【干货】Yann Lecun自监督学习指南(附114页Slides全文)
来源:专知
【导读】Yann Lecun是卷积网络模型的发明者,该模型被广泛地应用于模式识别应用中,因此他也被称为卷积网络之父,是公认的世界人工智能三巨头之一。 2018年11月08日,他来到加州大学圣巴巴拉分校,为在场师生作了一场关于自监督学习的前沿报告,近日他在twitter上公开了报告的全程录像以及Slides全文,现为大家编译如下。
介绍:
11月08日,应加州大学圣巴巴拉分校,统计与应用概率学系(Department of Statistics and Applied Probability)邀请,Facebook副总裁兼人工智能科学家、纽约大学数据科学中心创始主任Yann Lecun为在场师生做了一场自监督学习的前沿报告。
近年来,深度学习在计算机感知、自然语言处理和控制方面取得了重大进展。但几乎所有这些成功都在很大程度上依赖于有监督学习,在监督学习中,机器被要求预测人类提供的标签信息,或通过无模型的强化学习方法,不断的尝试各种行为空间的动作,以期达到收益(reward)最大化。这导致了监督学习需要大量的标记样本,使得它只适用于特定的任务。而强化学习即使在简单的学习任务中,也需要与环境进行大量的交互。相比之下,动物和人类似乎只通过观察和偶尔的互动便学会了大量与任务无关的关于世界如何运转的知识。动物学习新任务所需要的训练样本,以及与世界的互动都非常的少。
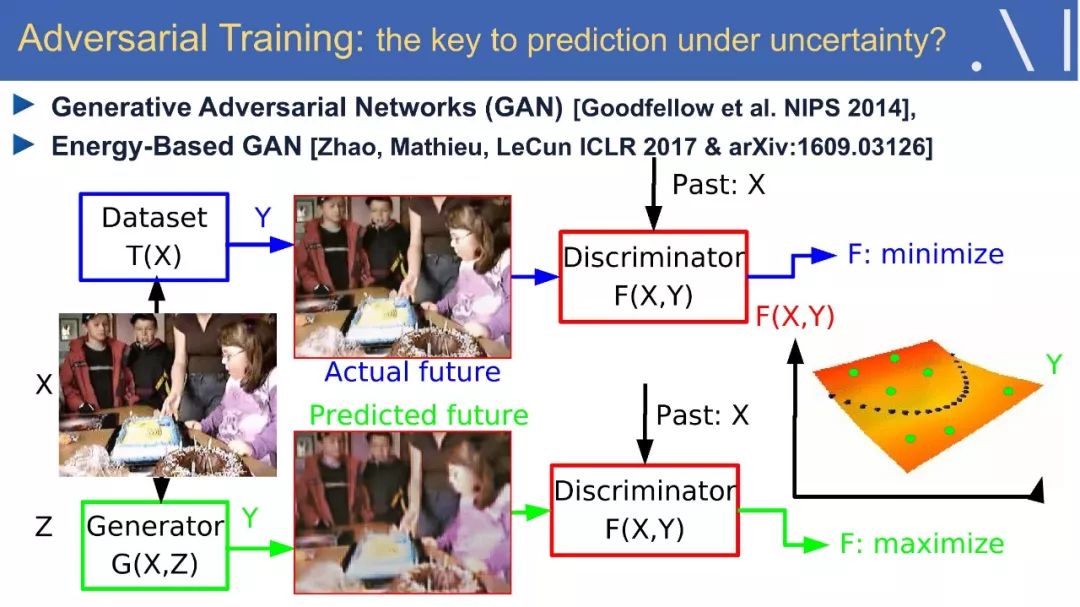
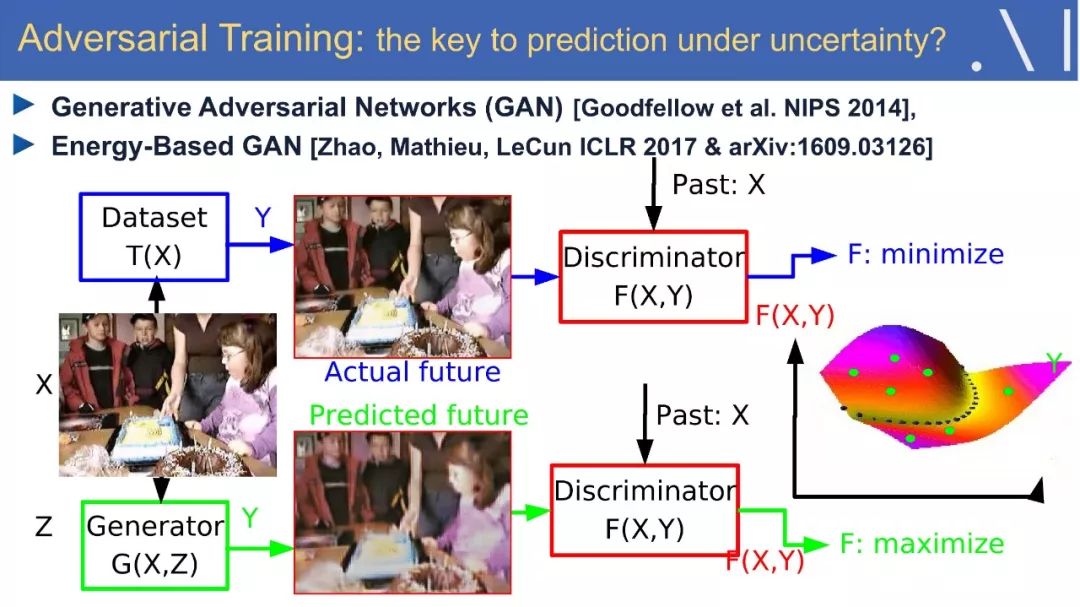
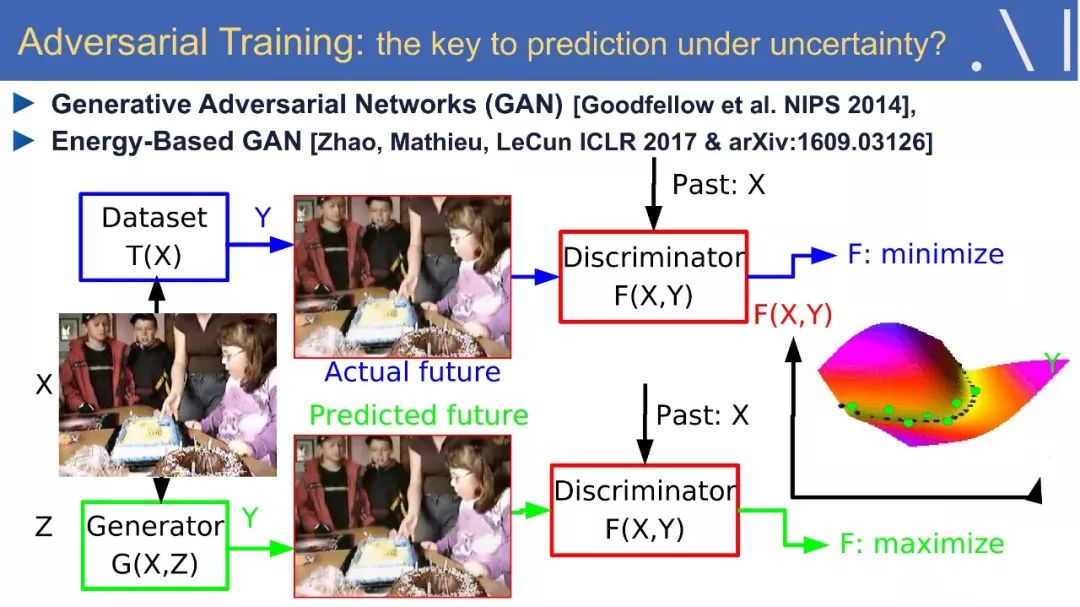
我们甚至能在30个小时的练习中,学会如何驾驶飞机。那么人类和动物是如何进行有效的学习呢?这里将提出一个假设:即预测模型中的自监督学习,是人工智能方法中必不可少的一部分。有了这些模型,人们就可以预测结果并计划如何行动,好的预测模型可能是直觉、推理和“常识”的基础,让我们能够填补缺失的信息:从过去和现在的经验中预测未来,或从嘈杂的世界中推断当前的状态。有人可能会说,预测是智力的本质,在简要介绍了深度学习的现状之后,我们将讨论一些有前途的自监督学习的原则和方法。
作者简介:
在人工智能研究领域,Yann LeCun、Geoffrey Hinton 和 Yoshua Bengio一直被公认为深度学习三巨头。

