案例分享丨AI 物品识别技术解决零售业难题,看看品览怎么做

引言:品览是一家基于计算机视觉技术,面向企业客户提供人工智能解决方案的科技服务公司。专注于打造世界一流的 AI 物品识别平台,面向消费品、零售企业提供 AI 智能营销/物流方案。在 AI 应用领域,团队服务过上汽集团(安吉物流)、顶新集团(味全)、欣和集团、喜士多、Farfetch 等客户。
零售行业的货架战争
为了在庞大的线下终端赢得消费者的选择,争夺产品在货架上的露出位置和比例,跟哪些竞品在一起露出,以及如何通过货架陈列,使产品的视觉呈现更能吸引消费者购买,目前成为快消企业终端执行的重中之重。

然而在门店实际执行过程中经常会出现的情况:生动化陈列执行不到位,如缺少必销品,重点商品、新品陈列没有占据醒目位置,排面靠后或被竞品压制,摆放不整齐、生动化物料没有展示出来等情况屡见不鲜。当货架缺货的情况发生时,品牌商可能会失去 46% 的购买者,而零售商可能会失去 30% 的购买者。
-
超强且庞大的线下执行团队; 利用 AI 物品识别技术辅助人工完成陈列审查这件事。
品览基于 TensorFlow 开发了物品识别平台 — AI 亿览通,帮助零售行业客户掌握一手门店数据,优化货架执行和提高坪效。
AI 亿览通技术难点及解题思路
品览旗下主要产品 AI 亿览通,以商品识别引擎为核心,基于自身前沿的结合弱监督与细粒度识别算法,商品识别准确度高达 97% 以上,目前可实现商品 SKU 种类、在货架上的陈列位置、价签及生动化物料识别检测等功能。
-
在货架场景中,商品通常会摆放的非常密集,要想准确无误的统计排面识别每个 SKU,需要超高准确率和召回率的商品检测; -
商品种类繁多,一般商品的 SKU 种类数量上万,甚至高达几十万,单一模型无法完全支持; -
同品牌 SKU 之间非常相似,特征看上去没有明显的差异,需要攻克细粒度分类难题; 同一款商品可能有不同的规格,比如可乐,可能会有 330 毫升、500 毫升,或一升的,它更像是等比例缩放,因为计算机视觉天然是要求有尺度不变性的,这种情况通常是很难区分的。

1. 商品识别的流程

高质量完成商品识别的前提是拥有完美的数据,巡店员为了快速完成任务多数情况下一张照片拍上整个货架,导致在图片数据中货架倾斜严重,这对后续的商品检测识别十分不利,采用 TF 框架搭建的 Mask R-CNN 实例分割算法对图片中的货架层进行分割,
△ 实例分割 Mask R-CNN 框架
根据分割的货架线,使用仿射变换进行货架的倾斜矫正,完美解决货架倾斜的问题。

