【论文推荐】推荐4个NLP任务的论文列表 -- 语法纠错、释义生成、文本可读性、汉字部件
北京语言大学语言监测与智能学习研究小组整理,感兴趣的推荐关注下
疫情当前,这个假期较之以往显得有些特殊。“没有一个冬天不可逾越,没有一个春天不会来临。”在此我们衷心祈愿疫情早日结束,世界人民安康!
面对这个“plus版”的假期,实验室的同学们也管不住自己热爱科研的手,整理出智能语言学习相关的四份论文清单。满满的干货,赶紧收藏吧!
-ONE-
Grammatical Error Correction
语法纠错(GEC, Grammatical Error Correction)是自然语言处理领域一个成熟的话题。随着深度神经网络的发展,国内外学者对此话题的关注变得越来越多。目前,国内外专家学者在语法纠错领域取得了较好的成果,并且构建了一些纠错网站供公众使用。常见的纠错方法主要包括:基于分类的语法纠错方法、基于统计的语法纠错方法以及基于深度学习的语法纠错方法。
目前,语法纠错领域多采用序列生成模型作为主要的研究架构,使用较多的是基于Transformer架构的机器翻译架构。此外也有学者使用RNN、CNN架构,例如利用字母级别的RNN结构的序列生成模型以及attention机制或者结合单词以及字母级别的attention信息,同时纠正句子级别和单词级别的错误,但都未能超过同时期的机器翻译模型。后来的学者们利用字嵌入以及多层卷积构的序列生成模型进行语法纠错,并且获得了远超机器翻译方法所获得的结果。另外,有学者结合统计机器翻译模型,将统计机器翻译的纠正结果送入神经网络中再进行修改,获得了更好的性能。
另一方面,很多学者将提升纠错效果的注意力转移到数据增强上面。利用网络上大量存在的单语数据作为额外的训练数据,或是生成伪平行数据,用以训练网络,取得了较为不错的效果。
这份清单列举了和自动语法纠错任务相关的研究论文,并收集了与此任务有关的数据资源的论文及网站链接。论文列表仍在不断更新,欢迎广大读者提出意见与建议。
整理者:王莹莹、王辰成、周俊宇
Github链接:https://github.com/blcuicall/GEC-Reading-List
-TWO-
Definition Generation
在自然语言处理领域中,词语的分布式向量(word embedding)是一种重要的词表示方法,在许多任务中得到了广泛应用。一般认为,词向量中包含了词语的语义信息,但尚无工作可以明确地指出词向量中有哪些语义信息。另一方面,词典中包含的词语释义直接提供了词语的语义信息。目前,许多研究者借助词典中的释义资源开展了一系列研究。这些研究主要有释义生成、词表示学习、词义消歧、反向词典建模等。
在这些任务中,释义生成与反向词典建模两项任务都是直接借助词典释义资源进行的。释义生成任务是指给定一个词语及其所在上下文,训练模型生成相应的词典释义。该任务自2017年首次提出以来,研究者们在任务的建模方法上开展了许多研究。与释义生成任务相反,反向词典建模任务要求模型在给定词语释义时,找到最符合该释义的词语。另外,利用词典释义进行词表示学习、词义消歧等任务,也都与释义生成任务有很强的相关性。
这份清单整理了和释义生成任务相关的研究论文,并收集了与此任务有关的中文数据资源的论文及网站链接。这份论文列表仍在不断更新,也欢迎广大读者提出意见与建议。
整理者:范齐楠、孔存良
Github链接:https://github.com/blcuicall/DG-Reading-List
-THREE-
Text Readability
文本可读性测量是一种用于评估文本难易的分析方法,近年来广泛应用于各个行业领域的文本难度评估中。尤其是在教育领域,可读性分析可以协助教师有针对性地为学生选择合适的学习材料,或者帮助学生对写作练习进行难易评价。同时,在难度定级、文本简化等任务中,可读性分析也发挥了重要作用。
此份清单整理了与文本可读性任务相关的论文及分析系统,主要包括四个部分:第一部分列出了关于可读性研究综述的相关论文,让读者可以快速地了解其发展历程及研究概况;第二部分列出了可读性研究在汉语和包括英语、德语、意大利语等其他语言中的相关论文,可以帮助读者深入了解可读性分析在不同语言中的特点及研究方法;第三部分介绍了现有的可读性分析工具和系统;第四部分介绍了汉语可读性分析可用的外部资源,这些资源可用于词汇及句法的特征确定及计算。我们希望这份清单可以帮助可读性研究领域的读者迅速入门并开展深入研究。我们将不断更新这一列表,欢迎广大读者提出意见与建议。
整理者:陆天荧
Github链接:https://github.com/blcuicall/TR-Reading-List
-Four-
Chinese Character Component
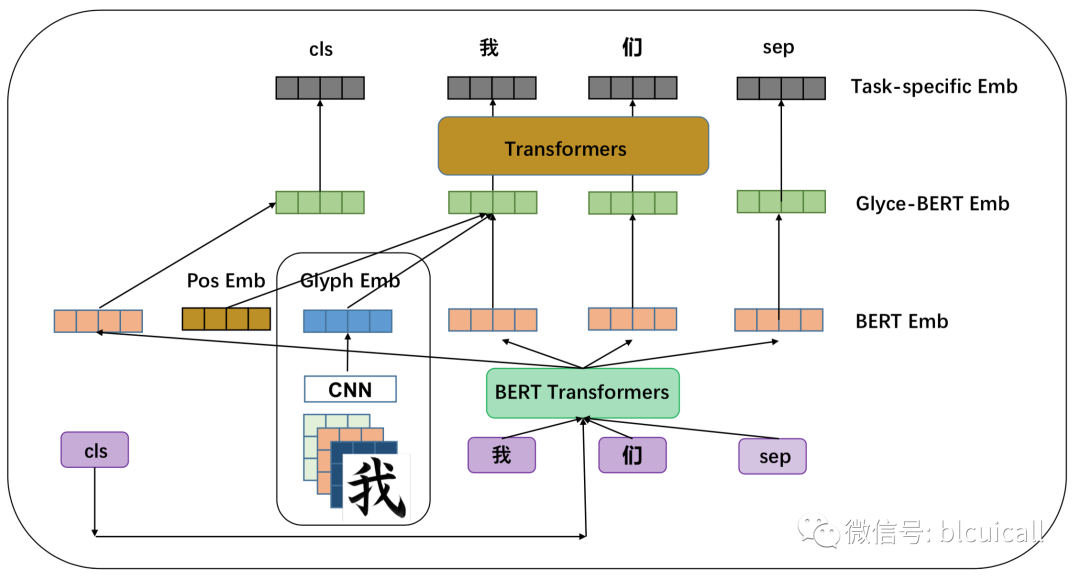
汉字不同于其他表音性的文字,其表义的特殊性质为中文词语的分布式表示提供了另外的可能。其中,部件,作为具有组配汉字功能的构字单位,其具有的表义能力又成为汉语字、词级别的嵌入不可忽视的要素。
这份清单中的论文主要从部件、字、词表示几个角度出发,到分词、词性标注等基础任务,再到文本分类、机器翻译等下游任务,以时间为序,梳理了汉字部件相关的向量表示及具体应用方面的最新研究成果。该论文列表仍在不断更新,欢迎广大读者提出意见与建议。
整理人:孔存良、方雪至
Github链接:
https://github.com/blcuicall/CCC-Reading-List

编辑:谢永慧、罗昕宇

扫码关注我们
BLCU-ICALL
语言监测与智能学习



