实践教程|YOLOP ONNXRuntime C++工程化记录

极市导读
本篇简单记录了作者对YOLOP进行C++工程化的过程,附有相关代码以及链接。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
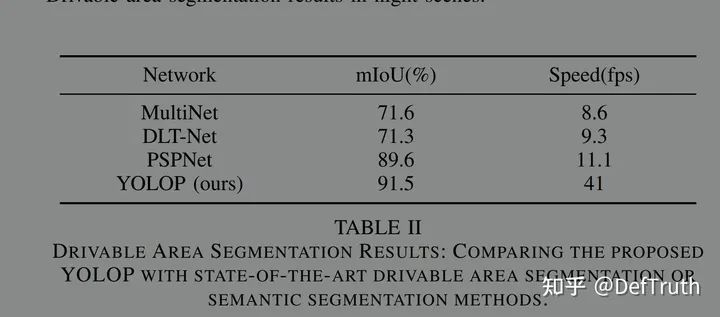
华中科大在最近开源了全景感知模型YOLOP,在YOLOv4的基础上做了改进,与YOLOv4相同的是都采用了CSP、SPP等模块,不同的是,YOLOP在Detect检测头之外增加了可驾驶区域分割和航道分割两个分支。很简洁的模型结构,获得了不错的效果。
官方开源的代码在:
https://github.com/hustvl/YOLOPgithub.com/hustvl/YOLOP
在我fork(https://github.com/DefTruth/YOLOP)的分支,可以找到包含转换后的onnx文件和转换代码。
本篇文章不再介绍具体的模型结构,而是简单记录下,我对YOLOP进行C++工程化的过程。先附上完整的C++工程代码。
https://github.com/DefTruth/lite.ai.toolkit/blob/main/ort/cv/yolop.cppgithub.com/DefTruth/lite.ai.toolkit/blob/main/lite/ort/cv/yolop.cpp
转换成ONNX的过程
为了成功兼容onnx,首先需要对common中的Focus和Detect进行修改。为了不和原来的common.py搞混,把修改后的文件命名为common2.py(https://github.com/DefTruth/YOLOP/blob/main/lib/models/common2.py)。需要修改的主要包括DepthSeperabelConv2d、Focus和Detect。
-
修改DepthSeperabelConv2d
由于在原来的代码中找不到BN_MOMENTUM变量,直接使用会出错,issues#19(https://github.com/hustvl/YOLOP/issues/19),所以我去掉了这个变量。修改后为:
class DepthSeperabelConv2d(nn.Module):
"""
DepthSeperable Convolution 2d with residual connection
"""
def __init__(self, inplanes, planes, kernel_size=3, stride=1, downsample=None, act=True):
super(DepthSeperabelConv2d, self).__init__()
self.depthwise = nn.Sequential(
nn.Conv2d(inplanes, inplanes, kernel_size, stride=stride, groups=inplanes, padding=kernel_size // 2,
bias=False),
nn.BatchNorm2d(inplanes)
)
# self.depthwise = nn.Conv2d(inplanes, inplanes, kernel_size,
# stride=stride, groups=inplanes, padding=1, bias=False)
# self.pointwise = nn.Conv2d(inplanes, planes, 1, bias=False)
self.pointwise = nn.Sequential(
nn.Conv2d(inplanes, planes, 1, bias=False),
nn.BatchNorm2d(planes)
)
self.downsample = downsample
self.stride = stride
try:
self.act = nn.Hardswish() if act else nn.Identity()
except:
self.act = nn.Identity()
def forward(self, x):
# residual = x
out = self.depthwise(x)
out = self.act(out)
out = self.pointwise(out)
if self.downsample is not None:
residual = self.downsample(x)
out = self.act(out)
return out
-
修改Detect
原来的直接内存操作,会导致转换后的模型推理异常。可以推理,但是结果是错的。参考我在yolov5的工程化记录ort_yolov5.zh.md以及tiny_yolov4的工程化记录ort_tiny_yolov4.zh.md。我对Detect模块进行了修改,使其兼容onnx。
ort_yolov5.zh.md:https://github.com/DefTruth/lite.ai.toolkit/blob/main/docs/ort/ort_yolov5.zh.md
ort_tiny_yolov4.zh.md:https://github.com/DefTruth/lite.ai.toolkit/blob/main/docs/ort/ort_tiny_yolov4.zh.md
修改后的Detect模块如下:
class Detect(nn.Module):
stride = None # strides computed during build
def __init__(self, nc=13, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers 3
self.na = len(anchors[0]) // 2 # number of anchors 3
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2) # (nl=3,na=3,2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl=3,1,na=3,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = True # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv (bs,na*no,ny,nx)
bs, _, ny, nx = x[i].shape