△ 货架线分割效果图
分割模型参考
https://github.com/matterport/Mask_RCNN
针对零售行业复杂的场景,便利店/超市/小卖店等物品的摆放及巡店人员的拍摄习惯等,我们采用 RetinaNet 目标检测模型进行商品检测,该目标检测模型创新性提出了 Focal loss(如图 1 所示)作为训练的损失函数,可以有效的解决训练过程中正负样本不平衡的问题.
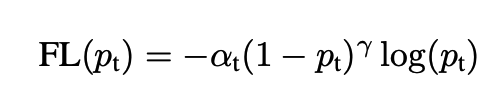
△ 图 1
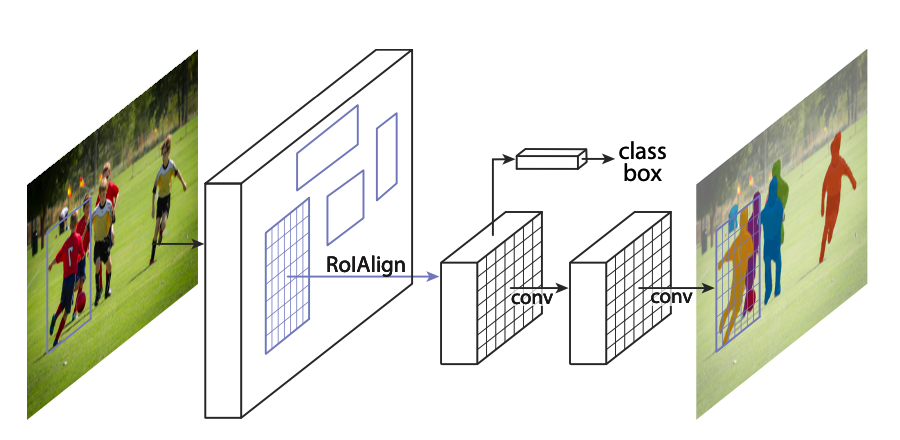
结合 Focal Loss 该模型设计了一个简单的 one-stage detector 来进行检测,网络结构名为 RetinaNet(如下图 2):
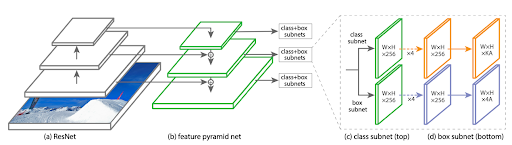
△ 图 2 RetinaNet
该模型采用了 FPN 结构进行多层网络特征的融合,可以有效的兼容不同尺度训练数据,优化小目标的检测效果。使用 TensorFlow 的内置函数来构建 FPN 结构和计算 Focal Loss,模型训练速度快,可在短时间内进行多次模型迭代,提高了模型的训练效率,并在训练过程中使用 tensorflow.summary 记录 loss 和 accuracy,可以实时监测模型的收敛情况。随着 TensorFlow 的发展完善,搭建新模型时很多结构可以从 TensorFlow 的官方复现中直接提取使用,当成固定的模块,加速了模型构建速度。
RetinaNet 请参考
https://github.com/fizyr/tf-retinanet
面对海量 SKU,采用 Resnet50 深度学习网络进行模型训练,该网络结构由何凯明团队在 2015 年提出,一经问世就引起轰动,成为近年来最经典的特征提取网络结构之一,其亮点在于残差网络结构(如下图所示):
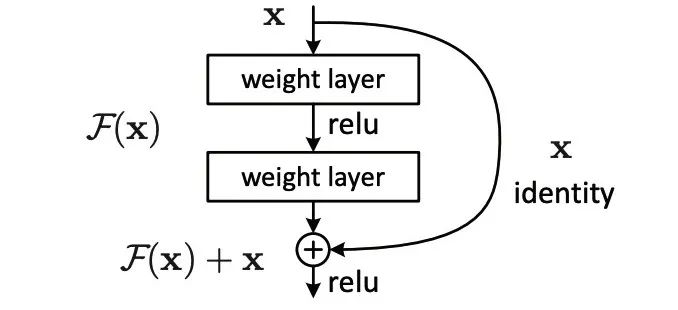
