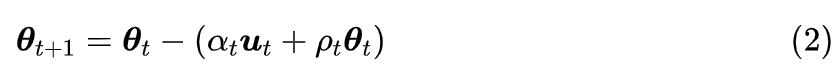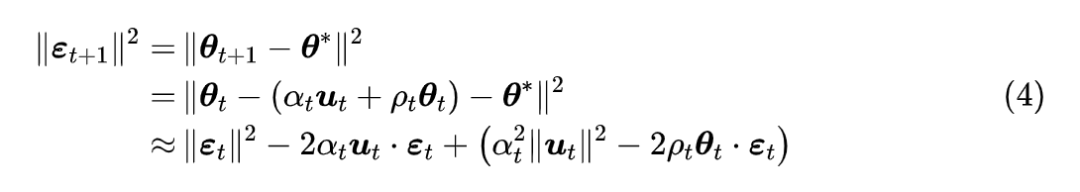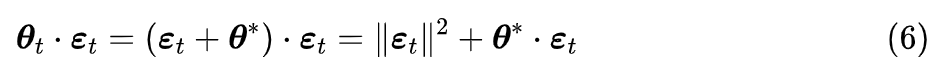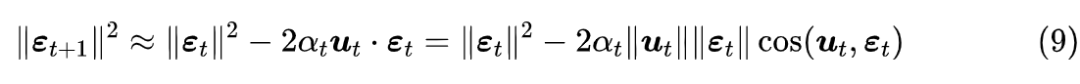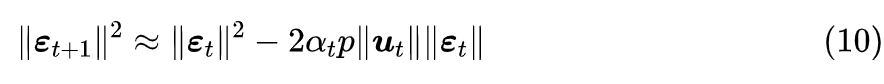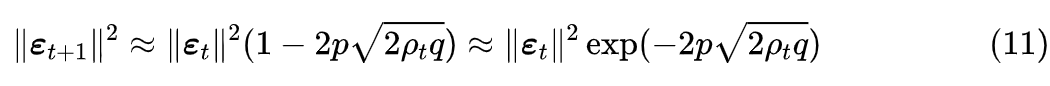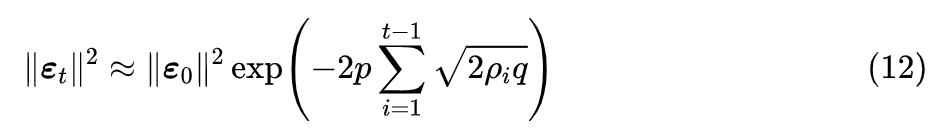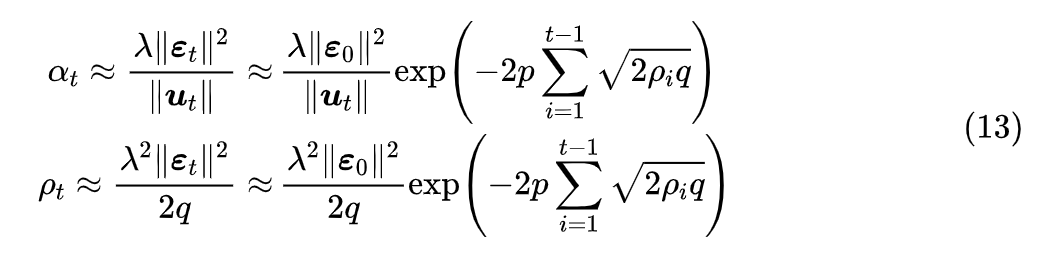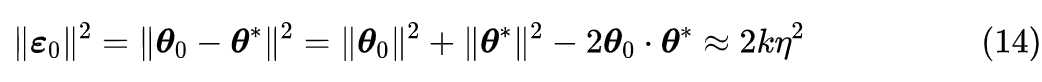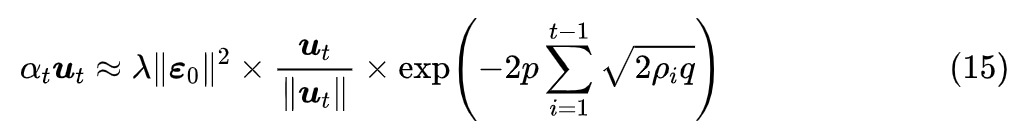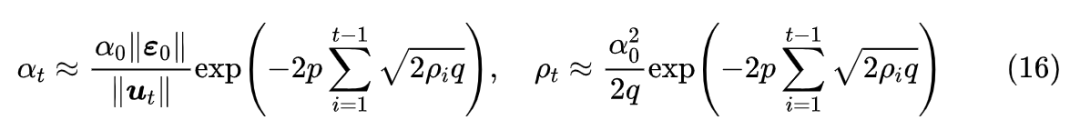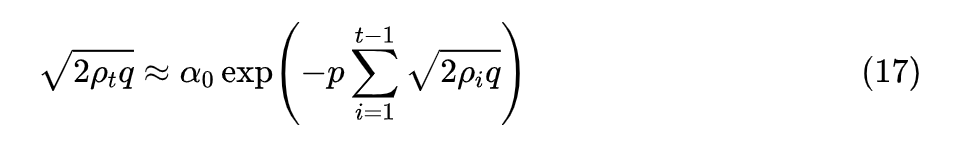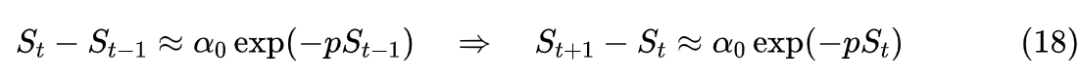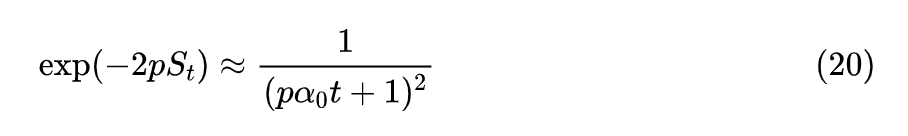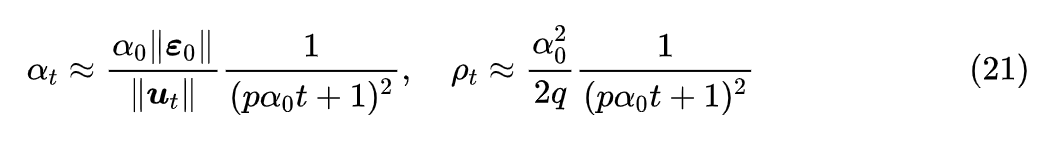©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传 AdamW 优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用 AdamW 或其变种 LAMB 倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择 AdamW 优化器,依然有很多问题还没有确定的答案,比如:
1. 学习率如何适应不同初始化和参数化?
2. 权重衰减率该怎么调?
3. 学习率应该用什么变化策略?
4. 能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于 Google 最近提出的 Amos 优化器的思路,给出一些参考结果。
Amos 优化器出自最近的论文《Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale》 [1] ,它对上述几个问题都推导了比较完整的推导,并通过实验证实了它的有效性。然而,原论文的推导实在是不好读,各种记号和估计都过于随意,给人很“凌乱”感觉。不过好在 Amos 的思想还不算复杂,我们可以借用一下。
在开始推导之前,我们不妨先回顾一下对于上述几个问题,现有的解决方案是怎样的。
首先,第一个问题,大家可能不大理解“初始化”和“参数化”分别是什么含义,其实这就是模型权重的两种设置方式,常见的就是一个
的矩阵,一般用“均值为 0、方差为1/n”的方式初始化,详细介绍可以参考笔者之前《从几何视角来理解模型参数的初始化策略》
[2]
、《浅谈Transformer的初始化、参数化与标准化》
[3]
。
从“方差为 1/n”我们就可以看到,不同参数有着不同的尺度(或者说数量级),如果我们用同一个学习率更新所有参数,那么就会导致每个参数的更新幅度不一样。这个问题笔者觉得比较优雅的解决方案就是 LAMB 优化器,它每次更新的模长直接取决于参数本身的模长,学习率只是用来描述相对更新量的大小。