# x(bs,255,20,20) to x(bs,3,20,20,nc+5) (bs,na,ny,nx,no=nc+5=4+1+nc)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
# if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
# self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid() # (bs,na,ny,nx,no=nc+5=4+1+nc)
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy (bs,na,ny,nx,2)
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh (bs,na,ny,nx,2)
y = torch.cat((xy, wh, y[..., 4:]), -1) # (bs,na,ny,nx,2+2+1+nc=xy+wh+conf+cls_prob)
z.append(y.view(bs, -1, self.no)) # y (bs,na*ny*nx,no=2+2+1+nc=xy+wh+conf+cls_prob)
return x if self.training else (torch.cat(z, 1), x)
# torch.cat(z, 1) (bs,na*ny*nx*nl,no=2+2+1+nc=xy+wh+conf+cls_prob)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
-
修改Focus
在YOLOP工程化中,我并没有修改Focus模块,因为我在使用了高版本的pytorch(1.8.0)和onnx(1.8.0)后,转换出来的onnx模型文件没有问题,可以正常推理。
然后是,修改MCnet,让模型输出想要的3个结果张量。
-
export_onnx.py
import torch
import torch.nn as nn
from lib.models.common2 import Conv, SPP, Bottleneck, BottleneckCSP, Focus, Concat, Detect, SharpenConv
from torch.nn import Upsample
from lib.utils import check_anchor_order
from lib.utils import initialize_weights
import argparse
import onnx
import onnxruntime as ort
import onnxsim
import math
import cv2
# The lane line and the driving area segment branches without share information with each other and without link
YOLOP = [
[24, 33, 42], # Det_out_idx, Da_Segout_idx, LL_Segout_idx
[-1, Focus, [3, 32, 3]], # 0
[-1, Conv, [32, 64, 3, 2]], # 1
[-1, BottleneckCSP, [64, 64, 1]], # 2
[-1, Conv, [64, 128, 3, 2]], # 3
[-1, BottleneckCSP, [128, 128, 3]], # 4
[-1, Conv, [128, 256, 3, 2]], # 5
[-1, BottleneckCSP, [256, 256, 3]], # 6
[-1, Conv, [256, 512, 3, 2]], # 7
[-1, SPP, [512, 512, [5, 9, 13]]], # 8 SPP
[-1, BottleneckCSP, [512, 512, 1, False]], # 9
[-1, Conv, [512, 256, 1, 1]], # 10
[-1, Upsample, [None, 2, 'nearest']], # 11
[[-1, 6], Concat, [1]], # 12
[-1, BottleneckCSP, [512, 256, 1, False]], # 13
[-1, Conv, [256, 128, 1, 1]], # 14
[-1, Upsample, [None, 2, 'nearest']], # 15
[[-1, 4], Concat, [1]], # 16 #Encoder
[-1, BottleneckCSP, [256, 128, 1, False]], # 17
[-1, Conv, [128, 128, 3, 2]], # 18
[[-1, 14], Concat, [1]], # 19
[-1, BottleneckCSP, [256, 256, 1, False]], # 20
[-1, Conv, [256, 256, 3, 2]], # 21
[[-1, 10], Concat, [1]], # 22
[-1, BottleneckCSP, [512, 512, 1, False]], # 23
[[17, 20, 23], Detect,
[1, [[3, 9, 5, 11, 4, 20], [7, 18, 6, 39, 12, 31], [19, 50, 38, 81, 68, 157]], [128, 256, 512]]],
# Detection head 24: from_(features from specific layers), block, nc(num_classes) anchors ch(channels)
[16, Conv, [256, 128, 3, 1]], # 25
[-1, Upsample, [None, 2, 'nearest']], # 26
[-1, BottleneckCSP, [128, 64, 1, False]], # 27
[-1, Conv, [64, 32, 3, 1]], # 28
[-1, Upsample, [None, 2, 'nearest']], # 29
[-1, Conv, [32, 16, 3, 1]], # 30
[-1, BottleneckCSP, [16, 8, 1, False]], # 31
[-1, Upsample, [None, 2, 'nearest']], # 32
[-1, Conv, [8, 2, 3, 1]], # 33 Driving area segmentation head
[16, Conv, [256, 128, 3, 1]], # 34
[-1, Upsample, [None, 2, 'nearest']], # 35
[-1, BottleneckCSP, [128, 64, 1, False]], # 36
[-1, Conv, [64, 32, 3, 1]], # 37
[-1, Upsample, [None, 2, 'nearest']], # 38
