
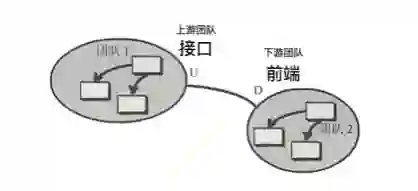
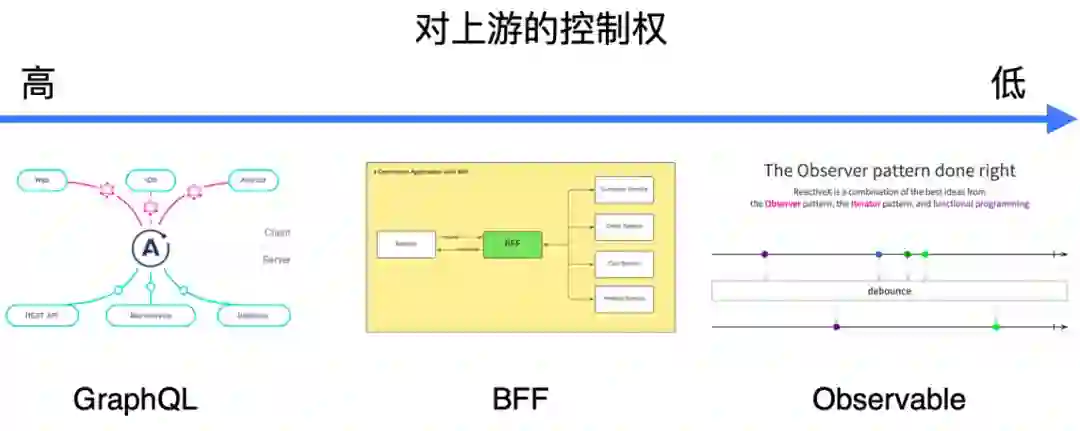
一 困境与难题

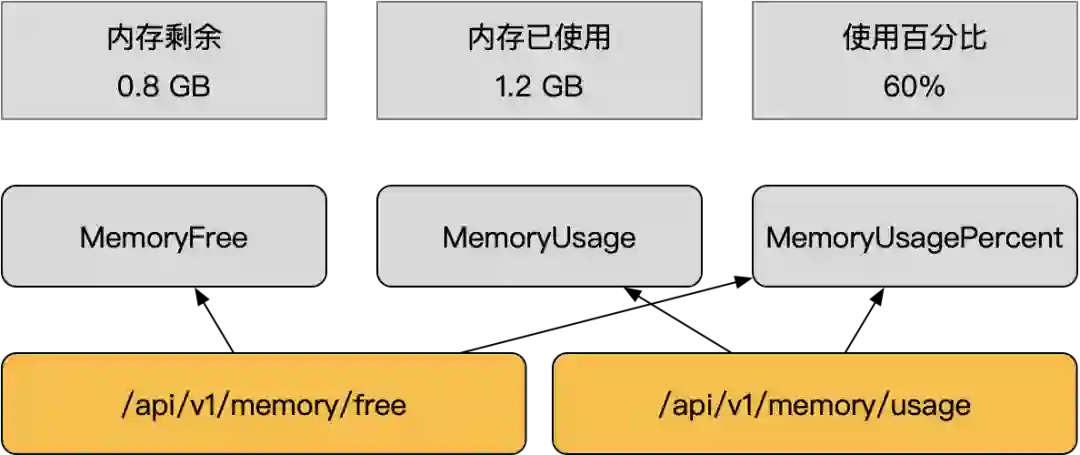
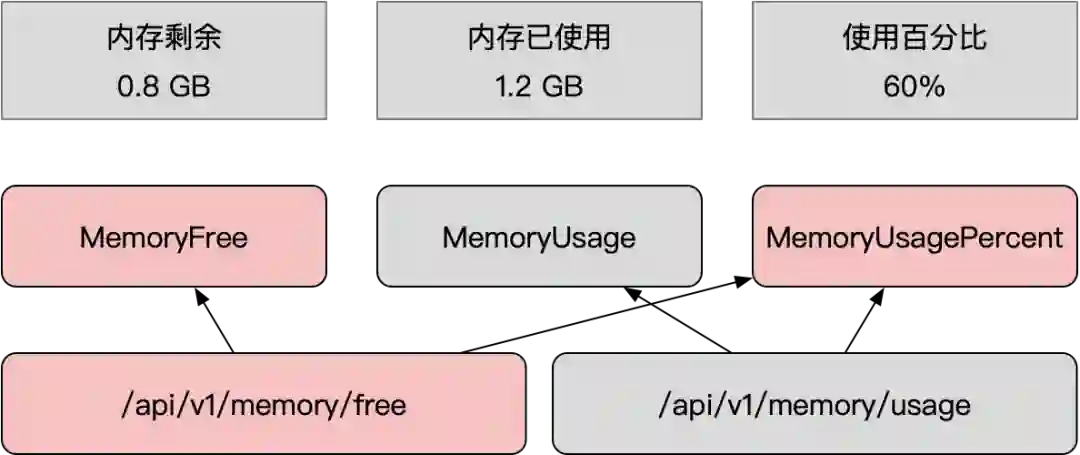
-
返回字段调整 -
调用方式改变
-
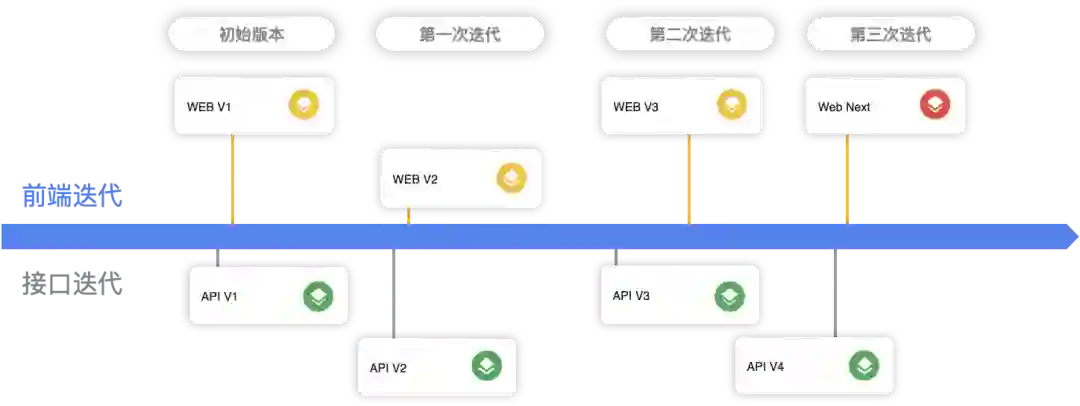
多版本共存使用
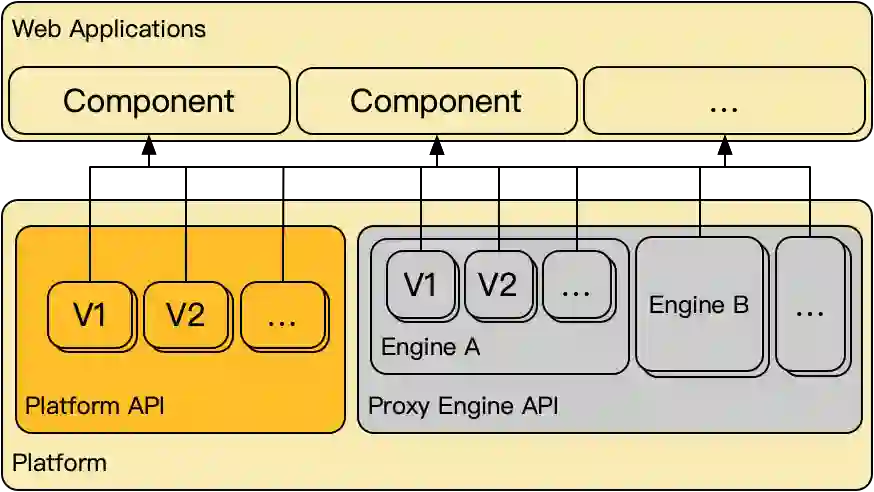
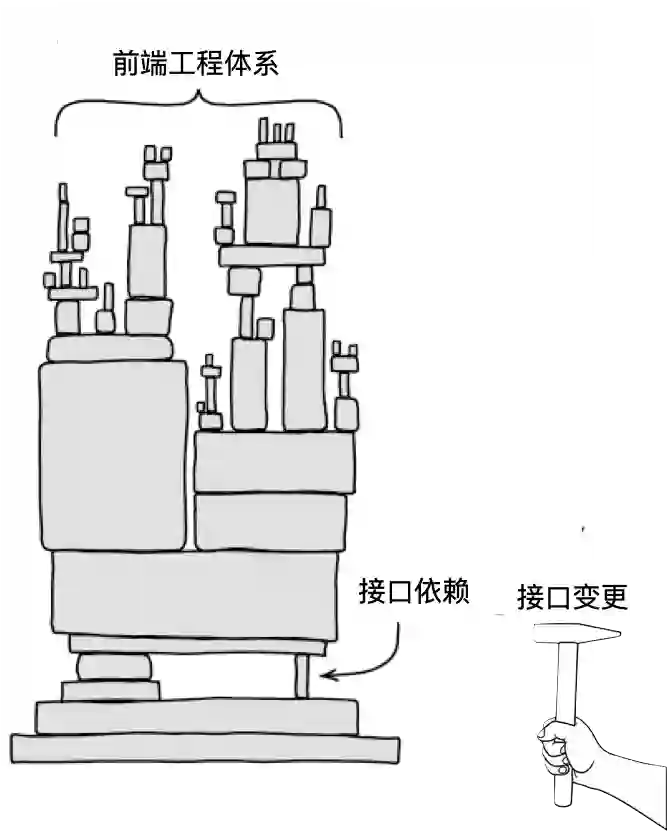
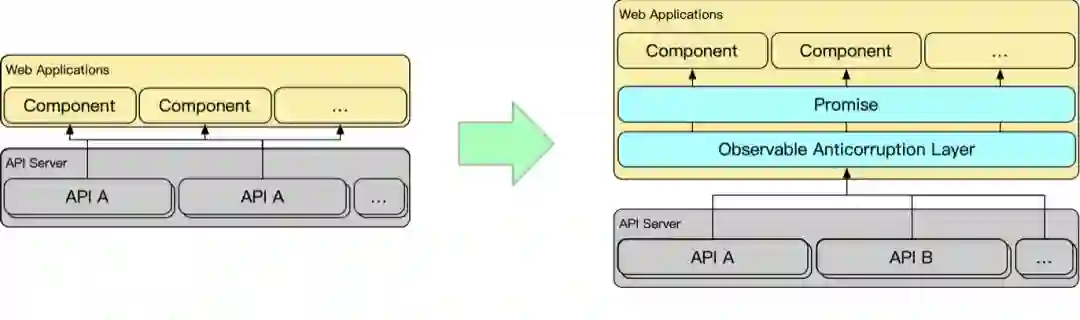
二 防腐层设计

-
统一不同数据源的能力:RxJS 可以将 websocket、http 请求、甚至用户操作、页面点击等转换为统一的 Observable 对象。
-
统一不同类型数据的能力:RxJS 将异步数据和同步数据统一为 Observable 对象。
-
丰富的数据加工能力:RxJS 提供了丰富的 Operator 操作符,可以对 Observable 在订阅前进行预先加工。
-
不入侵前端架构:RxJS 的 Observable 可以与 Promise 互相转换,这意味着 RxJS 的所有概念可以被完整封装在数据层,对视图层可以只暴露 Promise。
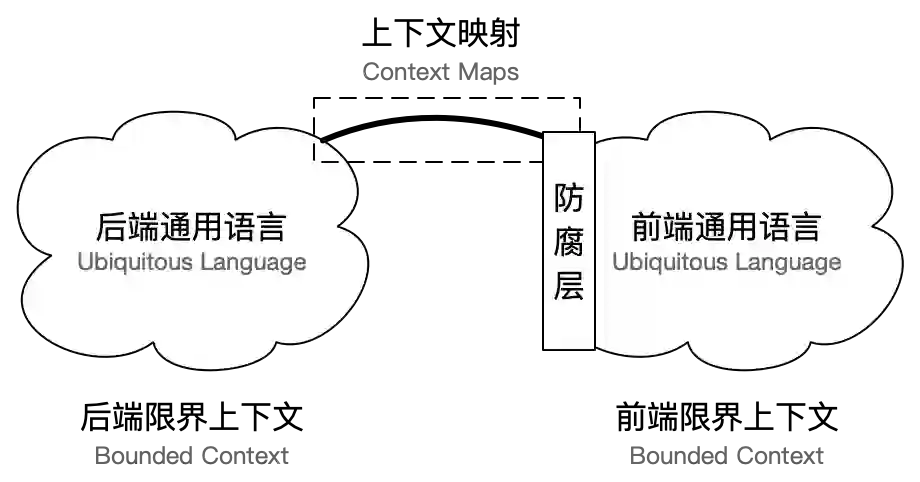
三 防腐层实现
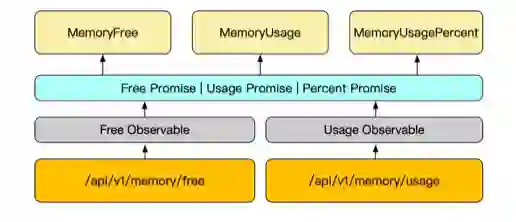
export function getMemoryFreeObservable(): Observable<number> { return fromFetch("/api/v1/memory/free").pipe(mergeMap((res) => res.json()));}
export function getMemoryUsageObservable(): Observable<number> { return fromFetch("/api/v1/memory/usage").pipe(mergeMap((res) => res.json()));}
export function getMemoryUsagePercent(): Promise<number> { return lastValueFrom(forkJoin([getMemoryFreeObservable(), getMemoryUsageObservable()]).pipe( map(([usage, free]) => +((usage / (usage + free)) * 100).toFixed(2)) ));}
