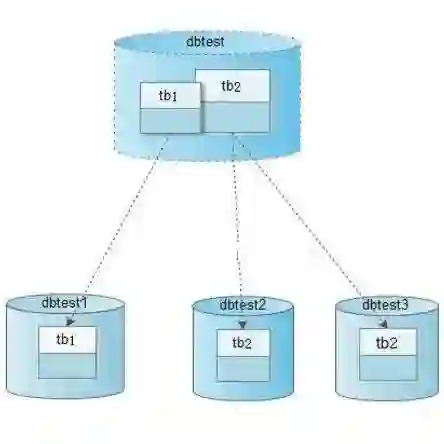
数据库拆分
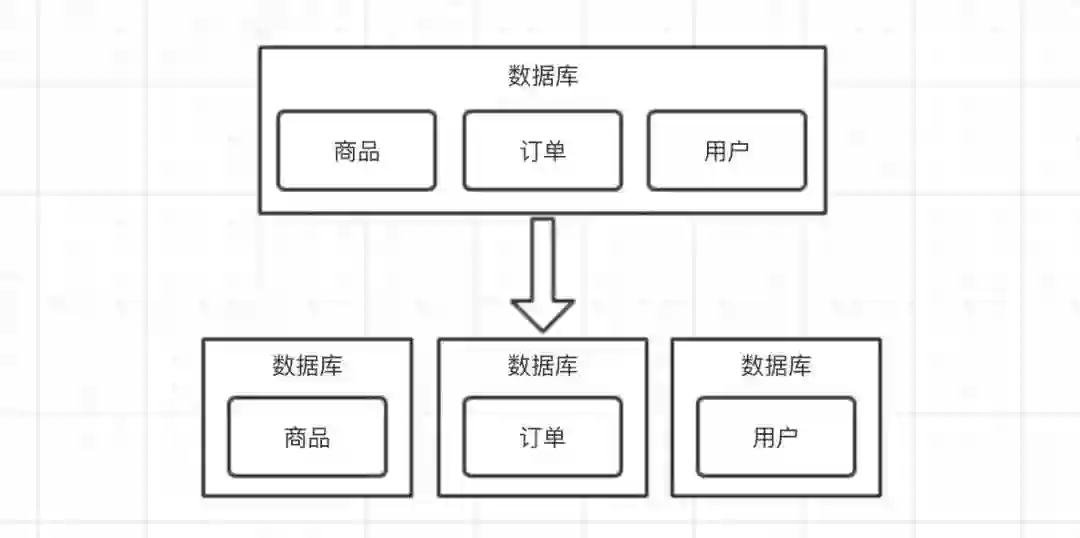
分库,按照业务维度进行拆分,可以解决多个表之间的 IO 竞争、单机容量问题。
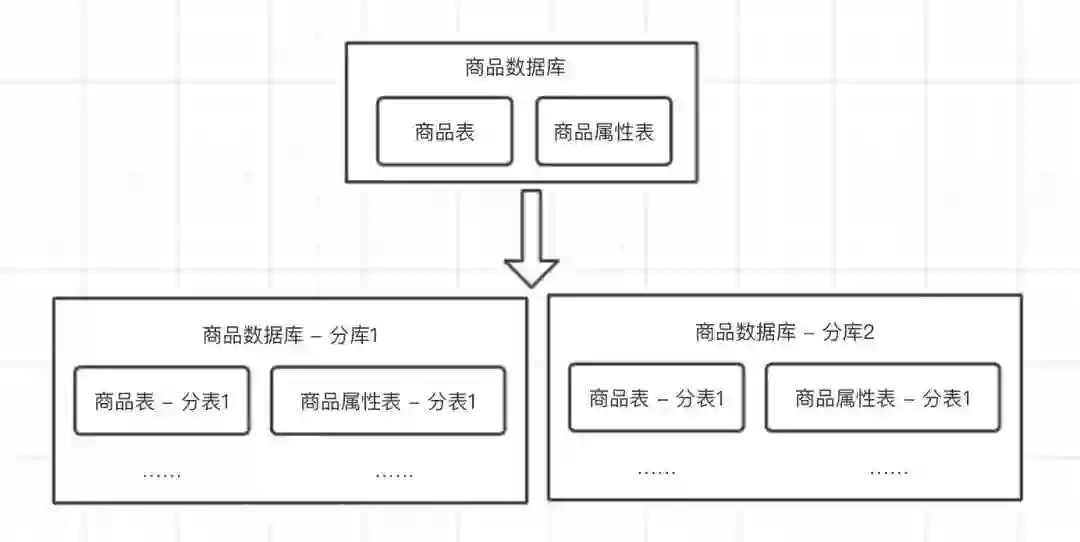
分表,对单表数据进行拆分,解决容量、磁盘/带宽 IO 压力。
什么时候拆分?