[-1, Conv, [32, 16, 3, 1]], # 39
[-1, BottleneckCSP, [16, 8, 1, False]], # 40
[-1, Upsample, [None, 2, 'nearest']], # 41
[-1, Conv, [8, 2, 3, 1]] # 42 Lane line segmentation head
]
class MCnet(nn.Module):
def __init__(self, block_cfg):
super(MCnet, self).__init__()
layers, save = [], []
self.nc = 1 # traffic or not
self.detector_index = -1
self.det_out_idx = block_cfg[0][0]
self.seg_out_idx = block_cfg[0][1:]
self.num_anchors = 3
self.num_outchannel = 5 + self.nc # dx,dy,dw,dh,obj_conf+cls_conf
# Build model
for i, (from_, block, args) in enumerate(block_cfg[1:]):
block = eval(block) if isinstance(block, str) else block # eval strings
if block is Detect:
self.detector_index = i
block_ = block(*args)
block_.index, block_.from_ = i, from_
layers.append(block_)
save.extend(x % i for x in ([from_] if isinstance(from_, int) else from_) if x != -1) # append to savelist
assert self.detector_index == block_cfg[0][0]
self.model, self.save = nn.Sequential(*layers), sorted(save)
self.names = [str(i) for i in range(self.nc)]
# set stride、anchor for detector
Detector = self.model[self.detector_index] # detector
if isinstance(Detector, Detect):
s = 128 # 2x min stride
# for x in self.forward(torch.zeros(1, 3, s, s)):
# print (x.shape)
with torch.no_grad():
model_out = self.forward(torch.zeros(1, 3, s, s))
detects, _, _ = model_out
Detector.stride = torch.tensor([s / x.shape[-2] for x in detects]) # forward
# print("stride"+str(Detector.stride ))
Detector.anchors /= Detector.stride.view(-1, 1, 1) # Set the anchors for the corresponding scale
check_anchor_order(Detector)
self.stride = Detector.stride
# self._initialize_biases()
initialize_weights(self)
def forward(self, x):
cache = []
out = []
det_out = None
for i, block in enumerate(self.model):
if block.from_ != -1:
x = cache[block.from_] if isinstance(block.from_, int) \
else [x if j == -1 else cache[j] for j in
block.from_] # calculate concat detect
x = block(x)
if i in self.seg_out_idx: # save driving area segment result
# m = nn.Sigmoid()
# out.append(m(x))
out.append(torch.sigmoid(x))
if i == self.detector_index:
# det_out = x
if self.training:
det_out = x
else:
det_out = x[0] # (torch.cat(z, 1), input_feat) if test
cache.append(x if block.index in self.save else None)
return det_out, out[0], out[1] # det, da, ll
# (1,na*ny*nx*nl,no=2+2+1+nc=xy+wh+obj_conf+cls_prob), (1,2,h,w) (1,2,h,w)
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
# m = self.model[-1] # Detect() module
m = self.model[self.detector_index] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--height', type=int, default=640) # height
parser.add_argument('--width', type=int, default=640) # width
args = parser.parse_args()
do_simplify = True
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = MCnet(YOLOP)
checkpoint = torch.load('./weights/End-to-end.pth', map_location=device)
model.load_state_dict(checkpoint['state_dict'])
model.eval()
height = args.height
width = args.width
print("Load ./weights/End-to-end.pth done!")