Yann LeCun,自称中文名“杨立昆”,计算机科学家,被誉为“卷积网络之父”,为卷积神经网络(CNN,Convolutional Neural Networks)和图像识别领域做出了重要贡献,以手写字体识别、图像压缩和人工智能硬件等主题发表过 190 多份论文,研发了很多关于深度学习的项目,并且拥有14项相关的美国专利。他同Léon Bottou和Patrick Haffner等人一起创建了DjVu图像压缩技术,同Léon Bottou一起开发了一种开源的Lush语言,比Matlab功能还要强大,并且也是一位Lisp高手。(Backpropagation,简称BP)反向传播这种现阶段常用来训练人工神经网络的算法,就是 LeCun 和其老师“神经网络之父”Geoffrey Hinton 等科学家于 20 世纪 80 年代中期提出的,而后 LeCun 在贝尔实验室将 BP 应用于卷积神经网络中,并将其实用化,推广到各种图像相关任务中。
Yann LeCun 也是Facebook人工智能研究院院长,纽约大学的 Silver 教授,隶属于纽约大学数据科学中心、Courant 数学科学研究所、神经科学中心和电气与计算机工程系。加盟Facebook之前,Lecun已在贝尔实验室工作超过20年,期间他开发了一套能够识别手写数字的系统,叫作LeNet,用到了卷积神经网络,已开源。他在 1983 年在巴黎 ESIEE 获得电子工程学位,1987 年在 Université P&M Curie 获得计算机科学博士学位。在完成了多伦多大学的博士后研究之后,他在 1988 年加入了 AT&T 贝尔实验室(AT&T Bell Laboratories /Holmdel, NJ),在 1996 年成为 AT&T Labs-Research 的图像处理研究部门主管。2003 年,他加入纽约大学获得教授任职,并在 NEC 研究所(普林斯顿)呆过短暂一段时间。2012 年他成为纽约大学数据科学中心的创办主任。2013 年末,他成为 Facebook 的人工智能研究中心(FAIR)负责人,并仍保持在 NYU 中兼职教学。从 2015 到 2016 年,Yann LeCun 还是法兰西学院的访问学者。
LeCun 是 ICLR 的发起人和常任联合主席(general co-chair),并且曾在多个编辑委员会和会议组织委员会任职。他是加拿大高级研究所(Canadian Institute for Advanced Research)机器与大脑学习(Learning in Machines and Brains)项目的联合主席。他同样是 IPAM 和 ICERM 的理事会成员。他曾是许多初创公司的顾问,并是 Elements Inc 和 Museami 的联合创始人。LeCun 位列新泽西州的发明家名人堂,并获得 2014 年 IEEE 神经网络先锋奖(Neural Network Pioneer Award)、2015 年 IEEE PAMI 杰出研究奖、2016 年 Lovie 终身成就奖和来自墨西哥 IPN 的名誉博士学位。
视频地址:
https://ucsb.app.box.com/s/msam98ewhhk48t60p75glvm9h0fv57fl
内容大纲:
1、深度学习现状

2、强化学习进展

3、距离真正的人工智能,我们错过了什么?

4、可微分编程:深度学习与推理的结合

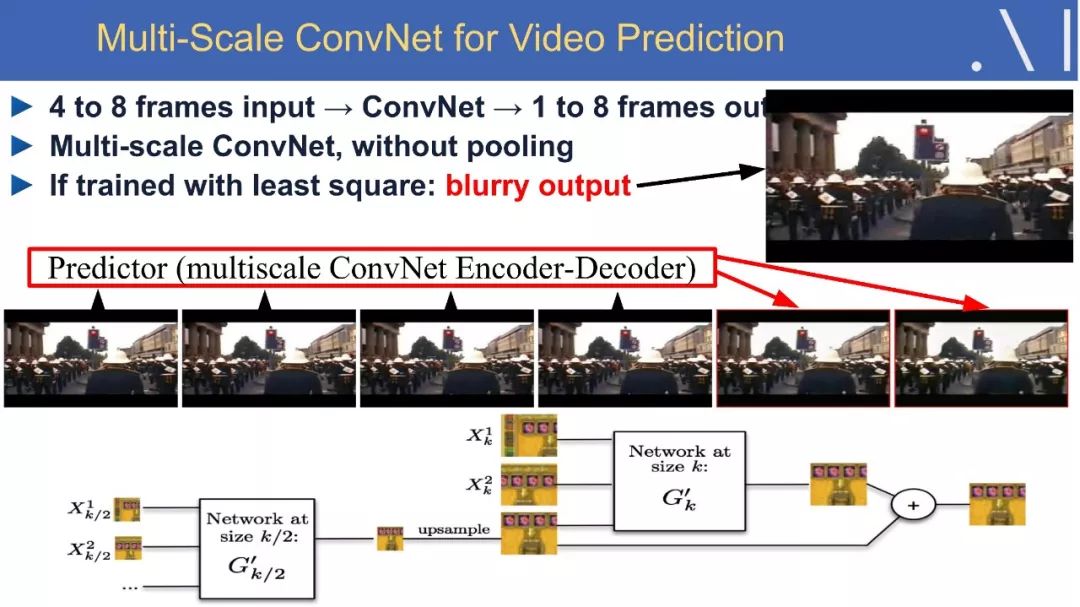
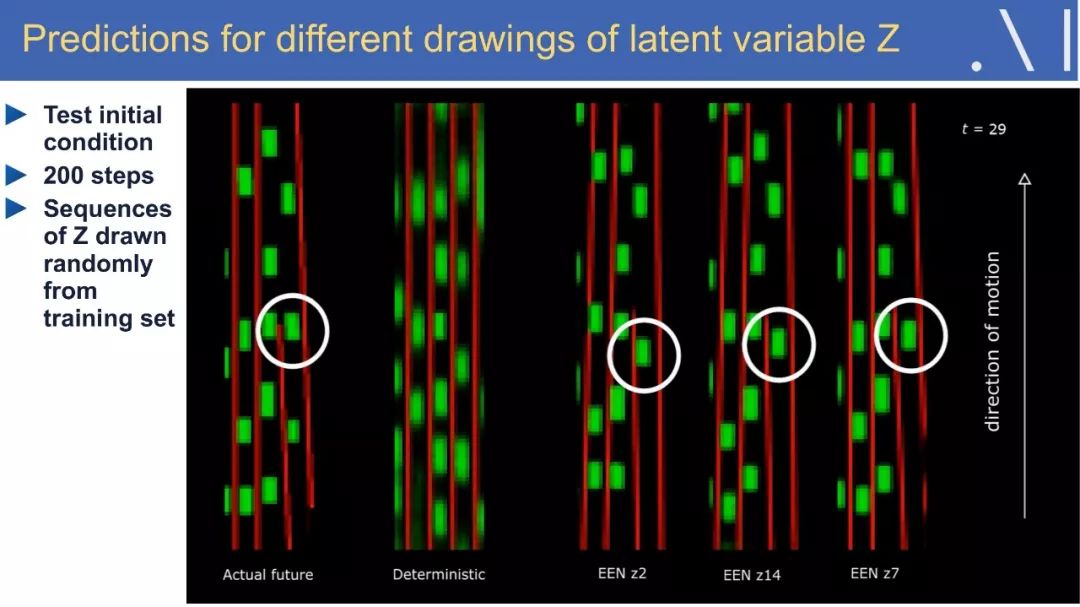
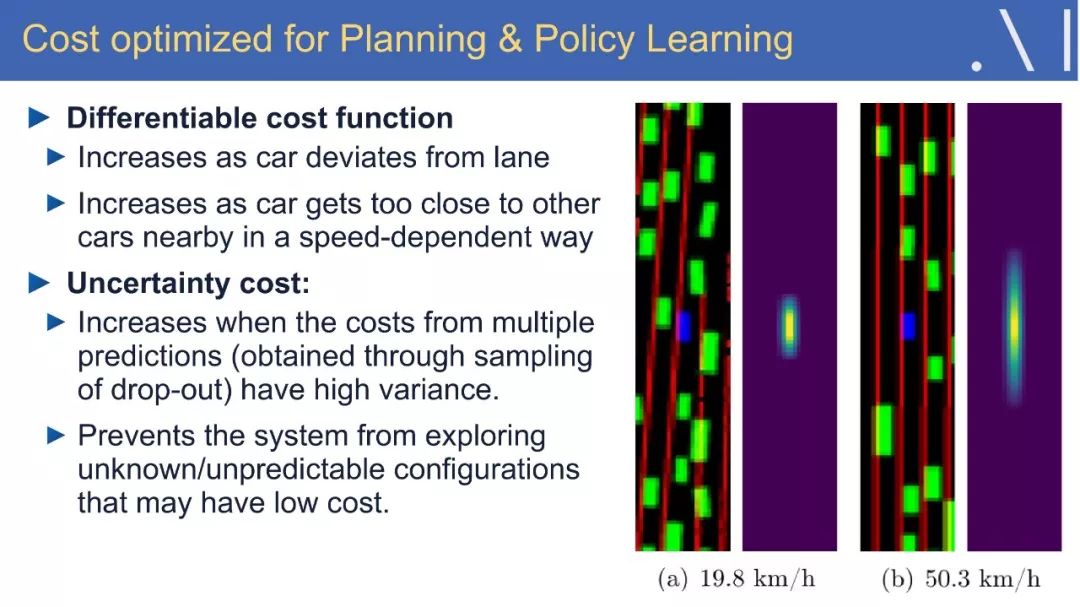
5、学习真实世界的预测模型