export function getMemoryFree(): Promise<number> { return lastValueFrom(getMemoryFreeObservable());}
export function getMemoryUsage(): Promise<number> { return lastValueFrom(getMemoryUsageObservable());}
function MemoryUsagePercent() { const [usage, setUsage] = useState<number>(0); useEffect(() => { (async () => { const result = await getMemoryUsagePercent(); setUsage(result); })(); }, []); return <div>Usage: {usage} %</div>;}
export default MemoryUsagePercent;
1 返回字段调整
{ requestId: string; data: number;}
export function getMemoryUsageObservable(): Observable<number> { return fromFetch("/api/v2/memory/free").pipe( mergeMap((res) => res.json()),+ map((data) => data.data) );}
export function getMemoryUsageObservable(): Observable<number> { return fromFetch("/api/v2/memory/usage").pipe( mergeMap((res) => res.json()),+ map((data) => data.data) );}

2 调用方式改变
当调用方式发生改变时,防腐层同样可以发挥作用。/api/v3/memory 直接返回了 free 与 usage 的数据,接口格式如下。
{requestId: string;data: {free: number;usage: number;}}
防腐层代码只需要进行如下更新,就可以保障组件层代码无需修改。
export function getMemoryObservable(): Observable<{ free: number; usage: number }> {return fromFetch("/api/v3/memory").pipe(mergeMap((res) => res.json()),map((data) => data.data));}export function