PyTorch多卡分布式训练:DistributedDataParallel (DDP) 简要分析

©作者 | 伟大是熬出来的
单位 | 同济大学
研究方向 | 机器阅读理解

model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])

nn.DistributedDataParallel 原理
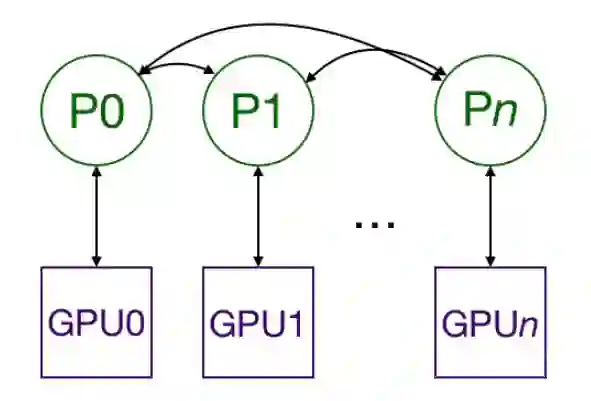

运行模板
import os
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
-
backend:使用的后端。包括 mpi , gloo , 和 nccl 。根据官方文档的介绍,nccl 是运行速度最快的,因此大多设置为这个 -
rank:当前进程的等级。在 DDP 管理的进程组中,每个独立的进程需要知道自己在所有进程中的阶序,我们称为 rank world_size:在 DDP 管理的进程组中,每个独立的进程还需要知道进程组中管理进程的数量,我们称为 world_size
ef setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
-
每个进程都需要复制一份模型以及数据。我们需要根据前文提到的 rank 和 world_size 两个参数初始化进程组。这样进程之间才能相互通信。使用我们前文定义的 setup() 方法实现; -
model = ToyModel().to(rank) 这条语句将我们的模型移动到对应的 GPU中, rank 参数作为进程之间的阶序,可以理解为当前进程 index。由于每个进程都管理自己的 GPU,因此通过阶序可以索引到对应的 GPU; ddp_model = DDP(model, device_ids=[rank])这条语句包装了我们的模型;
其他与 pytorch 中训练模型的模板相同,最后一点需要注意的是,在我们将 tensor 移动到 GPU 的时候,同样需要使用 rank 索引,代码中体现在第 14 行。
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
-
torch.distributed.launch 启动器,用于在命令行分布式地执行 python 文件。在执行过程中,启动器会将当前进程的(其实就是 GPU 的)index 通过参数传递给 python。在使用的时候执行语句 CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py 调用启动器 torch.distributed.launch。
本例中使用的是第二种方法 torch.multiprocessing.spawn。使用时,只需要调用 torch.multiprocessing.spawn,torch.multiprocessing 就会帮助我们自动创建进程。
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# On Windows platform, the torch.distributed package only
# supports Gloo backend, FileStore and TcpStore.
# For FileStore, set init_method parameter in init_process_group
# to a local file. Example as follow:
# init_method="file:///f:/libtmp/some_file"
# dist.init_process_group(
# "gloo",
# rank=rank,
# init_method=init_method,
# world_size=world_size)
# For TcpStore, same way as on Linux.
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
run_demo(demo_basic, world_size)
Running basic DDP example on Rank 1
Running basic DDP example on Rank 0
import os
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def run(demo_fn, world_size):
setup(rank, world_size)
torch.manual_seed(18)
torch.cuda.manual_seed_all(18)
torch.backends.cudnn.deterministic = True
torch.cuda.set_device(rank) # 这里设置 device ,后面可以直接使用 data.cuda(),否则需要指定 rank
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
train_sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data = data.cuda()
target = target.cuda()
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
mp.spawn(run,
args=(world_size,),
nprocs=world_size,
join=True)-
init_process_group 函数管理进程组
-
在创建 Dataloader 的过程中,需要使用 DistributedSampler 采样器
-
正反向传播之前需要将数据以及模型移动到对应 GPU,通过参数 rank 进行索引,还要将模型使用 DistributedDataParallel 进行包装
-
在每个 epoch 开始之前,需要使用 train_sampler.set_epoch(epoch) 为 train_sampler 指定 epoch,这样做可以使每个 epoch 划分给不同进程的 minibatch 不同,从而在整个训练过程中,不同的进程有机会接触到更多的训练数据
使用启动器进行启动。不同启动器对应不同的代码。torch.distributed.launch 通过命令行的方法执行,torch.multiprocessing.spawn 则可以直接运行程序。
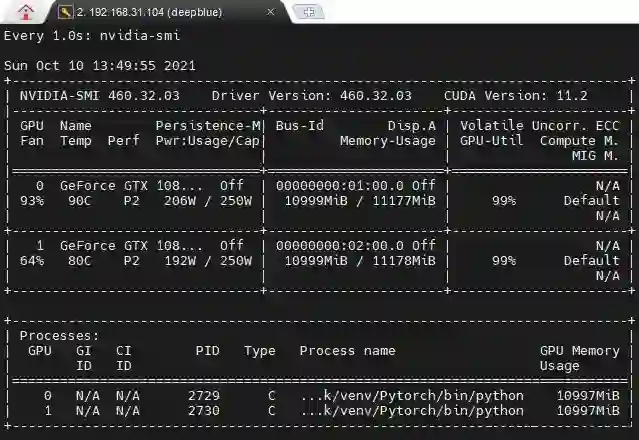

参考文献
注:下述文献大多使用 torch.distributed.launch 启动器执行程序
[1] 当代研究生应当掌握的并行训练方法(单机多卡):
https://zhuanlan.zhihu.com/p/98535650
[2] PyTorch Parallel Training(单机多卡并行、混合精度、同步BN训练指南文档):https://zhuanlan.zhihu.com/p/145427849
[3] pytorch多卡分布式训练简要分析:https://zhuanlan.zhihu.com/p/159404316
[4] Pytorch中的Distributed Data Parallel与混合精度训练(Apex):https://zhuanlan.zhihu.com/p/105755472
[5] PyTorch分布式训练基础--DDP使用:https://zhuanlan.zhihu.com/p/358974461
[6] 使用PyTorch编写分布式应用程序:https://www.jianshu.com/p/be9f8b90a1b8?utm_campaign=hugo&utm_medium=reader_share&utm_content=note&utm_source=weixin-friends
[7] DistributedSampler 具体做了什么:https://blog.csdn.net/searobbers_duck/article/details/115299691?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
[8] Pytorch的nn.DataParallel:https://zhuanlan.zhihu.com/p/102697821
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