6、对抗训练

7、采用对抗训练的视频预测方法

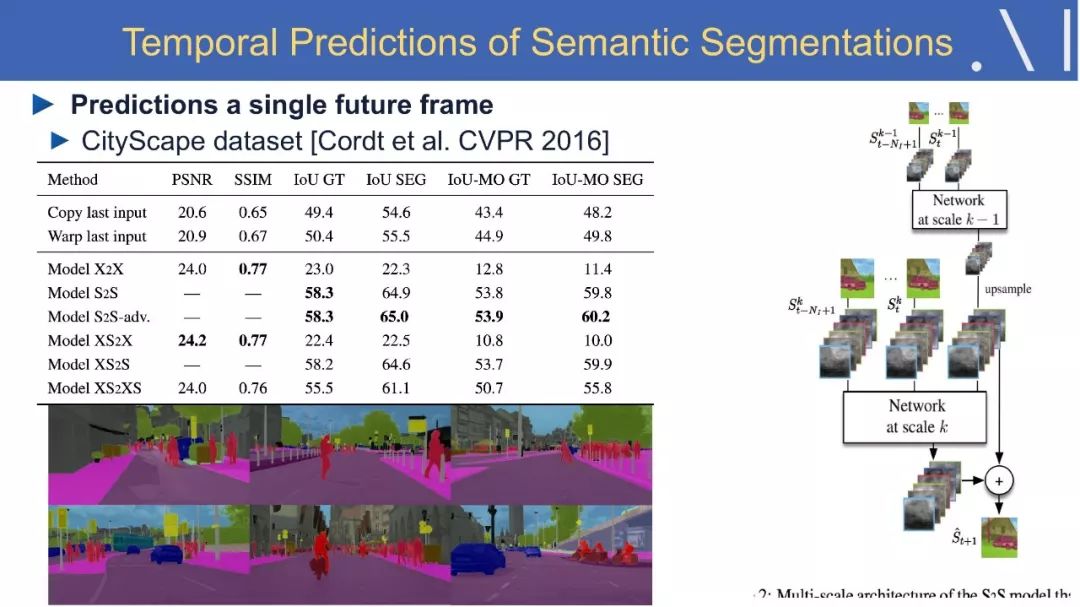
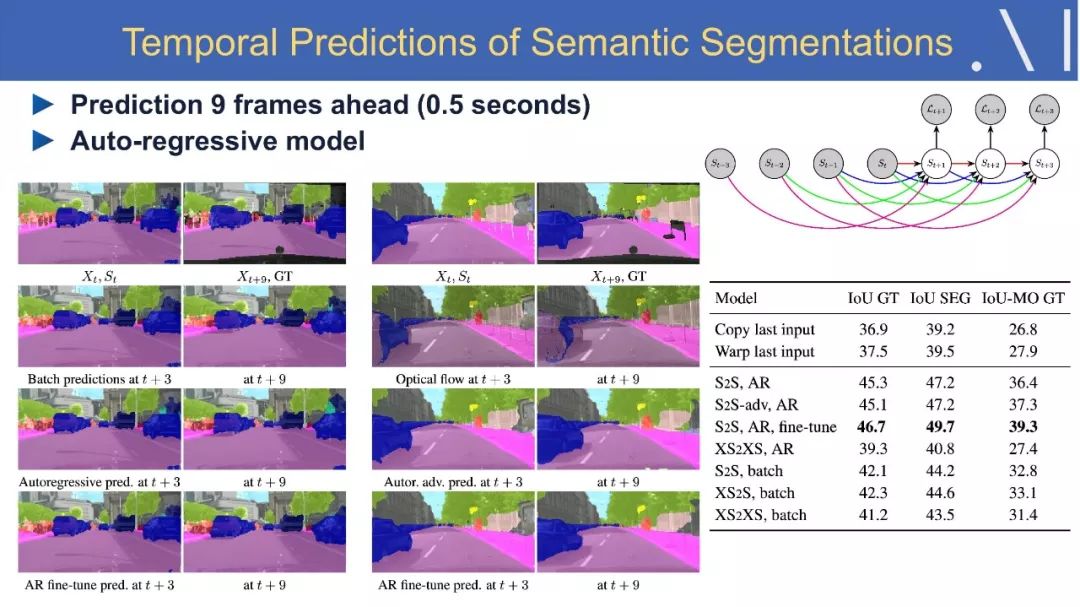
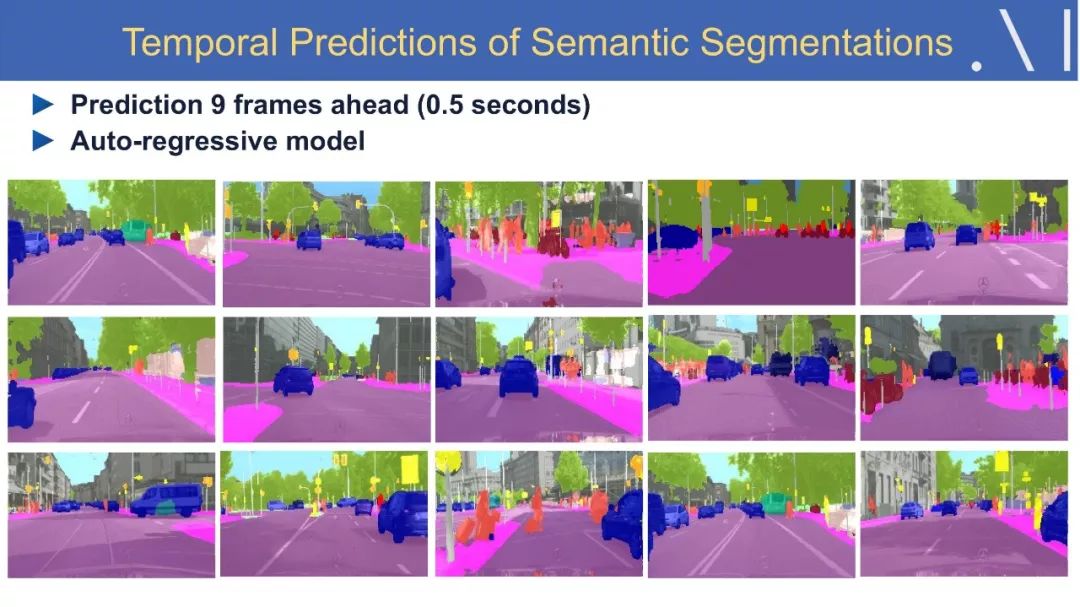
8、语义分割中的视频预测方法