getMemoryFreeObservable(): Observable<number> {return getMemoryObservable().pipe(map((data) => data.free));}export function getMemoryUsageObservable(): Observable<number> {return getMemoryObservable().pipe(map((data) => data.usage));}export function getMemoryUsagePercent(): Promise<number> {return lastValue(getMemoryObservable().pipe(map(({ usage, free }) => +((usage / (usage + free)) * 100).toFixed(2))));}
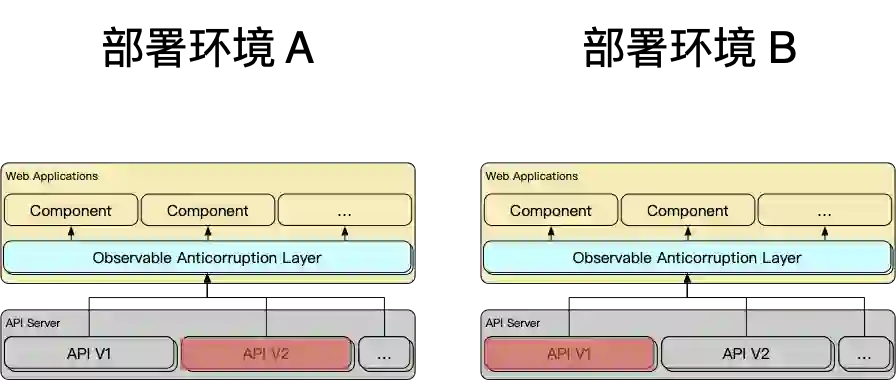
3 多版本共存使用
当前端代码需要在多套环境下部署时,部分环境下 v3 的接口可用,而部分环境下只有 v2 的接口部署,此时我们依然可以在防腐层屏蔽环境的差异。
export function getMemoryLegacyObservable(): Observable<{ free: number; usage: number }> {const legacyUsage = fromFetch("/api/v2/memory/usage").pipe(mergeMap((res) => res.json()));const legacyFree = fromFetch("/api/v2/memory/free").pipe(mergeMap((res) => res.json()));return forkJoin([legacyUsage, legacyFree], (usage, free) => ({free: free.data.free,usage: usage.data.usage,}));}export function getMemoryObservable(): Observable<{ free: number; usage: number }> {const current = fromFetch("/api/v3/memory").pipe(mergeMap((res) => res.json()),map((data) => data.data));return race(getMemoryLegacyObservable(), current);}export function getMemoryFreeObservable(): Observable<number> {return getMemoryObservable().pipe(map((data) => data.free));}export