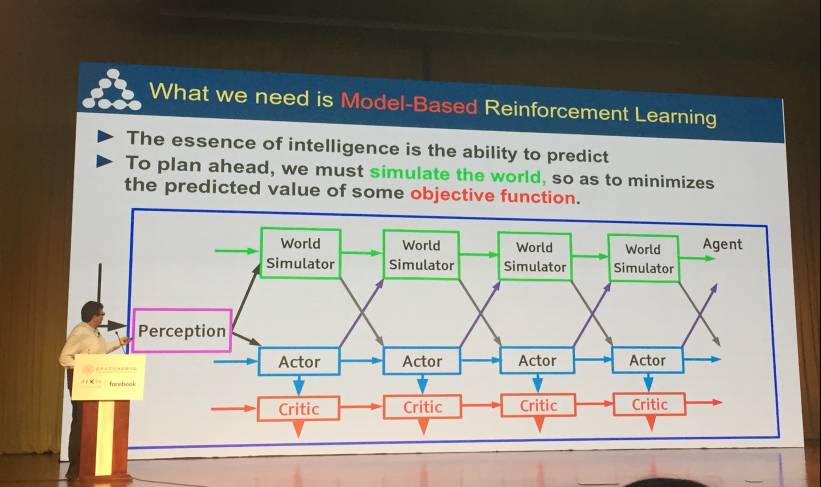
Yann LeCun 指出,机器能否学习出预测世界的模型是实现重大进展的关键。

然后,他也介绍了「根据文本推断世界的状态:实体 RNN」

尽管监督式卷积网络已经取得了重大的进展,我们仍需要记忆增强网络赋予机器进行推论的能力。LeCun 帮助我们理解记忆了堆栈增强循环神经网络。

使用记忆模块增强神经网络
循环网络不能进行长期记忆
皮层记忆只能持续 20 秒
神经网络需要一个「海马体」(一个单独的记忆模块)
长短期记忆(LSTM)[Hochreiter 1997],寄存器
记忆网络 [Weston et 2014] (FAIR),联合存储器
堆栈增强循环神经网络 [Joulin & Mikolov 2014] (FAIR)
神经图灵机 [Graves 2014]
可微分神经计算机 [Graves 2016]