onnx_path = f'./weights/yolop-{height}-{width}.onnx'
inputs = torch.randn(1, 3, height, width)
print(f"Converting to {onnx_path}")
torch.onnx.export(model, inputs, onnx_path,
verbose=False, opset_version=12, input_names=['images'],
output_names=['det_out', 'drive_area_seg', 'lane_line_seg'])
print('convert', onnx_path, 'to onnx finish!!!')
# Checks
model_onnx = onnx.load(onnx_path) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
print(onnx.helper.printable_graph(model_onnx.graph)) # print
if do_simplify:
print(f'simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx, check_n=3)
assert check, 'assert check failed'
onnx.save(model_onnx, onnx_path)
x = inputs.cpu().numpy()
try:
sess = ort.InferenceSession(onnx_path)
for ii in sess.get_inputs():
print("Input: ", ii)
for oo in sess.get_outputs():
print("Output: ", oo)
print('read onnx using onnxruntime sucess')
except Exception as e:
print('read failed')
raise e
"""
PYTHONPATH=. python3 ./export_onnx.py --height 640 --width 640
PYTHONPATH=. python3 ./export_onnx.py --height 1280 --width 1280
PYTHONPATH=. python3 ./export_onnx.py --height 320 --width 320
"""
Python版本onnxruntime测试
-
test_onnx.py
这里我重新现实现了一套推理的逻辑,和原来的demo.py结果保持一致,但只使用了numpy和opencv做数据前后处理,没有用torchvision的transform模块,便于c++复现python逻辑。同时,为了保持逻辑的简单,我实现了等价的resize_unscale函数,替代了原来的letterbox_for_img,这个函数有些工程不友好,而且个人一直都认为copyMakeBorder操作有些鸡肋。resize_unscale进行resize时保持原图的宽高尺度的比例不变,如果是采用普通的resize,推理效果会变差。
import os
import cv2
import torch
import argparse
import onnxruntime as ort
import numpy as np
from lib.core.general import non_max_suppression
def resize_unscale(img, new_shape=(640, 640), color=114):
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
canvas = np.zeros((new_shape[0], new_shape[1], 3))
canvas.fill(color)
# Scale ratio (new / old) new_shape(h,w)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # w,h
new_unpad_w = new_unpad[0]
new_unpad_h = new_unpad[1]
pad_w, pad_h = new_shape[1] - new_unpad_w, new_shape[0] - new_unpad_h # wh padding
dw = pad_w // 2 # divide padding into 2 sides
dh = pad_h // 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_AREA)
canvas[dh:dh + new_unpad_h, dw:dw + new_unpad_w, :] = img
return canvas, r, dw, dh, new_unpad_w, new_unpad_h # (dw,dh)
def infer_yolop(weight="yolop-640-640.onnx",
img_path="./inference/images/7dd9ef45-f197db95.jpg"):
ort.set_default_logger_severity(4)
onnx_path = f"./weights/{weight}"
ort_session = ort.InferenceSession(onnx_path)
print(f"Load {onnx_path} done!")