对于同一品牌包装十分相似的商品,在特征提取网络中加入 Attention 机制,进行细粒度区分,利用 TensorFlow 框架完成模型的搭建,进行 SKU 分类模型的训练,方便快捷。使用 TensorBoard 进行训练过程可视化,不仅可以监测模型训练过程中 loss 的下降趋势,方便训练调参,并可以可视化搭建的网络模型结构,方便更好的学习和理解深度神经网络。
Resnet 参考
https://github.com/ry/tensorflow-resnet
-
支持 docker 部署:常用的部署方式是使用 docker 部署,将宿主机的模型目录挂载在 docker 的虚拟目录下,拉取的 docker 镜像可选择支持 CPU 或 GPU,也提供了版本选择,方便调试。 -
支持多种通信方式:目前 TF Serving 的客户端和服务端支持的的通信方式为:gRPC 和 REST API,前者端口为 8500,后者为 8501,两种方式分别对应了不同的传输方法。 挂载模型简单:使用 TF Serving 部署模型,不需要部署代码,但需要必要的客户端代码。因为模型使用挂载的方式,对同一模型的不同版本,Serving 会自动刷新选择最新的模型版本,更新版本也不需要重启服务。同时 TF Serving 也支持多模型部署,因而使用起来比较方便。
应用效果展示
以欣和集团为例,旗下拥有 11 个调味品牌,商品覆盖全国 1400 个县区,门店数量极其庞大。在使用 AI 亿览通服务之前,通常采取的是人工抽检的方式,每周需要一天 20 人次投入审核工作,使用品览的服务进行 AI 自动化后,仅需 1 人督导即可完成审核。
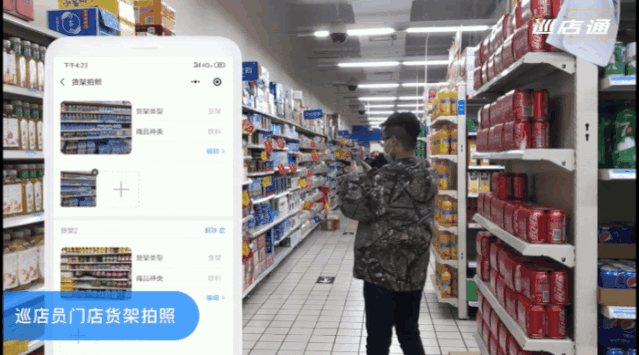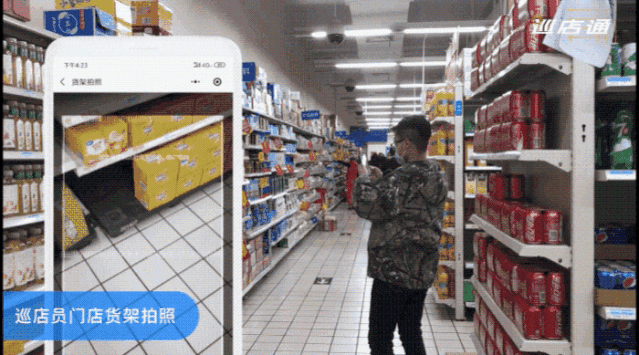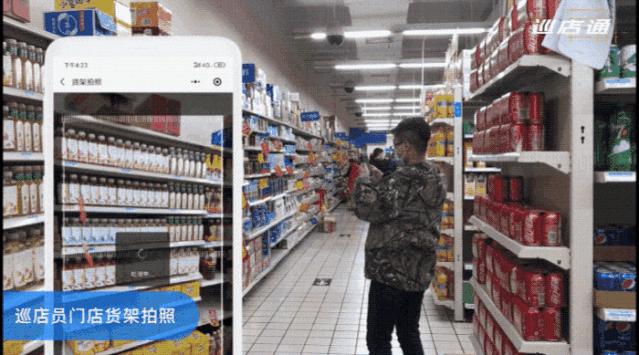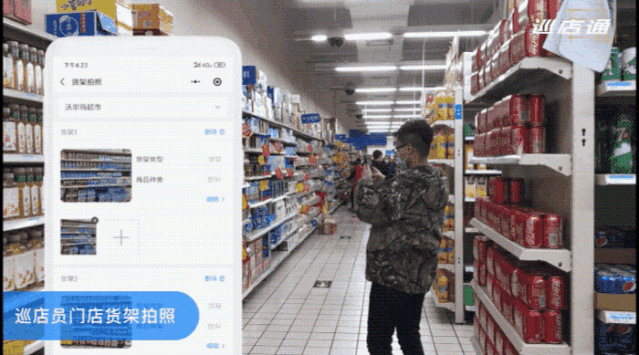
△ 巡店员从小程序拍照上传即可
由于欣和的海量产品和门店,拥有十分复杂的陈列场景。亿览通不仅支持货架、端架、冰箱、堆头、地龙等丰富场景,货架插卡、贴条、价格签、爆炸牌、跳跳卡、颈标、商品贴等多种生动化陈列物料,还能检测图片质量是否过于倾斜、模糊,通过图像/视频拼接呈现品类完整货架陈列,并具备分秒级批量审核数万张货架照片的能力。
△ 分秒级批量审核能力