function getMemoryUsageObservable(): Observable<number> {return getMemoryObservable().pipe(map((data) => data.usage));}export function getMemoryUsagePercent(): Promise<number> {return lastValue(getMemory().pipe(map(({ usage, free }) => +((usage / (usage + free)) * 100).toFixed(2))));}
通过 race 操作符,当 v2 与 v3 任何一个版本的接口可用时,防腐层都可以正常工作,在组件层无需再关注接口受环境的影响。
四 额外应用
防腐层不仅仅是多了一层对接口的封装与隔离,它还能起到以下作用。
1 概念映射
接口语义与前端需要数据的语义有时并不能完全对应,当在组件层直接调用接口时,所有开发者都需要对接口与界面的语义映射足够了解。有了防腐层后,防腐层提供的调用方法包含了数据的真实语义,减少了开发者的二次理解成本。
2 格式适配
在很多情况下,接口返回的数据结构与格式与前端需要的数据格式并不符合,通过在防腐层增加数据转换逻辑,可以降低接口数据对业务代码的入侵。在以上的案例里,我们封装了 getMemoryUsagePercent 的数据返回,使得组件层可以直接使用百分比数据,而不需要再次进行转换。
3 接口缓存
对于多种业务依赖同一接口的情况,我们可以通过防腐层增加缓存逻辑,从而有效降低接口的调用压力。
与格式适配类似,将缓存逻辑封装在防腐层可以避免组件层对数据的二次缓存,并可以对缓存数据集中管理,降低代码的复杂度,一个简单的缓存示例如下。
class CacheService {private cache: { [key: string]: any } = {};getData() {if (this.cache) {return of(this.cache);} else {return fromFetch("/api/v3/memory").pipe(mergeMap((res) => res.json()),map((data) => data.data),tap((data) => {this.cache = data;}));}}}
4 稳定性兜底
当接口稳定性较差时,通常的做法是在组件层对 response error 的情况进行处理,这种兜底逻辑通常比较复杂,组件层的维护成本会很高。我们可以通过防腐层对稳定性进行兜底,当接口出错时可以返回兜底业务数据,由于兜底数据统一维护在防腐层,后续的测试与修改也会更加方便。在上文中的多版本共存的防腐层中,增加以下代码,此时即使 v2 和 v3 接口都无法返回数据,前端仍然可以保持可用。
