基于自监督的联合时间域迁移,轻松解决长视频的时空差异问题 |CVPR 2020

编辑 | 丛 末

研究背景
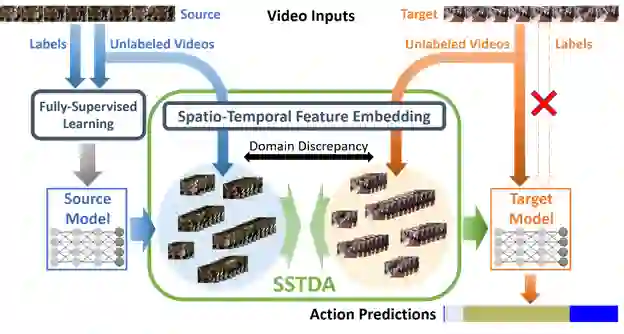
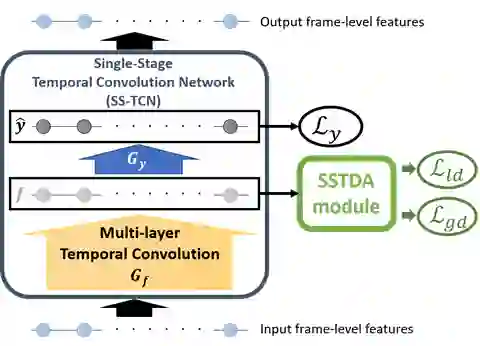
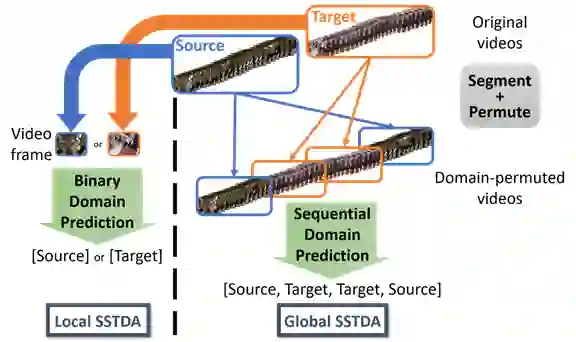
技术方法

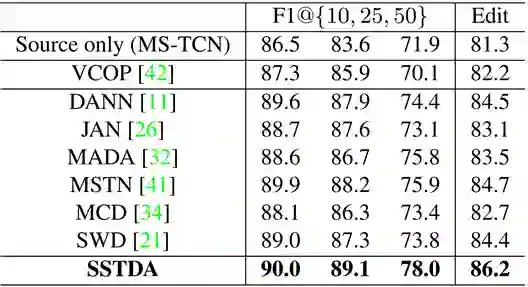
实验结果
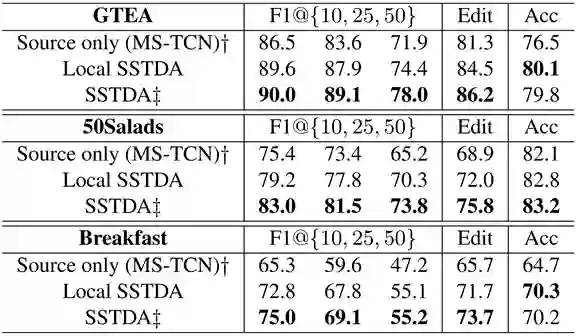
结论


登录查看更多
相关内容
Arxiv
12+阅读 · 2020年6月10日



相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2020年6月10日