outputs_info = ort_session.get_outputs()
inputs_info = ort_session.get_inputs()
for ii in inputs_info:
print("Input: ", ii)
for oo in outputs_info:
print("Output: ", oo)
print("num outputs: ", len(outputs_info))
save_det_path = f"./pictures/detect_onnx.jpg"
save_da_path = f"./pictures/da_onnx.jpg"
save_ll_path = f"./pictures/ll_onnx.jpg"
save_merge_path = f"./pictures/output_onnx.jpg"
img_bgr = cv2.imread(img_path)
height, width, _ = img_bgr.shape
# convert to RGB
img_rgb = img_bgr[:, :, ::-1].copy()
# resize & normalize
canvas, r, dw, dh, new_unpad_w, new_unpad_h = resize_unscale(img_rgb, (640, 640))
img = canvas.copy().transpose(2, 0, 1).astype(np.float32) # (3,640,640) RGB
img /= 255.0
img[:, :, 0] -= 0.485
img[:, :, 1] -= 0.456
img[:, :, 2] -= 0.406
img[:, :, 0] /= 0.229
img[:, :, 1] /= 0.224
img[:, :, 2] /= 0.225
img = np.expand_dims(img, 0) # (1, 3,640,640)
# inference: (1,n,6) (1,2,640,640) (1,2,640,640)
det_out, da_seg_out, ll_seg_out = ort_session.run(
['det_out', 'drive_area_seg', 'lane_line_seg'],
input_feed={"images": img}
)
det_out = torch.from_numpy(det_out).float()
boxes = non_max_suppression(det_out)[0] # [n,6] [x1,y1,x2,y2,conf,cls]
boxes = boxes.cpu().numpy().astype(np.float32)
if boxes.shape[0] == 0:
print("no bounding boxes detected.")
return
# scale coords to original size.
boxes[:, 0] -= dw
boxes[:, 1] -= dh
boxes[:, 2] -= dw
boxes[:, 3] -= dh
boxes[:, :4] /= r
print(f"detect {boxes.shape[0]} bounding boxes.")
img_det = img_rgb[:, :, ::-1].copy()
for i in range(boxes.shape[0]):
x1, y1, x2, y2, conf, label = boxes[i]
x1, y1, x2, y2, label = int(x1), int(y1), int(x2), int(y2), int(label)
img_det = cv2.rectangle(img_det, (x1, y1), (x2, y2), (0, 255, 0), 2, 2)
cv2.imwrite(save_det_path, img_det)
# select da & ll segment area.
da_seg_out = da_seg_out[:, :, dh:dh + new_unpad_h, dw:dw + new_unpad_w]
ll_seg_out = ll_seg_out[:, :, dh:dh + new_unpad_h, dw:dw + new_unpad_w]
da_seg_mask = np.argmax(da_seg_out, axis=1)[0] # (?,?) (0|1)
ll_seg_mask = np.argmax(ll_seg_out, axis=1)[0] # (?,?) (0|1)
print(da_seg_mask.shape)
print(ll_seg_mask.shape)
color_area = np.zeros((new_unpad_h, new_unpad_w, 3), dtype=np.uint8)
color_area[da_seg_mask == 1] = [0, 255, 0]
color_area[ll_seg_mask == 1] = [255, 0, 0]
color_seg = color_area
# convert to BGR
color_seg = color_seg[..., ::-1]
color_mask = np.mean(color_seg, 2)
img_merge = canvas[dh:dh + new_unpad_h, dw:dw + new_unpad_w, :]
img_merge = img_merge[:, :, ::-1]
# merge: resize to original size
img_merge[color_mask != 0] = \
img_merge[color_mask != 0] * 0.5 + color_seg[color_mask != 0] * 0.5
img_merge = img_merge.astype(np.uint8)
img_merge = cv2.resize(img_merge, (width, height),
interpolation=cv2.INTER_LINEAR)
for i in range(boxes.shape[0]):
x1, y1, x2, y2, conf, label = boxes[i]
x1, y1, x2, y2, label = int(x1), int(y1), int(x2), int(y2), int(label)
img_merge = cv2.rectangle(img_merge, (x1, y1), (x2, y2), (0, 255, 0), 2, 2)
# da: resize to original size
da_seg_mask = da_seg_mask * 255
da_seg_mask = da_seg_mask.astype(np.uint8)
da_seg_mask = cv2.resize(da_seg_mask, (width, height),
interpolation=cv2.INTER_LINEAR)
# ll: resize to original size
ll_seg_mask = ll_seg_mask * 255
ll_seg_mask = ll_seg_mask.astype(np.uint8)