实体循环神经网络
维持一个对于当前世界状态的估计
每一个网络都是一个带有一个记忆的循环网络
每一个输入事件都会导致记忆单元获得一些更新
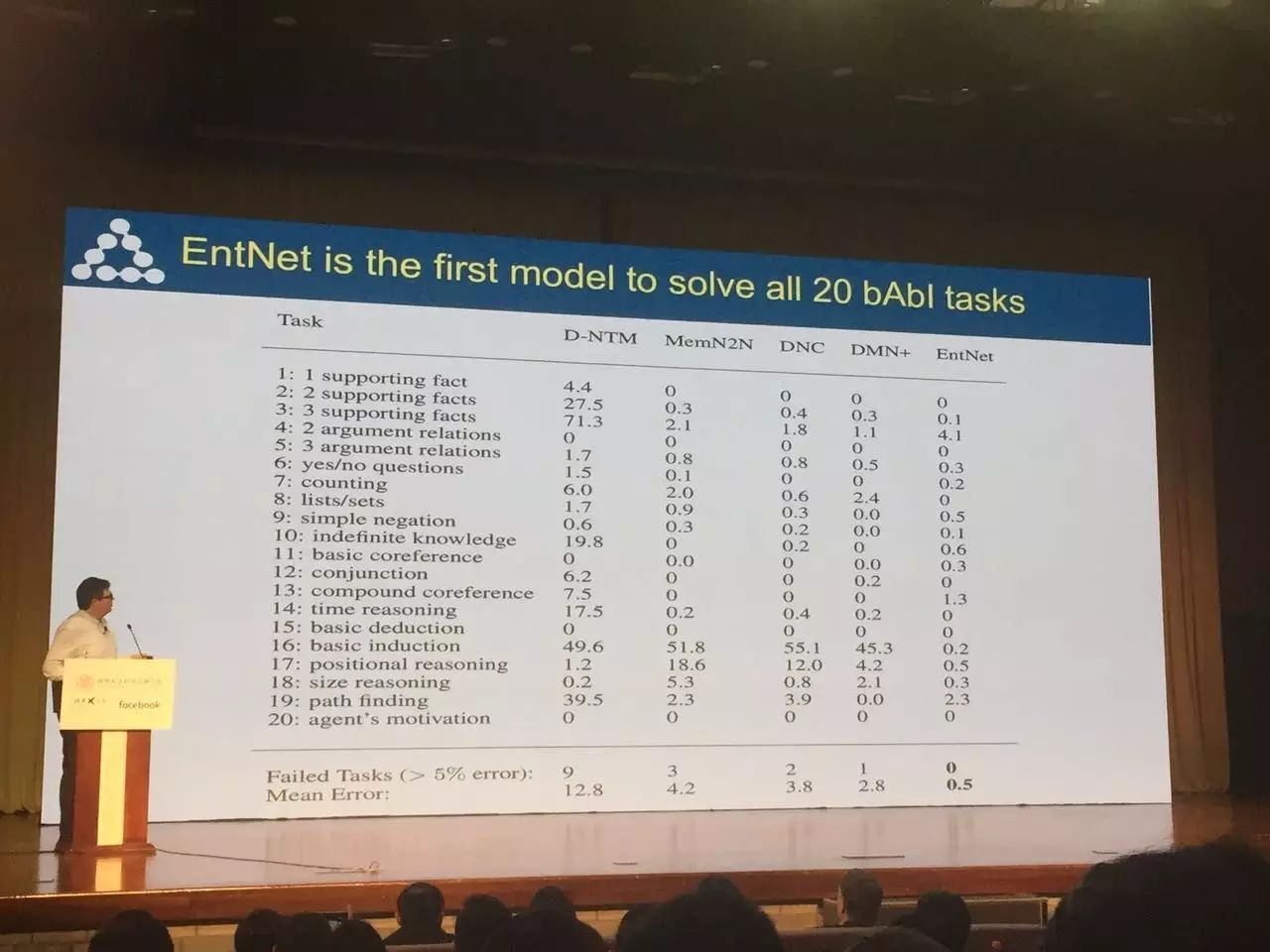
EntNet 是第一种解决了所有 20 中 bAbI 任务的模型
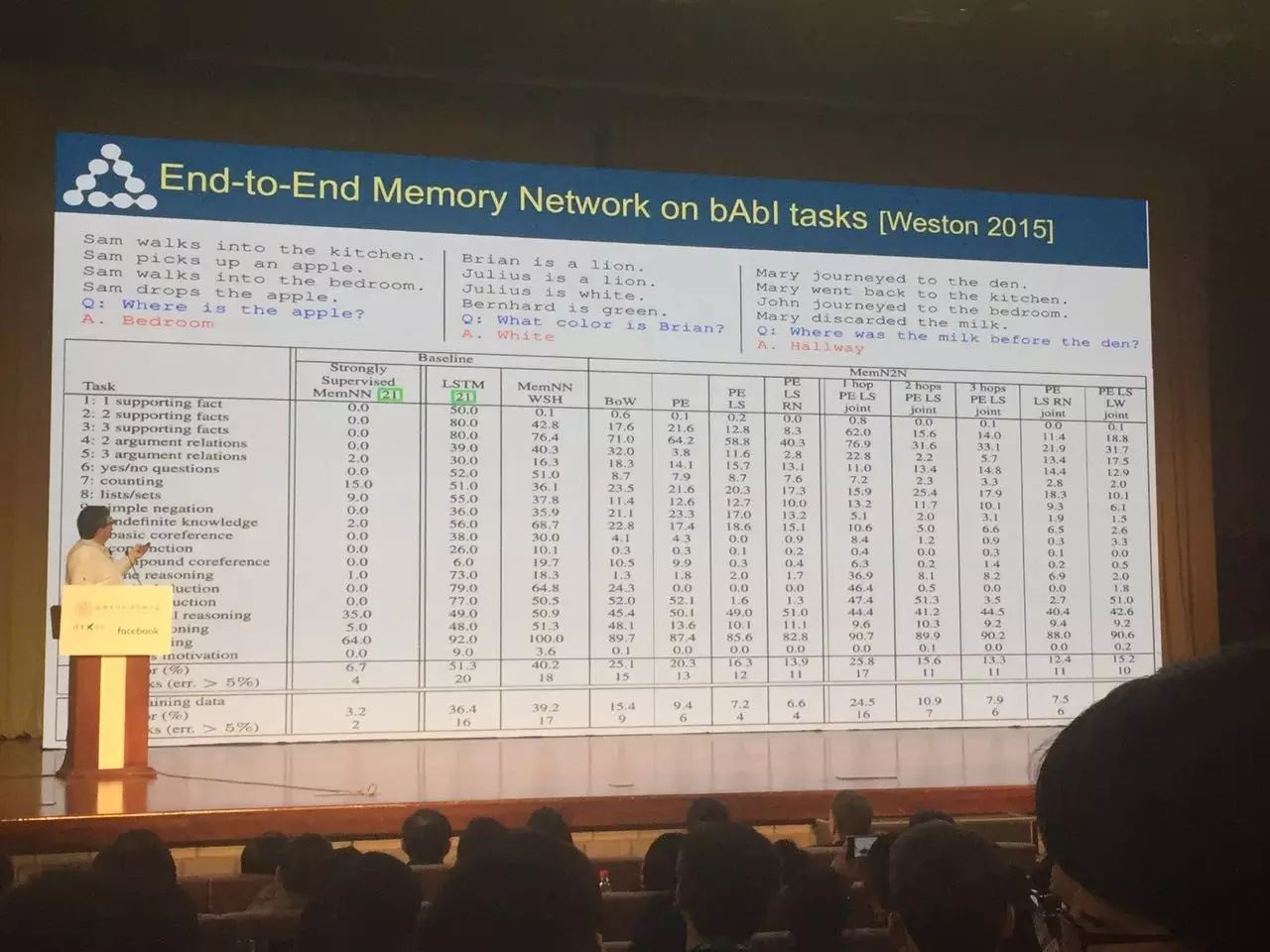
在 bAbI 任务上的端到端记忆网路
在这一部分,Yann LeCun 对基于能量的无监督学习算法进行了比较详细的解析。