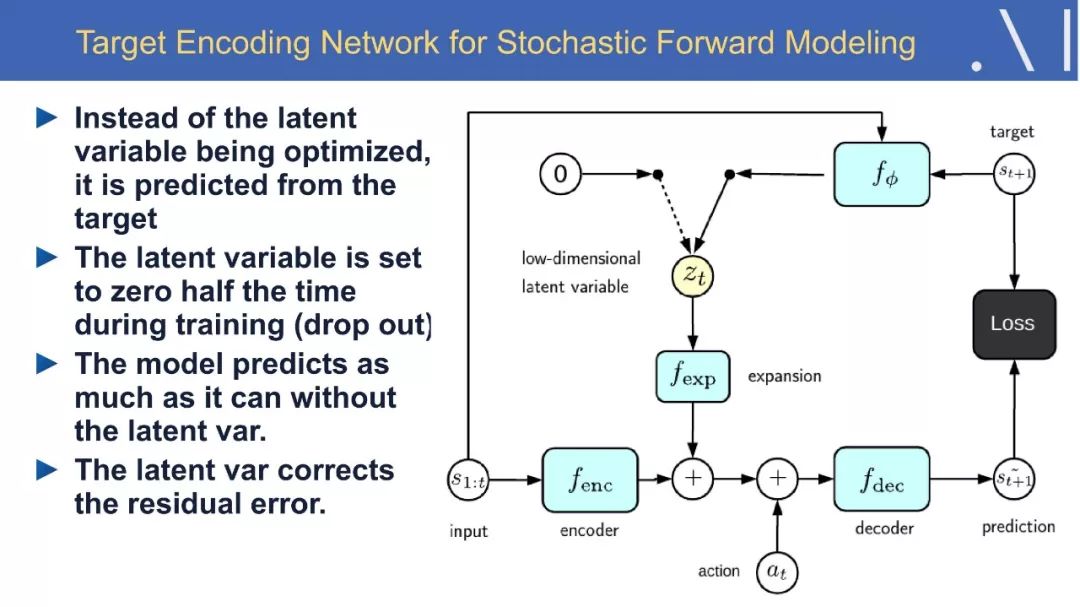
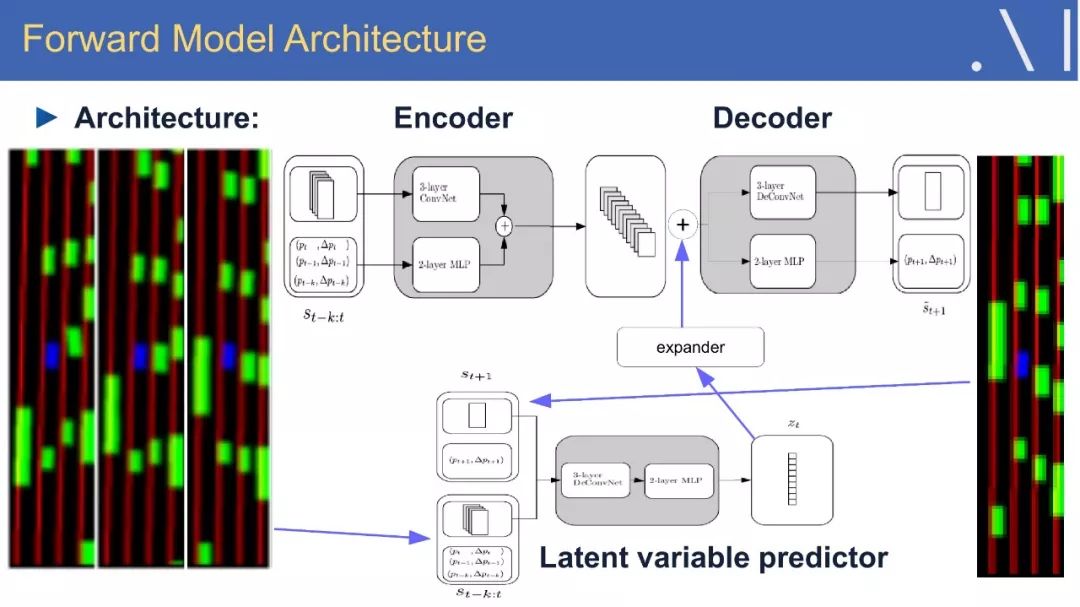
9、Stochastic Latent-Variable Forward Model:目标编码网络

10、AI对未来的影响

内容全文:









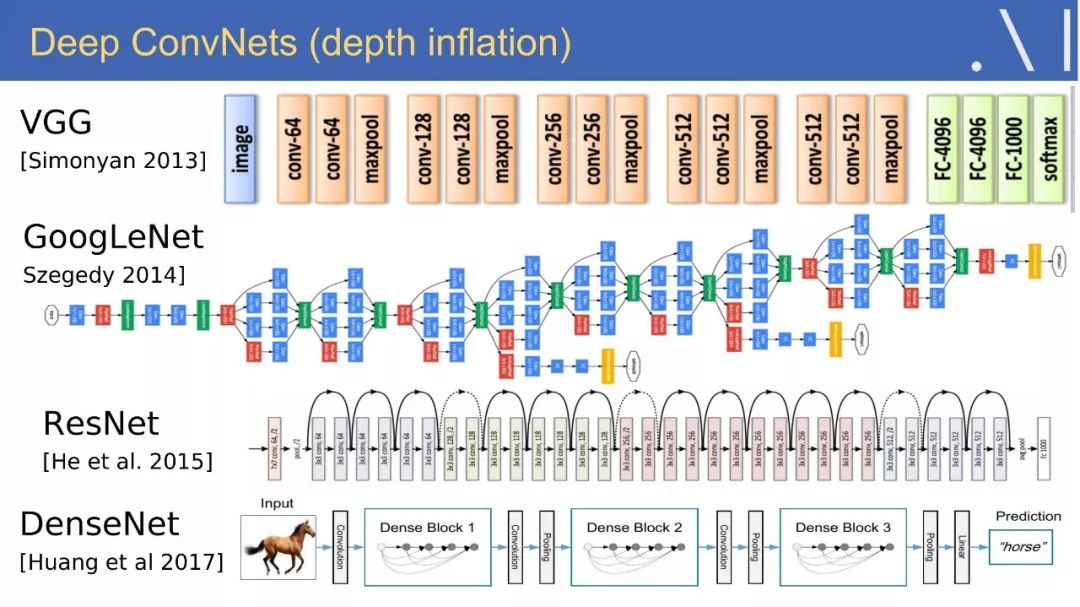
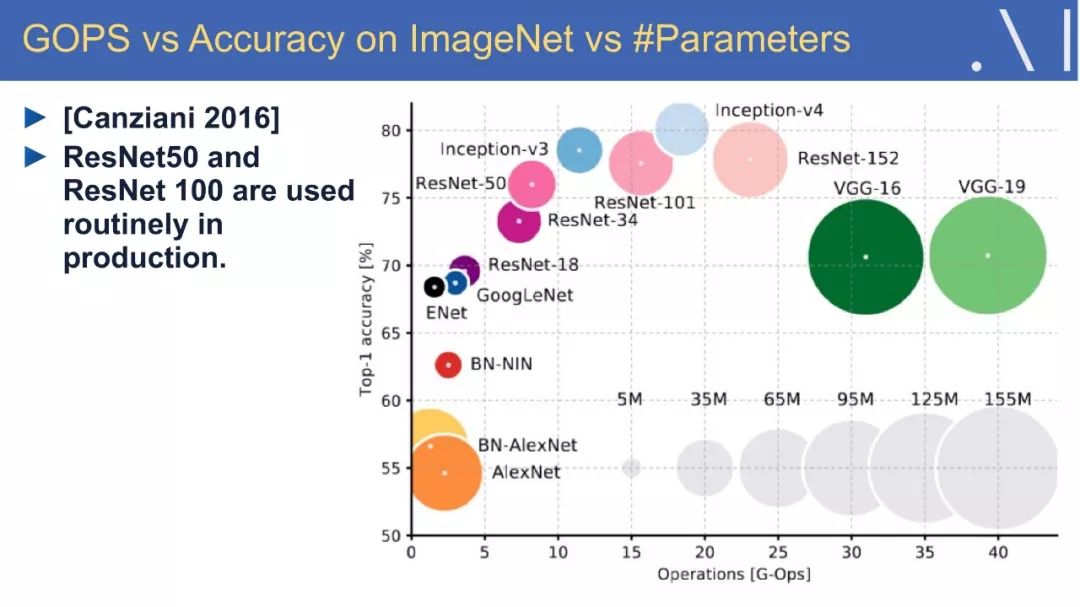

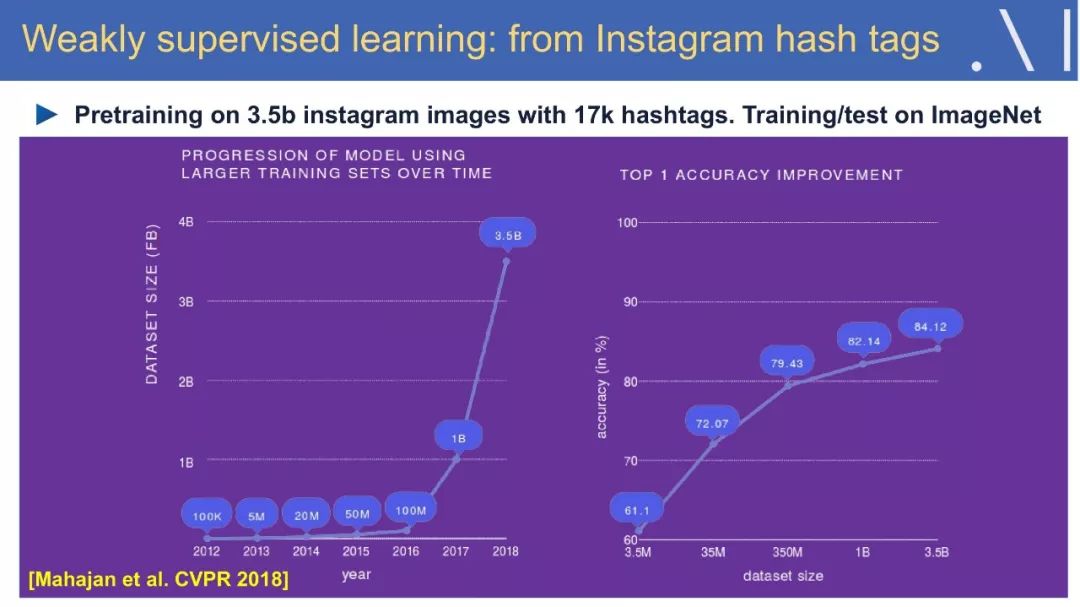
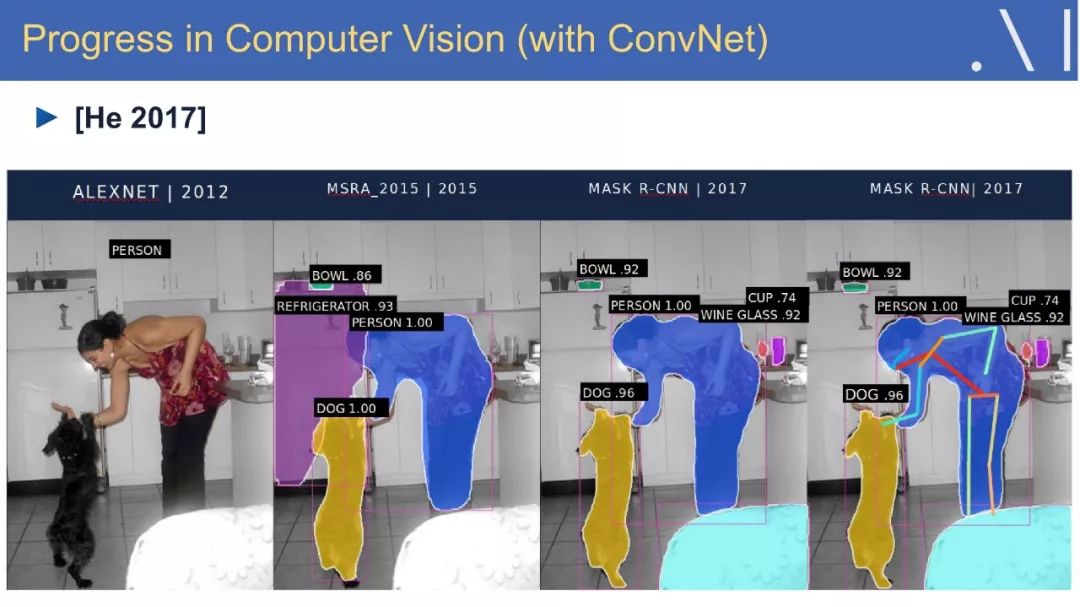



