ll_seg_mask = cv2.resize(ll_seg_mask, (width, height),
interpolation=cv2.INTER_LINEAR)
cv2.imwrite(save_merge_path, img_merge)
cv2.imwrite(save_da_path, da_seg_mask)
cv2.imwrite(save_ll_path, ll_seg_mask)
print("detect done.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--weight', type=str, default="yolop-640-640.onnx")
parser.add_argument('--img', type=str, default="./inference/images/9aa94005-ff1d4c9a.jpg")
args = parser.parse_args()
infer_yolop(weight=args.weight, img_path=args.img)
"""
PYTHONPATH=. python3 ./test_onnx.py --weight yolop-640-640.onnx --img ./inference/images/9aa94005-ff1d4c9a.jpg
"""
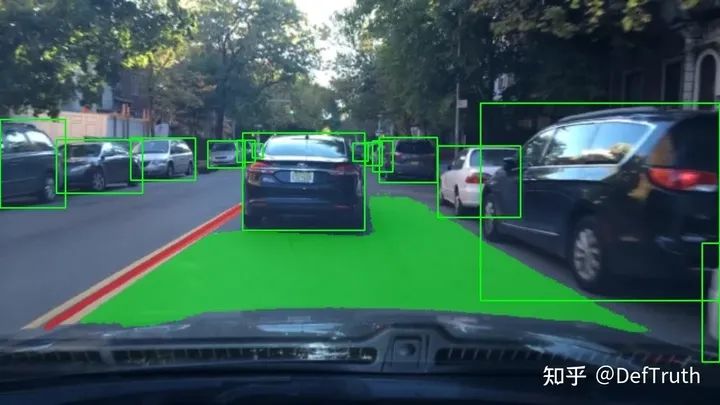
测试结果如下:
C++版本的ONNXRuntime推理实现
-
yolop.cpp: https://github.com/DefTruth/lite.ai.toolkit/blob/main/lite/ort/cv/yolop.cpp
//
// Created by DefTruth on 2021/9/14.
//
#include "yolop.h"
#include "ort/core/ort_utils.h"
using ortcv::YOLOP;
void YOLOP::resize_unscale(const cv::Mat &mat, cv::Mat &mat_rs,
int target_height, int target_width,
YOLOPScaleParams &scale_params)
{
if (mat.empty()) return;
int img_height = static_cast<int>(mat.rows);
int img_width = static_cast<int>(mat.cols);
mat_rs = cv::Mat(target_height, target_width, CV_8UC3,
cv::Scalar(114, 114, 114));
// scale ratio (new / old) new_shape(h,w)
float w_r = (float) target_width / (float) img_width;
float h_r = (float) target_height / (float) img_height;
float r = std::fmin(w_r, h_r);
// compute padding
int new_unpad_w = static_cast<int>((float) img_width * r); // floor
int new_unpad_h = static_cast<int>((float) img_height * r); // floor
int pad_w = target_width - new_unpad_w; // >=0
int pad_h = target_height - new_unpad_h; // >=0
int dw = pad_w / 2;
int dh = pad_h / 2;
// resize with unscaling
cv::Mat new_unpad_mat = mat.clone();
cv::resize(new_unpad_mat, new_unpad_mat, cv::Size(new_unpad_w, new_unpad_h));
new_unpad_mat.copyTo(mat_rs(cv::Rect(dw, dh, new_unpad_w, new_unpad_h)));
// record scale params.
scale_params.r = r;
scale_params.dw = dw;
scale_params.dh = dh;
scale_params.new_unpad_w = new_unpad_w;
scale_params.new_unpad_h = new_unpad_h;
scale_params.flag = true;
}
Ort::Value YOLOP::transform(const cv::Mat &mat_rs)
{
cv::Mat canva = mat_rs.clone();
cv::cvtColor(canva, canva, cv::COLOR_BGR2RGB);
// (1,3,640,640) 1xCXHXW
ortcv::utils::transform::normalize_inplace(canva, mean_vals, scale_vals); // float32
return ortcv::utils::transform::create_tensor(
canva, input_node_dims, memory_info_handler,
input_values_handler, ortcv::utils::transform::CHW);
}
void YOLOP::detect(const cv::Mat &mat,
std::vector<types::Boxf> &detected_boxes,
types::SegmentContent &da_seg_content,
types::SegmentContent &ll_seg_content,
float score_threshold, float iou_threshold,
unsigned int topk, unsigned int nms_type)
{
if (mat.empty()) return;
float img_height = static_cast<float>(mat.rows);
float img_width = static_cast<float>(mat.cols);
const int target_height = input_node_dims.at(2);
const int target_width = input_node_dims.at(3);
// resize & unscale
cv::Mat mat_rs;
YOLOPScaleParams scale_params;
this->resize_unscale(mat, mat_rs, target_height, target_width, scale_params);
if ((!scale_params.flag) || mat_rs.empty()) return;
// 1. make input tensor
Ort::Value input_tensor = this->transform(mat_rs);
// 2. inference scores & boxes.