至于权重衰减率问题,至少在预训练领域,笔者观察到的是都是沿用最早的选择 0.01,没有发现去调整该参数的工作。而对于学习率变化策略,大家都知道应该要将学习率慢慢降到零,但具体应该选用什么什么下降策略,暂时也没有太多的理论指导,多数结果也只是实验总结出来的。
最后,关于节省显存问题,比较经典的工作就是 AdaFactor 优化器,笔者之前在《AdaFactor优化器浅析(附开源实现)[4] 》也有过介绍。降低优化器显存占用的主要就两个思路,一是去掉动量,二是对二阶矩做低秩分解,Amos 本质上也是沿用了这两个思路。
本文主要关心开头的前三个问题,希望能够推导出一些“即插即用”的结果。首先,我们将优化器的更新规则简写成:
其实
分别代表
时刻的参数值,
代表
时刻的更新向量(依赖于任务和数据),而标量
(向量的每个元素都大于 0)代表
时刻的学习率。
自 AdamW 起,主流优化器都倾向于把权重衰减(Weight Decay)项从
中独立出来,即
其中
是权重衰减率。本文的主要任务,就是希望能解决
和
该怎么设置的问题。
我们知道,权重衰减也好,L2 正则也好,它本身是跟训练目标无关的,它只是一个辅助项,目的是提高模型的泛化能力。既然是辅助,那么一个基本的要求就是它不应该“喧宾夺主”,为此,我们不妨加入一个限制:
也就是说,在整个更新过程中,权重衰减带来的更新量始终要比目标相关的更新量高一阶,由于
基本上都是小于 1 的,所以更高阶意味着更小。
设优化的参数终点是
,我们记
,根据更新规则可以得到
很明显,
是当前结果与终点的距离,它自然是越小越好,因此我们自然也希望每一步的更新都能缩小这个距离,即
。
而我们看式 (4),
可正可负,如果它为负就有助于实现
,但是
必然是正的,它是不利于实现
,不过在引入权重衰减后,多出了一项
,如果这一项能抵消掉
的负面作用,那么权重衰减的引入就不仅能增强泛化能力,还有利于模型收敛了。
的可行性。所谓可行性,就是
能否大于 0,只有它大于 0,左右两端才有可能相等。利用
的定义我们得到
,于是
注意
是我们的目标,是一个固定的点,而
是当前时刻与目标的差异向量,两者一般来说没什么必然的相关性,于是我们可以近似认为它们是高维空间中两个随机向量。根据《n维空间下两个随机向量的夹角分布》[5] ,我们知道高维空间中两个随机向量几乎都是垂直的,于是
,
即
。当然,如果不放心,还可以引入一个参数
:
渐近估计
我们说了
代表的是任务相关的更新量,平均来说它必然是有利于任务的(否则原来的优化器就是有缺陷的了),所以平均来说应该有
。这里我们进一步假设,存在一个
,使得
,于是我们有
可以看出右端的指数必然是单调递减的,它是一个衰减函数。现在我们再看近似 (8) 它有两个参数
和
要调,但只有一个(近似)等式。为了使
和
能够同等程度地衰减,我们设
,于是解得
这就是本文推出的
的变化规律。当然,变化规律是有了,可是还有四个参数
要确定,其中
相对来说比较简单,直接设
问题也不大,但即便这样还有三个参数要确定。
尺度预判
根据定义,
,也就是初始化参数与目标参数的距离,可以理解为参数的变化尺度,它有几种不同的情况。
第一种,参数是矩阵乘法核,比如全连接层、卷积层的 kernel 矩阵,它们的初始化一般是“均值为 0、方差为
”(
取决于 shape)的随机初始化,这样如果
,那么我们就可以估算出
。