数据库拆分可以带来好处,例如:
便于水平扩容。
提升查询性能,因为某些查询如果在单一的巨型表中可能需要扫描的行数很多,而在分表中查询所涉及的行很少。
提升可用性,因为如果是单一的库,出现问题时会影响整个应用,而拆分后某块儿出现问题不会影响整体。
但拆分也会带来一些坏处,例如:
增加了开发、维度的复杂度。
拆分后数据库原本支持的一些功能就不可用了,例如 join、事务,后面还会细说。
所以,拆分要慎重,需要拆分的场景通常有以下几个:
数据的增长超出了单库存储能力。
数据读写的量太大,超出了单节点或者主从结构的掌控能力,导致响应时间变慢。
网络带宽压力过大,导致数据返回过慢,甚至超时。
数据拆分方式
(1)基于 key
对指定的key进行hash计算,得到一个数字,这个值就是所在的分片。
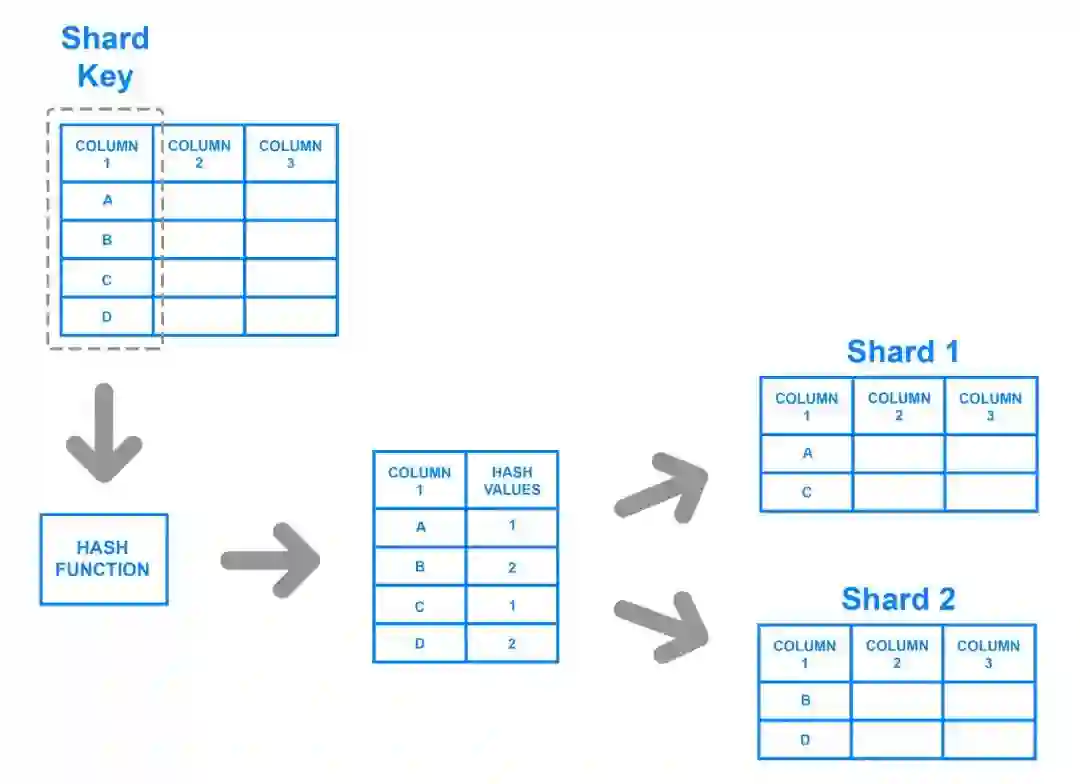
这种方式很常用,无需维护数据与分片的映射关系,而且分布较为均匀,没有热点问题,不便之处在于服务器的增减场景,那时就需要重新计算来分配已有数据了。
(2)基于值范围
例如某列是数值形式(如价格),那么就可以按值的范围划分。
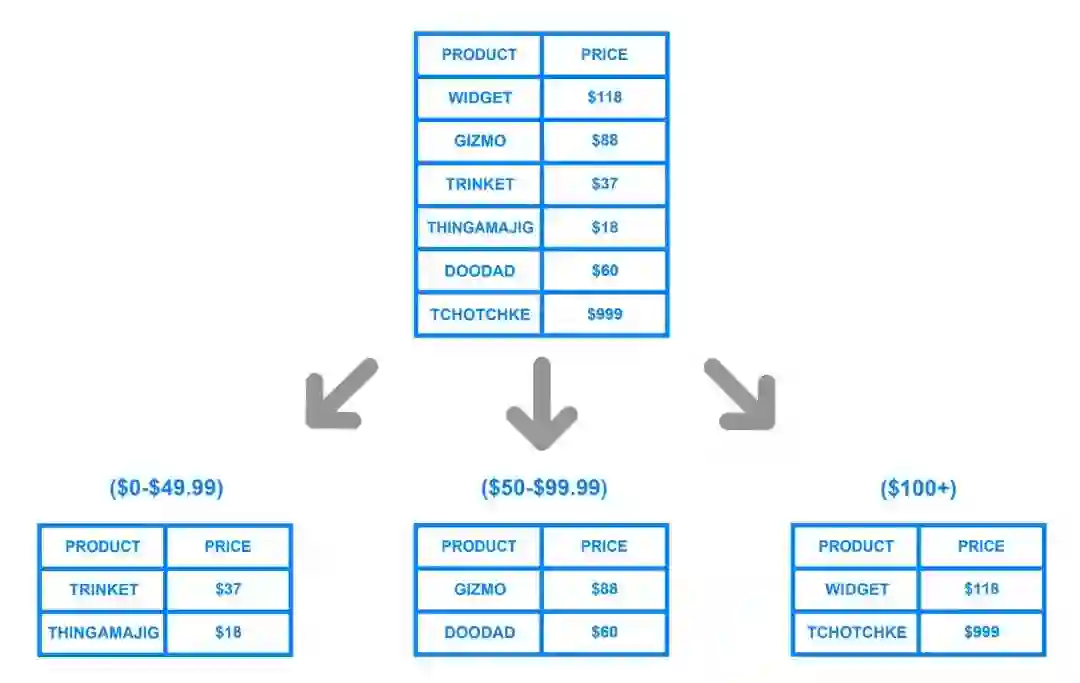
这种方式实现非常简单,但极有可能出现热点问题,数据集中在某个分片中,导致各服务器操作失衡。
(3)字典方式
创建维护一个数据字典表,根据指定的key到字典表中查看其在哪个分片上。