学习一个能量函数(或称对比函数),其在数据流形上取低值,在其它地方去高值。
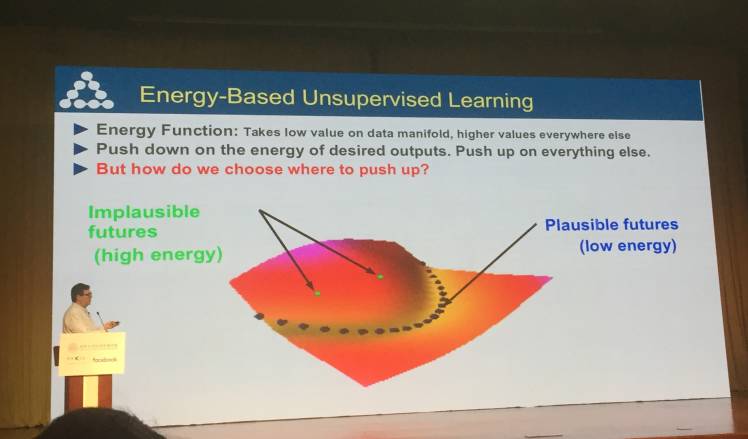
压低我们想要的输出的能量,推高其它地方。但我们该怎么选择推高哪里呢?
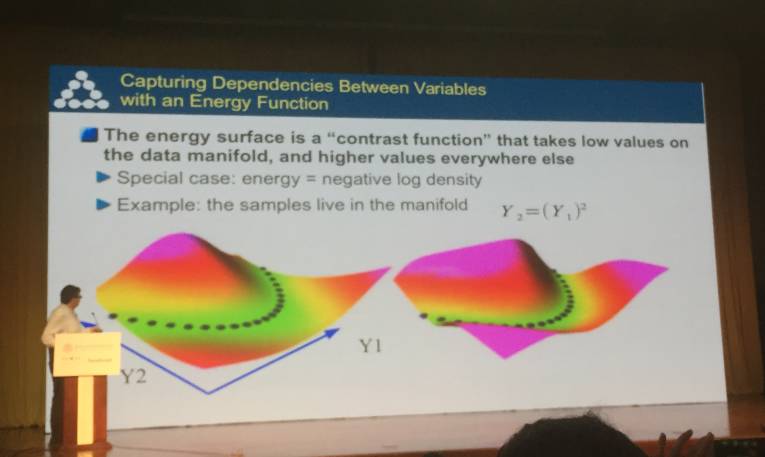
使用一个能量函数来获取变量之间的依赖
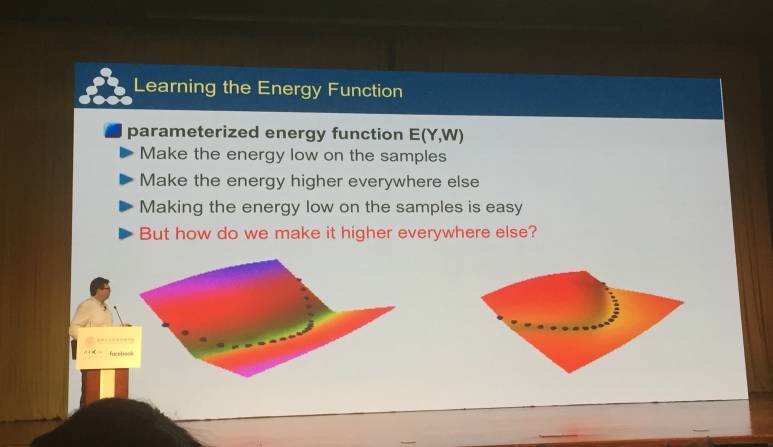
学习能量函数
参数化能量函数:E(Y,W)
使其在样本上的能量低
使其在其它地方的能量高
是能量在样本上低很容易,但要让其它地方它高起来该怎么做呢?