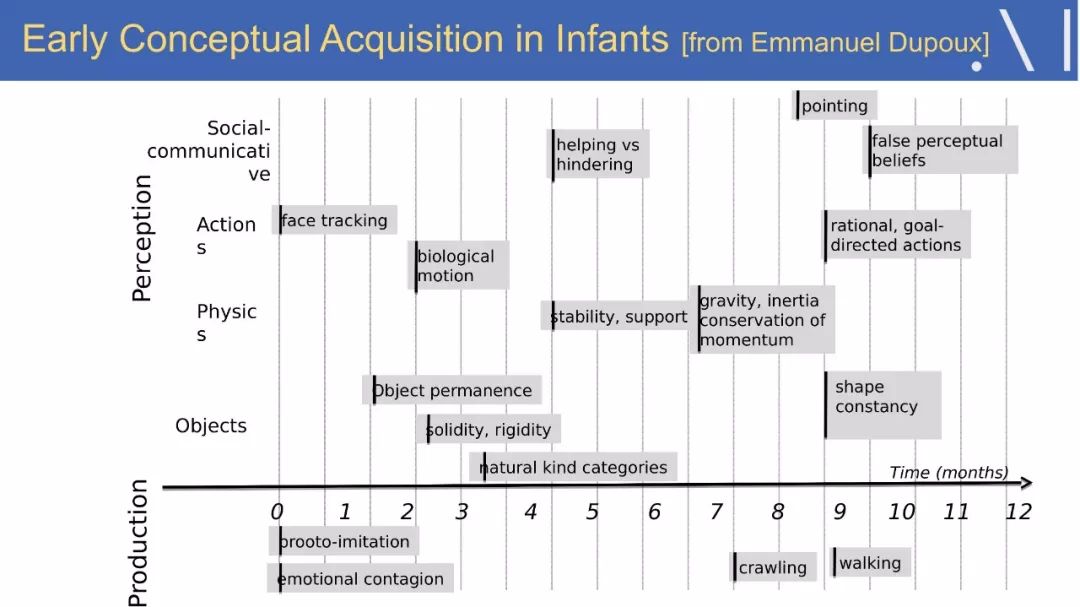

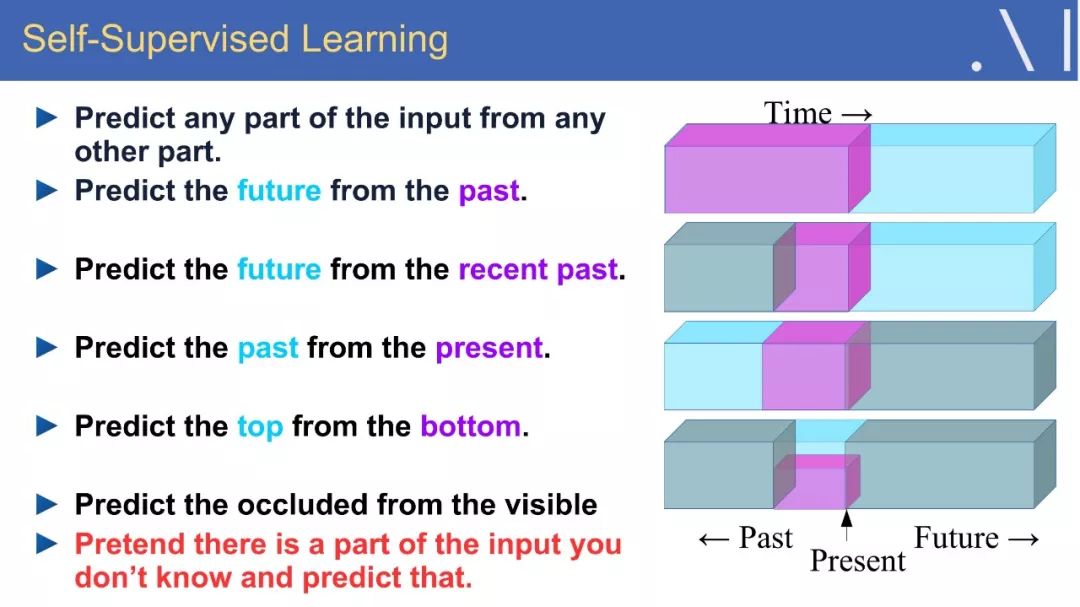

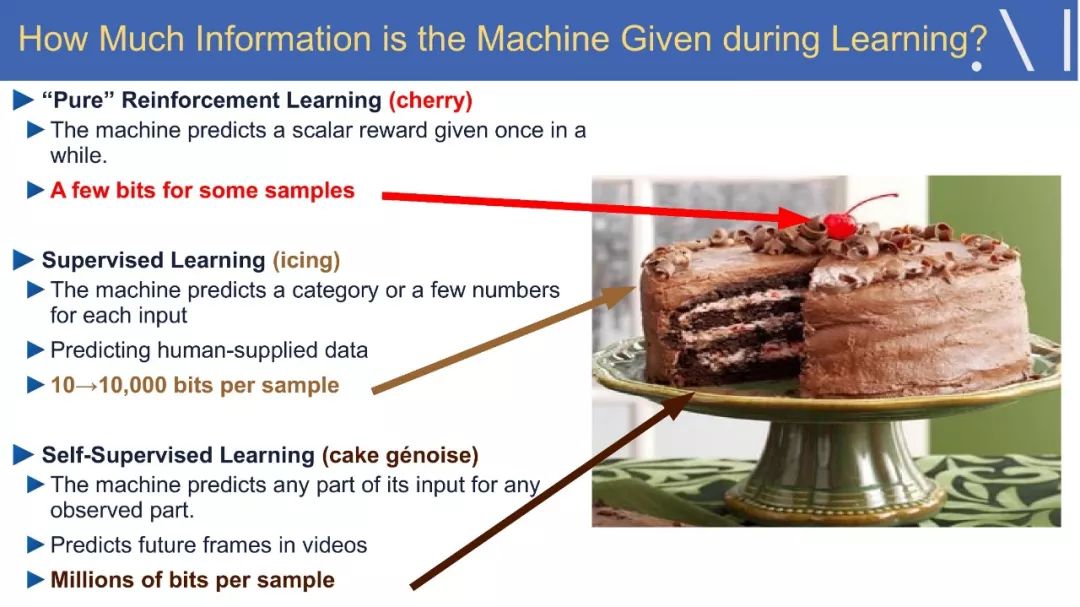





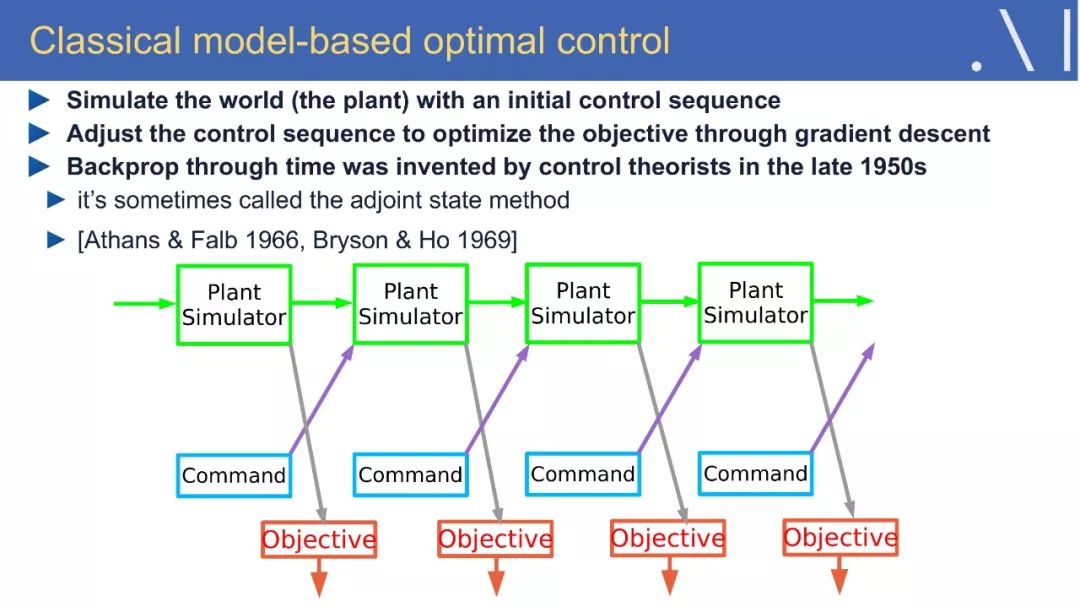