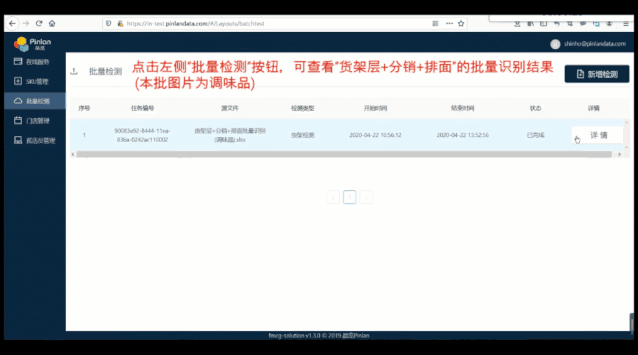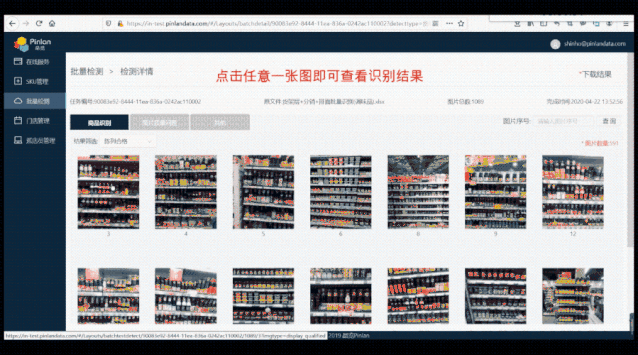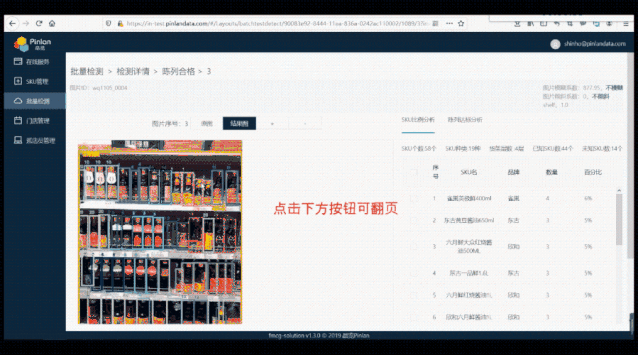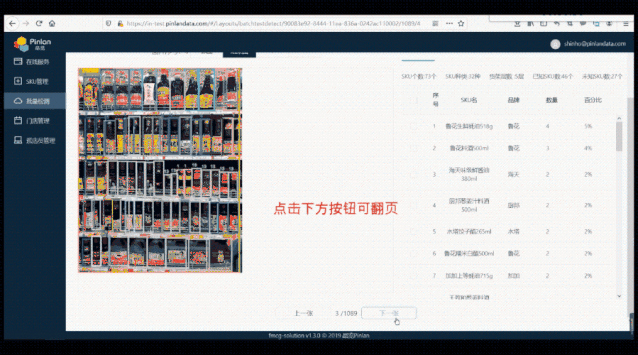
△ 后台识别结果,显示了货架 SKU 比例分析、是否陈列达标等信息
使用 AI 亿览通后,欣和实现了生动化陈列审核自动化,从抽检改为全面审核每家门店的陈列;检核周期从每周缩短为每天;在释放了人力资源的情况下,整体工作效率提升 95%。
RP2K 数据集发布
AI 技术的落地实践与应用越来越方便,随着各种强大的数据集发布,机器学习模型训练无需再亲自采集数据,数据训练集唾手可得。拥有强大的零售货架商品识别经验的品览,近期正式发布了 RP2K 零售品数据集。

不同于一般聚焦新产品的数据集,RP2K 收录了超过 50 万张零售商品货架图片,商品种类超过 2000 种,该数据集是目前同类别数据集中产品种类数量之最,同时所有图片均来自于真实场景下的人工采集,针对每种商品,我们提供了十分详细的注释,包含尺寸/形状/味道等特征。RP2K 致力于帮助物品识别领域进行学术研究,同时为 AI 物品识别从业者打造真实行业级试炼场,欢迎访问品览官网下载使用。
数据集
https://www.pinlandata.com/rp2k_datasetRP2K 数据集论文
https://arxiv.org/abs/2006.12634
总结
本文从零售品牌商普遍存在的门店执行痛点出发,分析了赢得“货架战争”的关键点——利用AI物品识别技术替代人工完成陈列审查,提高货架数据准确度和效率。
在商品识别的技术实践中,我们进行了多角度的检测模型实验和数据优化方法。从检测到分类到可视化调参,TensorFlow 都起到了不可替代的作用和帮助。
如果您想在 TensorFlow 社区分享经验与用例,点击 “阅读原文” 填写相关信息,我们会尽快与您联系。