塑造能量函数的 7 种策略
1. 建立低能量体量(the volume of low energy stuff)不变的机器
PCA、K-means、GMM、square ICA
2. 数据点能量的下推(push down),其他位置能量都提高(push up)
最大似然(需要易操作的配分函数)
3. 数据点能量的下推(push down),在选择出的点上进行提高
contrastive divergence、Ratio Matching、Noise Contrastive Estimation、Minimum Probability Flow
4. 围绕数据点最小化梯度,最大化曲率(curvature)
score matching
5. 训练一个动态系统,以便于动态进入 manifold
降噪自编码器
6. 使用正则化进行限制有低能量的空间体量
Sparse coding、sparse auto-encoder、PSD
7. 如果 E(Y) = ||Y - G(Y)||^2, 尽可能的使得 G(Y) 不变
Contracting auto-encoder, saturating auto-encoder
接下来,是关于对抗训练的介绍,Yann LeCun 本人对对抗训练给予高度肯定。对抗训练(GAN)是改进机器预测能力的一种方式。GAN 包括一个生成器、一个判别器,它们可以同时进行学习。

它的难点在于在不确定性下进行预测。
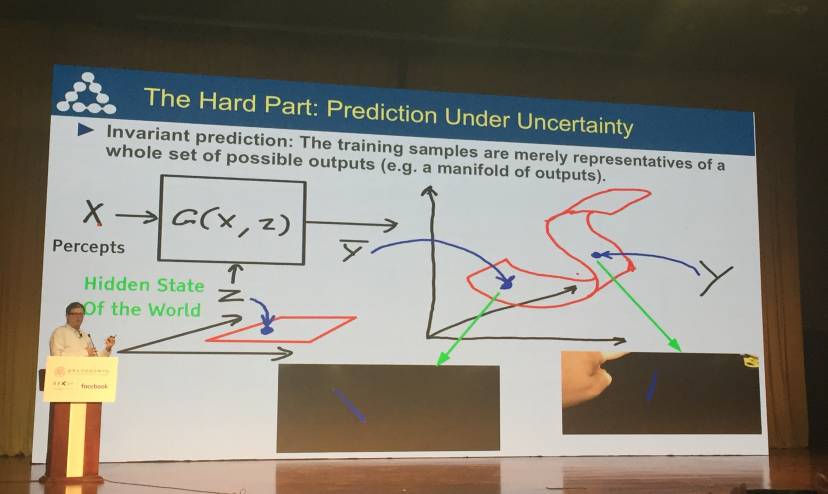
不变的预测:训练样本只是整个可能输出集的表示