return race(getMemoryLegacy(), current).pipe(+ catchError(() => of({ usage: '-', free: '-' })));
5 联调与测试
接口和前端可能会存在并行开发的状态,此时,前端的开发并没有真实的后端接口可用。与传统的搭建 mock api 的方式相比,在防腐层直接对数据进行 mock 是更方便的方案。
export function getMemoryFree(): Observable<number> {return of(0.8);}export function getMemoryUsage(): Observable<number> {return of(1.2);}export function getMemoryUsagePercent(): Observable<number> {return forkJoin([getMemoryUsage(), getMemoryFree()]).pipe(map(([usage, free]) => +((usage / (usage + free)) * 100).toFixed(2)));}
在防腐层对数据进行 mock 也可以用于对页面的测试,例如 mock 大量数据对页面性能影响。
export function getLargeList(): Observable<string[]> {const options = [];for (let i = 0; i < 100000; i++) {const value = `${i.toString(36)}${i}`;options.push(value);}return of(options);}
五 总结
在本文中我们介绍了以下内容:
前端面对接口频繁变动时的困境及原因如何
防腐层的设计思想与技术选型
使用 Observable 实现防腐层的代码示例
防腐层的额外作用
请读者注意,只在特定的场景下引入前端防腐层才是合理的,即前端处于跟随者或供应商/客户关系中,且面临大量接口无法保障稳定和兼容。如果在防腐层可以在后端 Gateway 构建,或者接口数量较少时,引入防腐层带来的额外成本会大于其带来的好处。
RxJS 在防腐层构建场景下提供的更多的是 Observable 化的能力,如果读者不需要复杂的 operators 转换工具,也可以自行构建 Observable 构建方案,事实上只需要 100 行的代码就可以实现 https://stackblitz.com/edit/mini-rxjs。
改造后的前端架构将不再直接依赖接口实现,不会入侵现有前端数据层设计,还可以承担概念映射、格式适配、接口缓存、稳定性兜底以及协助联调测试等工作。文中所有的示例代码都可以在仓库 https://github.com/vthinkxie/rxjs-acl 获得。




