机器学习(25)之K-Means聚类算法详解
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
前言
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化elkan K-Means算法和大数据情况下的优化Mini Batch K-Means算法。
K-M原理
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为(C1,C2,...Ck),则我们的目标是最小化平方误差E:
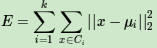
其中μi是簇Ci的均值向量,有时也称为质心,表达式为:
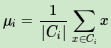
如果我们想直接求上式的最小值并不容易,这是一个NP难的问题,因此只能采用启发式的迭代方法。K-Means采用的启发式方式很简单,用下面一组图就可以形象的描述。
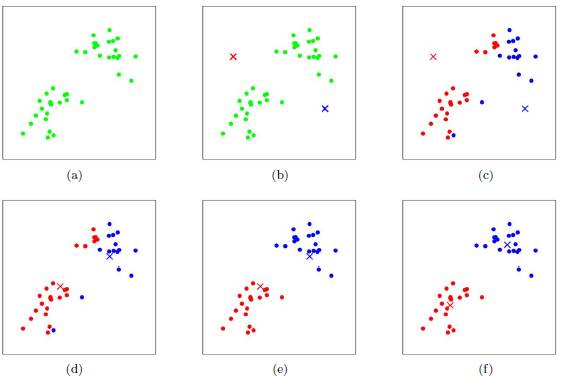
上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对当前标记为红色和蓝色的点分别求其新的质心,如图d所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。
当然在实际K-Mean算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
经典K-Meams算法流程
首先我们看看K-Means算法的一些要点。
1)对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2)在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
好了,现在我们来总结下传统的K-Means算法流程。
输入:样本集D={x1,x2,...xm},聚类的簇树k,最大迭代次数N
输出:簇划分C={C1,C2,...Ck}
算法流程
1) 从数据集D中随机选择k个样本作为初始的k个质心向量: {μ1,μ2,...,μk}
2)对于n=1,2,...,N
a) 将簇划分C初始化为Ct=∅,t=1,2...k
b) 对于i=1,2...m,计算样本xi和各个质心向量μj (j=1,2,...k)的距离:
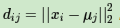
将xi标记最小的为dij所对应的类别λi。此时更新Cλi=Cλi∪{xi}
c) 对于j=1,2,...,k,对Cj中所有的样本点重新计算新的质心
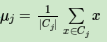
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分
K-Means不同改进版本
初始化优化版:K-Means++
在上节我们提到,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means++算法就是对K-Means随机初始化质心的方法的优化。
K-Means++的对于初始化质心的优化策略也很简单,如下:
a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心μ1
b) 对于数据集中的每一个点xi,计算它与已选择的聚类中心中最近聚类中心的距离
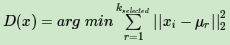
c) 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
d) 重复b和c直到选择出k个聚类质心
e) 利用这k个质心来作为初始化质心去运行标准的K-Means算法
距离计算优化版:elkan K-Means
在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有的质心的距离,这样会比较的耗时。那么,对于距离的计算有没有能够简化的地方呢?elkan K-Means算法就是从这块入手加以改进。它的目标是减少不必要的距离的计算。那么哪些距离不需要计算呢?elkan K-Means利用了两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算。
第一种规律是对于一个样本点x和两个质心μj1,μj2。如果我们预先计算出了这两个质心之间的距离D(j1,j2),则如果计算发现2D(x,j1)≤D(j1,j2),我们立即就可以知道D(x,j1)≤D(x,j2)。此时我们不需要再计算D(x,j2),也就是说省了一步距离计算。
第二种规律是对于一个样本点x和两个质心μj1,μj2。我们可以得到D(x,j2)≥max{0,D(x,j1)−D(j1,j2)}。这个从三角形的性质也很容易得到。
利用上边的两个规律,elkan K-Means比起传统的K-Means迭代速度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法。
大样本优化版:Mini Batch K-Means
在统的K-Means算法中,要计算所有的样本点到所有的质心的距离。如果样本量非常大,比如达到10万以上,特征有100以上,此时用传统的K-Means算法非常的耗时,就算加上elkan K-Means优化也依旧。在大数据时代,这样的场景越来越多。此时Mini Batch K-Means应运而生。顾名思义,Mini Batch,也就是用样本集中的一部分的样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在Mini Batch K-Means中,我们会选择一个合适的批样本大小batch size,我们仅仅用batch size个样本来做K-Means聚类。那么这batch size个样本怎么来的?一般是通过无放回的随机采样得到的。为了增加算法的准确性,我们一般会多跑几次Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
K-Means与KNN
初学者很容易把K-Means和KNN搞混,两者其实差别还是很大的。K-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别.当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻(nearest neighbors)的思想。
K-Means小结
K-Means是个简单实用的聚类算法,这里对K-Means的优缺点做一个总结。
优点
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
缺点
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感。
欢迎分享给他人让更多的人受益

参考:
周志华《机器学习》
Neural Networks and Deep Learning by By Michael Nielsen
博客园
http://www.cnblogs.com/pinard/p/6164214.html
李航《统计学习方法》

加我微信:guodongwe1991,备注姓名-单位-研究方向(加入微信机器学习交流1群)
招募 志愿者
广告、商业合作
请加QQ:357062955@qq.com

喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!