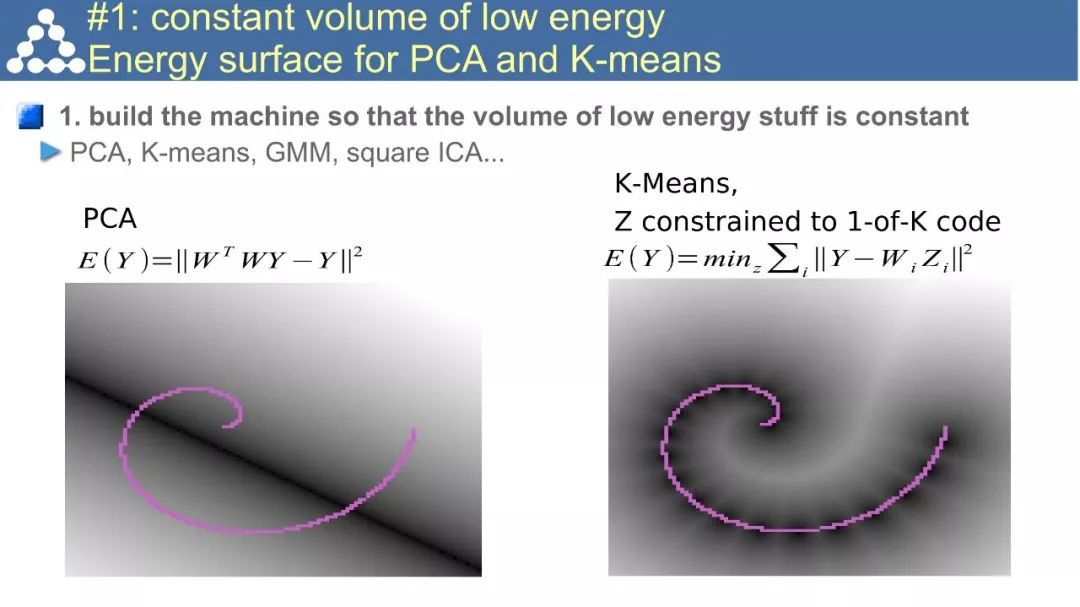
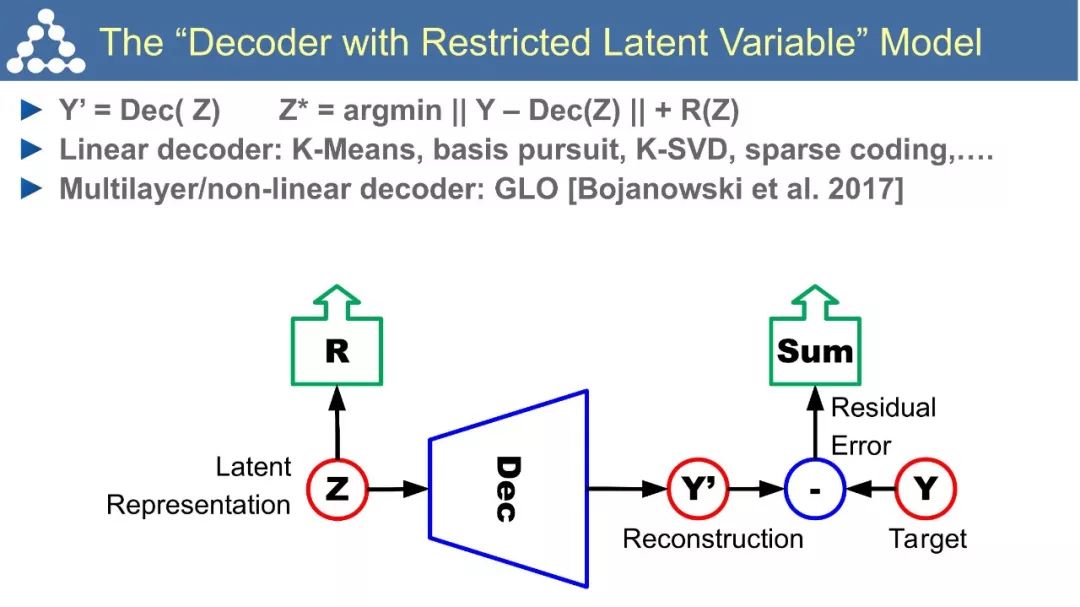
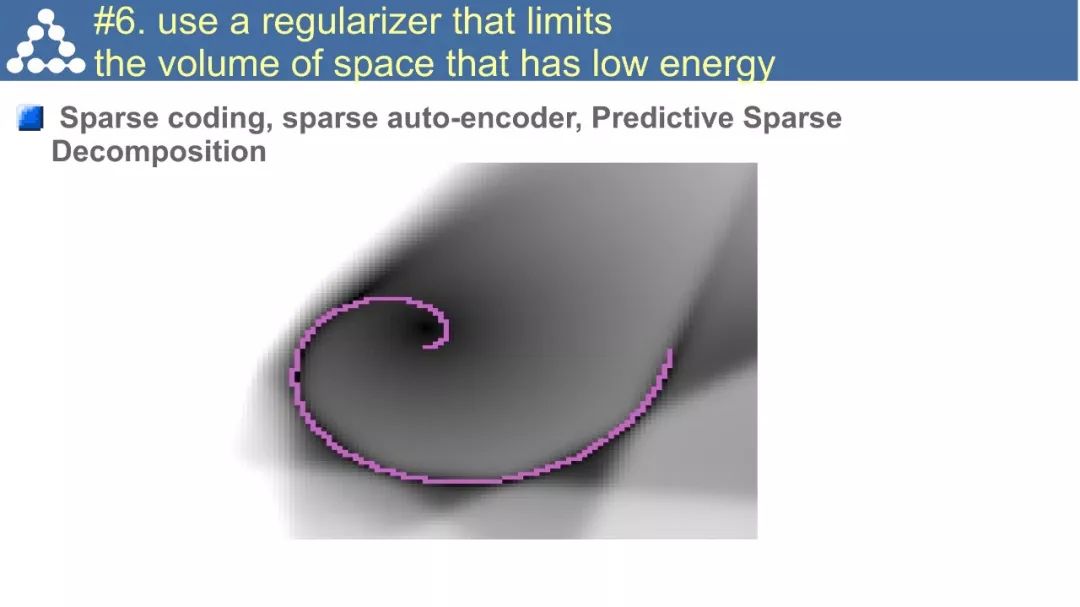
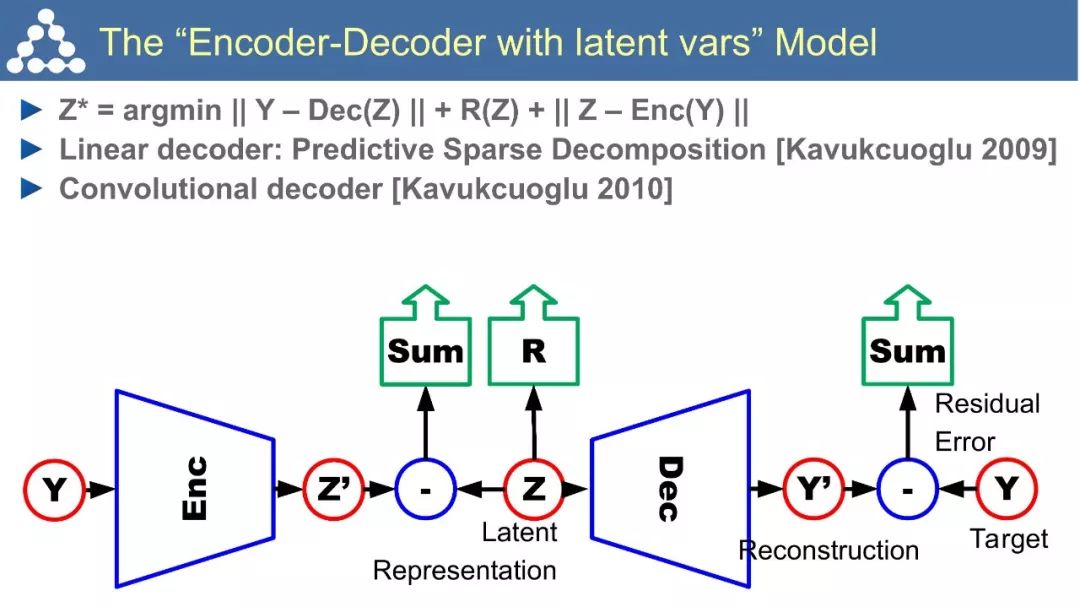