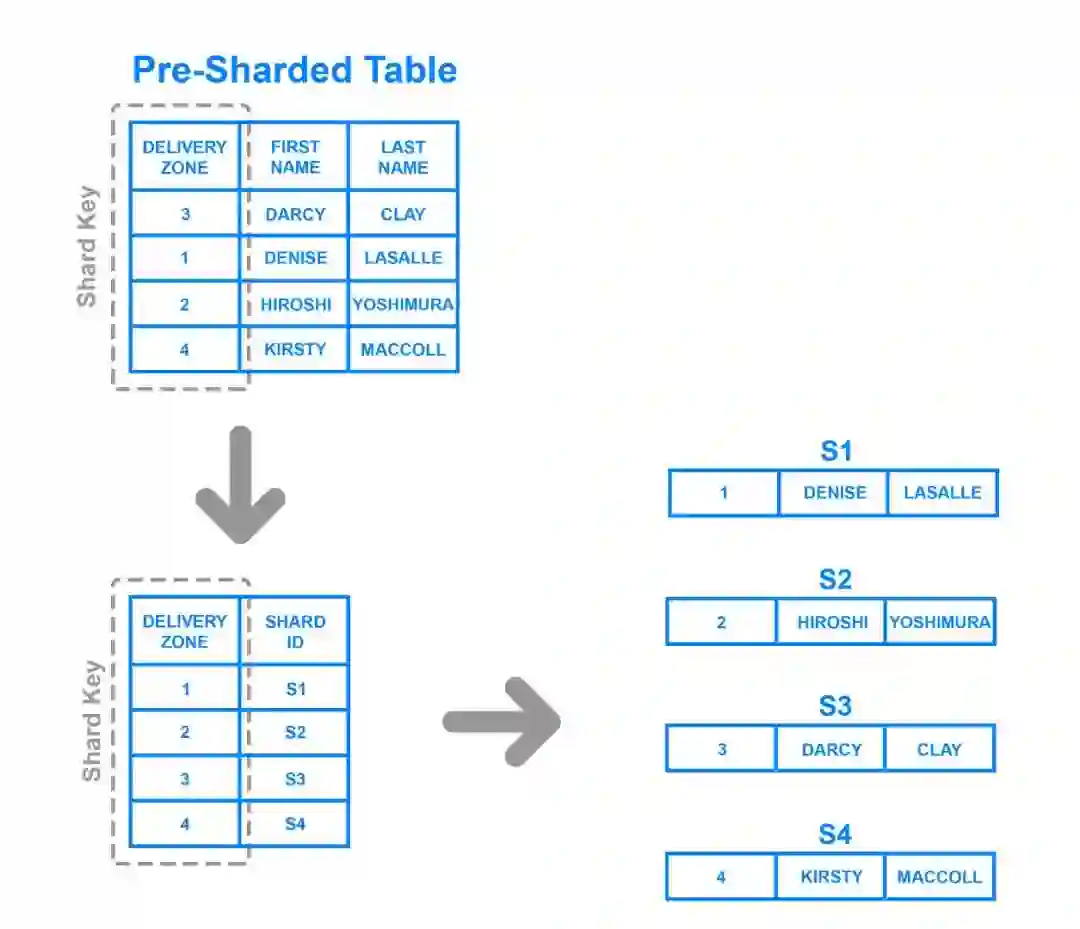
这种方式最大的好处是 灵活,可以随意指定数据位置,动态增减服务器也很方便。缺点就是总需要查询字典表,是一个性能瓶颈,而且存在单点风险。
拆分带来哪些问题?
下面是数据库拆分后的主要问题及解决思路:
1. 自增ID问题
可以通过不同表、不同自增步长、分布式ID生成器来解决。
2. 跨库/跨表 join 和排序分页问题
可以对所有表扫描后聚合,或者生成全局表,或者进行查询维度的数据异构,或者数据同步到 ES 搜索。
3. 分布式事务问题
对于一些问题,我们可以考虑 NoSQL 数据库,与关系数据库互补来解决问题。
点击👇阅读原文,查看文章列表