另外,这类参数有一个特点,就是在合理的初始化下,训练完成后参数的均值方差也不会有太大变化,至少量级是一致的,因此也可以认为
,而因为初始化是随机的,所以
,因此
第二种,参数是加性偏置项,比如全连接层、卷积层的 bias 向量,以及 Normalization 层的
向量,这些参数一般是“全零初始化”,所
以
,
如果我们根据经验预测训练好的模型偏置项都在
附近,那么也可以估计出
,Amos 原论文取了
。最后还有 Normalization 层的
向量,它一般是“全 1 初始化”,训练完成后也是在 1 附近,不妨假设误差为
,那么也可以估算出
。这里的 k 都是指向量维度。
可以看出,
的结果都有一个共性,那就是都可以写成
,其中
是我们对参数变化尺度的一个预判。乘性矩阵的
可以直接取初始化的标准差,加性偏置或者
向量可以直接简单地取
,或者有其他特殊参数的再做特殊处理。
其中
是一个单位向量,控制更新方向,
部分是一个衰减项,我们可以先不管它,所以更新量的模长由
控制。
回到文章开头的第一个问题“学习率如何适应不同初始化和参数化?”,很明显,直观想法应该就是变化尺度大的参数每一步的更新量应该更大,或者直接简单地正比于变化尺度,而变化尺度我们刚才估计了,可以用
来描述,所以我们认为应该有
,其中
是全局的初始学习率。反过来解得
,代入式 (13) 得到
其中
代表了每一步的相对更新幅度(全局学习率),这一步没啥推导空间了,一般取
左右就行,如果任务简单也可以取到
;
在上一节已经做了估计,大概是
,
代表参数尺度,不同参数不一样,我们正是通过它把参数尺度显式地分离了出来,从而达到了自适应参数尺度的效果(更新量正比
)。特别地,如果将上式的
换成
,那么就是 LAMB 优化器。
从这里也可以看出,如果
的初始化均值不是 0(像
向量),用
替代
是会有问题的,所以 LAMB 的做法是直接不对这些参数的更新量进行变换(即保留原来的更新规则)。
其实目前的结果已经适合编程实现了,只是参数 p 不好调罢了。为了进一步看出参数 p 是怎么影响衰减函数的,我们可以进一步求出
的解析近似!
在式 (16) 的
两边乘以
,然后两边开平方,得到
此时衰减函数就是
。为了求渐近近似,我们用导数代替差分(参考《差分方程的摄动法》[6] ),得到
这就是衰减函数的显式解,表明超参数应该按照步数的平方反比衰减,具体代入式 (16) 后得到
这个显式解不但能让编程实现更方便,还使得 p 的含义更为清晰。比如我们希望学习率在 T 步后就降低为原来的一半,那么就有
,从中解得
至于 T 应该是多少,这依赖于任务难度和数据量,也没有太大推导空间了。
文章小结
本文借鉴了 Amos 优化器的思路,推导了一些关于学习率和权重衰减率的结果 (21),这些结果可以即插即用地应用到现有优化器中,能一定程度上简化调参难度。
[1] https://arxiv.org/abs/2210.11693
[2] https://kexue.fm/archives/7180
[3] https://kexue.fm/archives/8620
[4] https://kexue.fm/archives/7180
[5] https://kexue.fm/archives/7076
[6] https://kexue.fm/archives/3889
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」