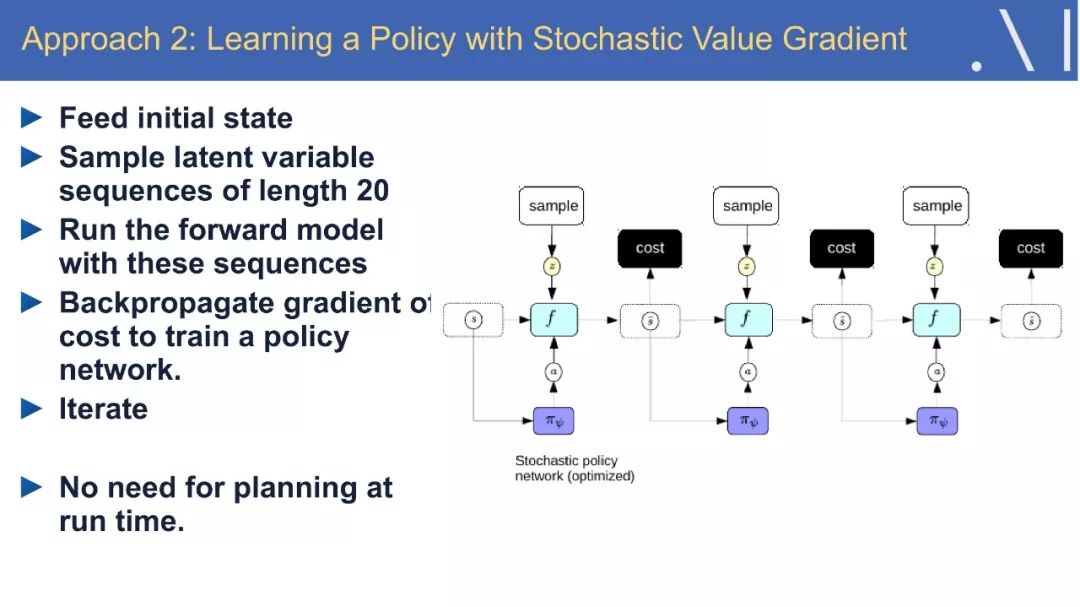
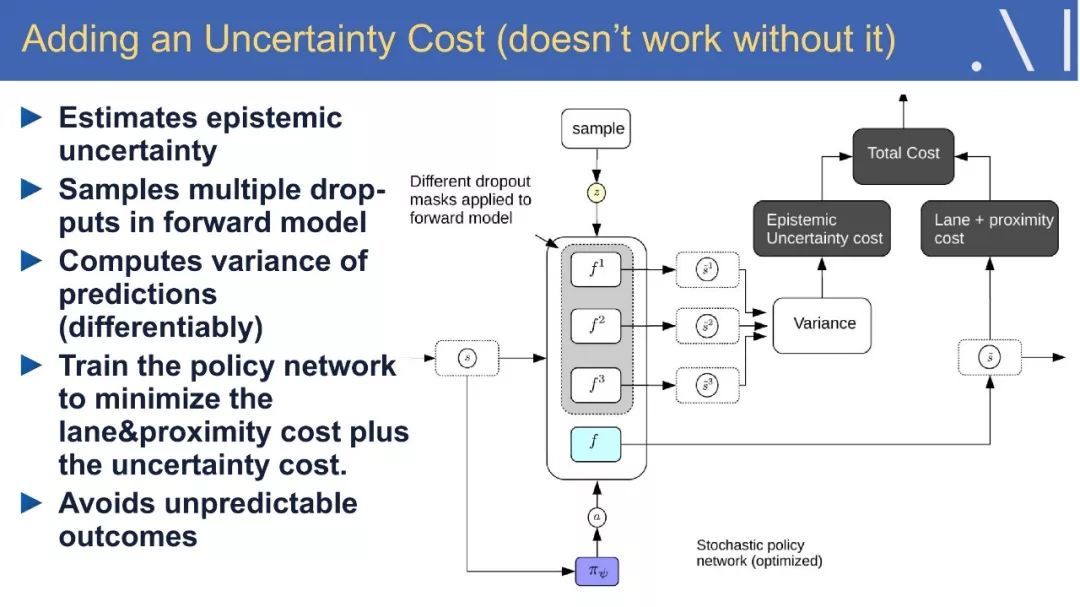

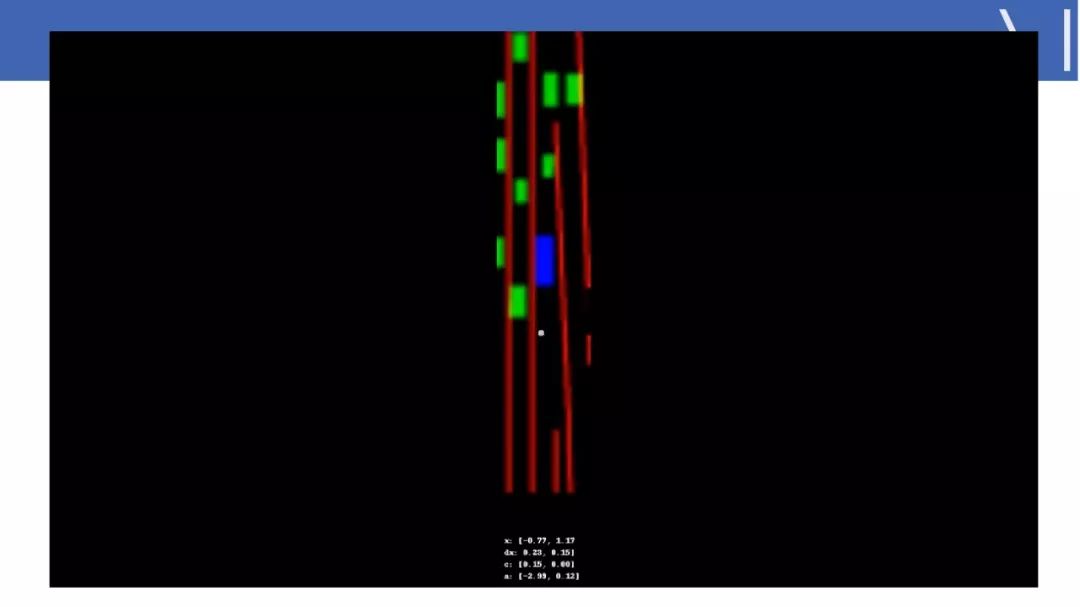






☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得



