正则化技巧:标签平滑以及在 PyTorch 中的实现

极市导读
在本文描述并展示4种不同的Pytorch训练技巧的代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
混合精度
在一个常规的训练循环中,PyTorch以32位精度存储所有浮点数变量。对于那些在严格的约束下训练模型的人来说,这有时会导致他们的模型占用过多的内存,迫使他们使用更小的模型和更小的批处理大小进行更慢的训练过程。所以在模型中以16位精度存储所有变量/数字可以改善并修复大部分这些问题,比如显著减少模型的内存消耗,加速训练循环,同时仍然保持模型的性能/精度。
在Pytorch中将所有计算转换为16位精度非常简单,只需要几行代码。这里是:
scaler = torch.cuda.amp.GradScaler()
上面的方法创建一个梯度缩放标量,以最大程度避免使用fp16进行运算时的梯度下溢。
optimizer.zero_grad()
with torch.cuda.amp.autocast():
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
当使用loss和优化器进行反向传播时,您需要使用scale .scale(loss),而不是使用loss.backward()和optimizer.step()。使用scaler.step(optimizer)来更新优化器。这允许你的标量转换所有的梯度,并在16位精度做所有的计算,最后用scaler.update()来更新缩放标量以使其适应训练的梯度。
当以16位精度做所有事情时,可能会有一些数值不稳定,导致您可能使用的一些函数不能正常工作。只有某些操作在16位精度下才能正常工作。具体可参考官方的文档。
进度条
有一个进度条来表示每个阶段的训练完成的百分比是非常有用的。为了获得进度条,我们将使用tqdm库。以下是如何下载并导入它:
pip install tqdm
from tqdm import tqdm
在你的训练和验证循环中,你必须这样做:
for index, batch in tqdm(enumerate(loader), total = len(loader), position = 0, leave = True):
训练和验证循环添加tqdm代码后将得到一个进度条,它表示您的模型完成的训练的百分比。它应该是这样的:
在图中,691代表我的模型需要完成多少批,7:28代表我的模型在691批上的总时间,1.54 it/s代表我的模型在每批上花费的平均时间。
梯度积累
如果您遇到CUDA内存不足的错误,这意味着您已经超出了您的计算资源。为了解决这个问题,你可以做几件事,包括把所有东西都转换成16位精度,减少模型的批处理大小,更换更小的模型等等。
但是有时切换到16位精度并不能完全解决问题。解决这个问题最直接的方法是减少批处理大小,但是假设您不想减少批处理大小可以使用梯度累积来模拟所需的批大小。请注意,CUDA内存不足问题的另一个解决方案是简单地使用多个GPU,但这是一个很多人无法使用的选项。
假设你的机器/模型只能支持16的批处理大小,增加它会导致CUDA内存不足错误,并且您希望批处理大小为32。梯度累加的工作原理是:以16个批的规模运行模型两次,将计算出的每个批的梯度累加起来,最后在这两次前向传播和梯度累加之后执行一个优化步骤。
要理解梯度积累,重要的是要理解在训练神经网络时所做的具体功能。假设你有以下训练循环:
model = model.train()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
optimizer.zero_grad()
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
loss.backward()
optimizer.step()
看看上面的代码,需要记住的关键是loss.backward()为模型创建并存储梯度,而optimizer.step()实际上更新权重。在如果在调用优化器之前两次调用loss.backward()就会对梯度进行累加。下面是如何在PyTorch中实现梯度累加:
model = model.train()
optimizer.zero_grad()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
loss.backward()
if (index+1) % 2 == 0:
optimizer.step()
optimizer.zero_grad()
在上面的例子中,我们的机器只能支持16批大小的批量,我们想要32批大小的批量,我们本质上计算2批的梯度,然后更新实际权重。这导致有效批大小为32。
译者注:梯度累加只是一个折中方案,经过我们的测试,如果对梯度进行累加,那么最后一次loss.backward()的梯度会比前几次反向传播的权重高,具体为什么我们也不清楚,哈。虽然有这样的问题,但是使用这种方式进行训练还是有效果的。
16位精度的梯度累加非常类似。
model = model.train()
optimizer.zero_grad()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
with torch.cuda.amp.autocast():
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
scaler.scale(loss).backward()
if (index+1) % 2 == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
结果评估
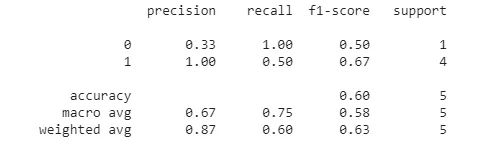
在大多数机器学习项目中,人们倾向于手动计算用于评估的指标。尽管计算准确率、精度、召回率和F1等指标并不困难,但在某些情况下,您可能希望拥有这些指标的某些变体,如加权精度、召回率和F1。计算这些可能需要更多的工作,如果你的实现可能不正确、高效、快速且无错误地计算所有这些指标,可以使用sklearns classification_report库。这是一个专门为计算这些指标而设计的库。
from sklearn.metrics import classification_report
y_pred = [0, 1, 0, 0, 1]
y_correct = [1, 1, 0, 1, 1]print(classification_report(y_correct, y_pred))
上面的代码用于二进制分类。你可以为更多的目的配置这个函数。第一个列表表示模型的预测,第二个列表表示正确数值。上面的代码将输出:
结论
在这篇文章中,我讨论了4种pytorch中优化深度神经网络训练的方法。16位精度减少内存消耗,梯度积累可以通过模拟使用更大的批大小,tqdm进度条和sklearns的classification_report两个方便的库,可以轻松地跟踪模型的训练和评估模型的性能。就我个人而言,我总是用上面所有的训练技巧来训练我的神经网络,并且在必要的时候我使用梯度积累。
最后,如果你使用的是pytorch或者是pytorch的初学者,可以使用这个库:https://github.com/deephub-ai/torch-handle,他会对你有很大的帮助。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