对抗训练:不确定情况下进行预测的关键
除了深度卷积对抗生成网络 (DCGAN),他还介绍了基于能量的对抗生成网络(EBGAN)。(详情可见:学界 | Yann LeCun 最新论文:基于能量的生成对抗网络(附论文))
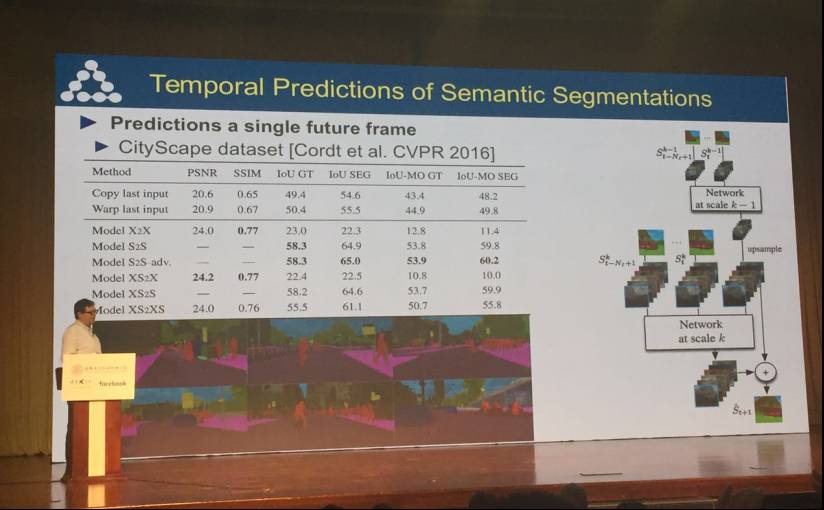
在演讲的最后,Yann LeCun 提到了语义分割的视频预测技术,并展示了时间预测结果。

语义分割的时间预测
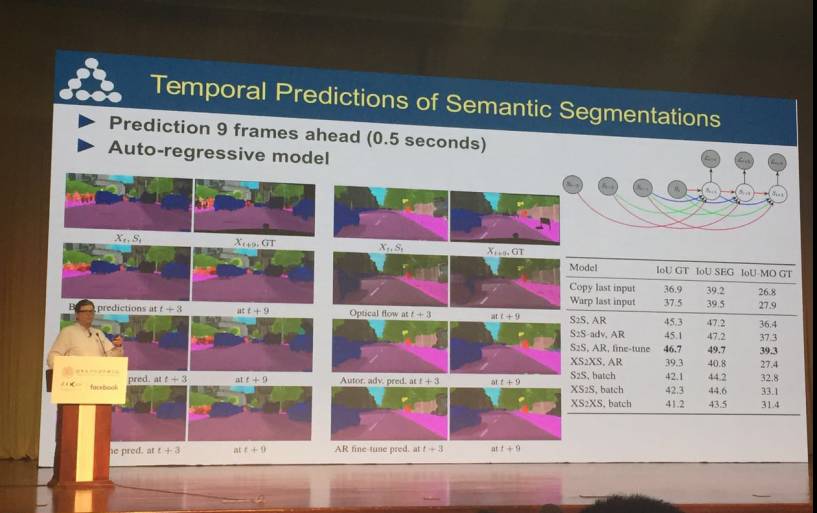
语音分割的暂时性预测:提前 9 帧(0.5 秒)进行预测;自回归模型;
最后简单总结一下,Yann 在演讲中总结了去年人工智能领域的进展,并介绍了监督学习的一些知识点。然后,Yann 聚焦于无监督学习。他认为无监督学习会成为未来的主流,能解决我们的学习系统难以处理的众多问题。我们如今正在面临无监督和预测性前向模型(predictive forward model)的建立,这也可能会是接下来几年的挑战。此外,对抗训练在未来可能会逐渐扮演更重要的角色,而如今的难题是让机器学习「常识」。
演讲结束后,Yann LeCun 回答了现场观众的问题。他本人对近日腾讯围棋 AI 绝艺夺冠一事表示兴奋,并坦承看好人工智能在 ADAS、医疗领域内的发展。

©本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