auto output_tensors = ort_session->Run(
Ort::RunOptions{nullptr}, input_node_names.data(),
&input_tensor, 1, output_node_names.data(), num_outputs
); // det_out, drive_area_seg, lane_line_seg
// 3. rescale & fetch da|ll seg.
std::vector<types::Boxf> bbox_collection;
this->generate_bboxes_da_ll(scale_params, output_tensors, bbox_collection,
da_seg_content, ll_seg_content, score_threshold,
img_height, img_width);
// 4. hard|blend nms with topk.
this->nms(bbox_collection, detected_boxes, iou_threshold, topk, nms_type);
}
void YOLOP::generate_bboxes_da_ll(const YOLOPScaleParams &scale_params,
std::vector<Ort::Value> &output_tensors,
std::vector<types::Boxf> &bbox_collection,
types::SegmentContent &da_seg_content,
types::SegmentContent &ll_seg_content,
float score_threshold, float img_height,
float img_width)
{
Ort::Value &det_out = output_tensors.at(0); // (1,n,6=5+1=cxcy+cwch+obj_conf+cls_conf)
Ort::Value &da_seg_out = output_tensors.at(1); // (1,2,640,640)
Ort::Value &ll_seg_out = output_tensors.at(2); // (1,2,640,640)
auto det_dims = output_node_dims.at(0); // (1,n,6)
const unsigned int num_anchors = det_dims.at(1); // n = ?
float r = scale_params.r;
int dw = scale_params.dw;
int dh = scale_params.dh;
int new_unpad_w = scale_params.new_unpad_w;
int new_unpad_h = scale_params.new_unpad_h;
// generate bounding boxes.
bbox_collection.clear();
unsigned int count = 0;
for (unsigned int i = 0; i < num_anchors; ++i)
{
float obj_conf = det_out.At<float>({0, i, 4});
if (obj_conf < score_threshold) continue; // filter first.
unsigned int label = 1; // 1 class only
float cls_conf = det_out.At<float>({0, i, 5});
float conf = obj_conf * cls_conf; // cls_conf (0.,1.)
if (conf < score_threshold) continue; // filter
float cx = det_out.At<float>({0, i, 0});
float cy = det_out.At<float>({0, i, 1});
float w = det_out.At<float>({0, i, 2});
float h = det_out.At<float>({0, i, 3});
types::Boxf box;
// de-padding & rescaling
box.x1 = ((cx - w / 2.f) - (float) dw) / r;
box.y1 = ((cy - h / 2.f) - (float) dh) / r;
box.x2 = ((cx + w / 2.f) - (float) dw) / r;
box.y2 = ((cy + h / 2.f) - (float) dh) / r;
box.score = conf;
box.label = label;
box.label_text = "traffic car";
box.flag = true;
bbox_collection.push_back(box);
count += 1; // limit boxes for nms.
if (count > max_nms)
break;
}
#if LITEORT_DEBUG
std::cout << "detected num_anchors: " << num_anchors << "\n";
std::cout << "generate_bboxes num: " << bbox_collection.size() << "\n";
#endif
// generate da && ll seg.
da_seg_content.names_map.clear();
da_seg_content.class_mat = cv::Mat(new_unpad_h, new_unpad_w, CV_8UC1, cv::Scalar(0));
da_seg_content.color_mat = cv::Mat(new_unpad_h, new_unpad_w, CV_8UC3, cv::Scalar(0, 0, 0));
ll_seg_content.names_map.clear();
ll_seg_content.class_mat = cv::Mat(new_unpad_h, new_unpad_w, CV_8UC1, cv::Scalar(0));
ll_seg_content.color_mat = cv::Mat(new_unpad_h, new_unpad_w, CV_8UC3, cv::Scalar(0, 0, 0));
for (int i = dh; i < dh + new_unpad_h; ++i)
{
// row ptr.
uchar *da_p_class = da_seg_content.class_mat.ptr<uchar>(i - dh);
uchar *ll_p_class = ll_seg_content.class_mat.ptr<uchar>(i - dh);
cv::Vec3b *da_p_color = da_seg_content.color_mat.ptr<cv::Vec3b>(i - dh);
cv::Vec3b *ll_p_color = ll_seg_content.color_mat.ptr<cv::Vec3b>(i - dh);
for (int j = dw; j < dw + new_unpad_w; ++j)
{
// argmax
float da_bg_prob = da_seg_out.At<float>({0, 0, i, j});
float da_fg_prob = da_seg_out.At<float>({0, 1, i, j});
float ll_bg_prob = ll_seg_out.At<float>({0, 0, i, j});
float ll_fg_prob = ll_seg_out.At<float>({0, 1, i, j});
unsigned int da_label = da_bg_prob < da_fg_prob ? 1 : 0;
unsigned int ll_label = ll_bg_prob < ll_fg_prob ? 1 : 0;
if (da_label == 1)
{
// assign label for pixel(i,j)
da_p_class[j - dw] = 1 * 255; // 255 indicate drivable area, for post resize
// assign color for detected class at pixel(i,j).
da_p_color[j - dw][0] = 0;
da_p_color[j - dw][1] = 255; // green
da_p_color[j - dw][2] = 0;
// assign names map
da_seg_content.names_map[255] = "drivable area";
}
if (ll_label == 1)
{
// assign label for pixel(i,j)
ll_p_class[j - dw] = 1 * 255; // 255 indicate lane line, for post resize
// assign color for detected class at pixel(i,j).
ll_p_color[j - dw][0] = 0;
ll_p_color[j - dw][1] = 0;
ll_p_color[j - dw][2] = 255; // red
// assign names map
ll_seg_content.names_map[255] = "lane line";
}
}
}
// resize to original size.
const unsigned int h = static_cast<unsigned int>(img_height);
const unsigned int w = static_cast<unsigned int>(img_width);
// da_seg_mask 255 or 0
cv::resize(da_seg_content.class_mat, da_seg_content.class_mat,
cv::Size(w, h), cv::INTER_LINEAR);
cv::resize(da_seg_content.color_mat, da_seg_content.color_mat,
cv::Size(w, h), cv::INTER_LINEAR);
// ll_seg_mask 255 or 0
cv::resize(ll_seg_content.class_mat, ll_seg_content.class_mat,
cv::Size(w, h), cv::INTER_LINEAR);
cv::resize(ll_seg_content.color_mat, ll_seg_content.color_mat,
cv::Size(w, h), cv::INTER_LINEAR);
da_seg_content.flag = true;
ll_seg_content.flag = true;
}
void YOLOP::nms(std::vector<types::Boxf> &input, std::vector<types::Boxf> &output,
float iou_threshold, unsigned int topk, unsigned int nms_type)
{
if (nms_type == NMS::BLEND) ortcv::utils::blending_nms(input, output, iou_threshold, topk);
else if (nms_type == NMS::OFFSET) ortcv::utils::offset_nms(input, output, iou_threshold, topk);
else ortcv::utils::hard_nms(input, output, iou_threshold, topk);
}
测试用例见:
yolop-cpp-demogithub.com/DefTruth/lite.ai/blob/main/examples/lite/cv/test_lite_yolop.cpp
所有的C++代码放在了我写的工具箱中
Lite.AI.ToolKit : 一个开箱即用的C++ AI模型工具箱
https://github.com/DefTruth/lite.ai.toolkit/blob/main/README.zh.md
最新进展,PR已经被merged进YOLOP的官方仓库了,现在可以直接在YOLOP 下载转换后的onnx文件啦~
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~