AI开拓者Yann LeCun:深度网络优雅又闪耀 | 福布斯人物专题

大数据文摘出品
编译:雪清、Jonykai、陈同学、蒋宝尚
20世纪80年代中期,Mullet发型和粉红格子夹克大行其道(译者注:mullet发型是一种文化现象),精力充沛的Richard Simmons刚刚掀起健身狂潮,而人工智能(AI)方面的研究却几乎陷于停滞状态。
一方面,那时候计算机的计算能力还远达不到要求。早期的软盘驱动器在复杂程度上与现代的智能手机相比是小巫见大巫,计算机芯片在1989年以前也容纳不了数百万个组件,现今这个数字可以达到80亿。
另一方面,一片挥之不去的阴霾使得关于人工智能的一切幻想难以变为现实。1984年,美国人工智能学会举行了一次重大的会议,会议中该领域的先驱Marvin Minsky站出来警告商界:投资者对人工智能的热情最终带来的只会是失望。果不其然,人工智能投资开始逐步走向崩溃。
*Marvin Minsky:
http://web.media.mit.edu/~minsky/minskybiog.html
现在看来,像Yann LeCun这样有远见的人没有持太多的悲观主义是一件幸事。这位土生土长的法国人,在加入新泽西州AT&T贝尔实验室的自适应系统研究部门时,甚至还不到30岁。
在那里,他对人工智能的热情日益高涨。
LeCun在贝尔实验室研究出了许多新的机器学习方法,其中包括卷积神经网络——由动物视觉皮质启发的模型。并且他的工作也促进了图像和视频识别,以及自然语言处理的进步。

“20世纪60年代后期,人工智能背景下的统计学习方法就像被判了死刑”,LeCun回忆道。“人们或多或少地放弃了它。不过由于人们对神经网络的兴趣,它在80年代后期又重新回到了我们面前。当训练多层神经网络的学习算法在80年代中期出现时,统计学习方法曾掀起了一股热潮。”
在叙说这场革命的过程中,LeCun显得有点谦虚过头了。他的发现创造了历史,但他几乎没有提到过自己的名字或是成就。他拒绝把自己当回事;事实上他的个人网站上会有一整节全是双关语俏皮话,其中有这样的自我告诫:“反酷刑的日内瓦公约,以及反对残酷和施暴行为的美国宪法,禁止我凶残地连续使用三个以上双关语。”
LeCun也拒绝止步于自己在计算机科学方面业已获得的成就;如今,他担任Facebook的首席AI科学家,不知疲倦地努力实现新的突破。现在,我们跟着他来享受一次特权之旅——零距离接触这位学术明星——一起来探讨人工智能的成长历程,最新的变化以及它的潜力。
人工智能的开端——感知器触碰学习的边缘
LeCun熟知人工智能的发展历程,对其中的里程碑事件以及重要的人物如数家珍。故事从1956年夏天在达特茅斯举行的头脑风暴会议开始,“人工智能”一词即创造于此。

仅仅一年之后,Frank Rosenblatt在康奈尔航空实验室发明了感知器。其早期的实现之一是Mark 1感知器,这是一台庞大的矩形机器,包含400个光电池,它们被随机地连接到简单的图案检测器上,这些检测器将被用于可训练的分类器。
*Mark 1感知器:
http://www.dtic.mil/dtic/tr/fulltext/u2/236965.pdf
“这是首个能够学会以一种非平凡的方式识别简单图案的神经网络”,LeCun说。“你可以使用它们进行简单的图像识别,但它们不能识别出图像中的物体,也不能用于任何推理或设计。”
一直到过去十年,模式识别系统都需要大量的手工作业来识别自然图像中的物体。“你必须做很多工作以构建一个可以对图像做出表述的工程模块——这种表述通常是能被这些简单的学习算法处理的一长串数字。因此,基本上你不得不手工完成这项工作。” 他补充说,早期的语音识别和机器翻译也是类似的情况:手工操作意味着要付出更多的努力,但收获甚微。
那么,迄今为止,计算机科学究竟发生了什么变化?“在所有这些应用中,深度学习和神经网络已经带来了显著的性能提升——并且大大减少了之前必要的手工劳动”,LeCun说。“这使得人们可以将这些应用扩展到许多不同的领域。”
那么问题来啦,计算机在一开始如何“学习”。
神经网络就像是大脑的软件模拟;它们处理诸如视觉图像之类的信息并试图得出正确的答案。但是,如果答案并不是很正确呢?这就要说到“反向传播”了,它是一种让神经网络能够学习的反馈流算法。
LeCun和反向传播
1986年,反向传播迎来了突破性的发现。当时,Geoffrey Hinton教授指出计算机可以通过反复执行任务来学习,每次都让神经网络“向误差减小的方向调整”,他也成为最早描述该方法的研究者之一。
LeCun不仅实现了Hinton的早期理论,他还帮助奠定了基础。20世纪80年代早期,Hinton首先提出了“反向传播”的观点,但放弃了它,因为他认为它不起作用。
但在1985年,LeCun撰写了一篇论文,描述了一种反向传播的形式,正如他所说,“这是一个不起眼的会议。论文是用法语写的,基本上没有什么人阅读,但至少出现了一个重要的人。”而那个人就是Hinton。LeCun之后到了多伦多大学,在Hinton的指导下担任博士后研究助理,再后来他开始在AT&T贝尔实验室(晶体管的诞生地)工作。
“所有机器学习都是关于误差矫正的”,LeCun解释道。想象一下,向计算机展示“成千上万的汽车和飞机图像,每次参数自我调整一点,输出就越接近正确的——如果你足够幸运的话,最终会确定一个结构,这时每辆汽车和每架飞机都能被正确识别。”
当他描述最终结果时,LeCun的回答让人敬畏:“学习的神奇之处在于,即使系统从未见过的图像也会被正确分类。”
尽管如此,他还是免不了变得有点淘气。“有各种各样的技巧可以让反向传播起作用,它仍然是一种神秘魔法——但现在我们有了一个秘诀。如果你遵循这个秘诀,它每次都会奏效。”
数据,AI和商业:未来和局限

人工智能时代的数据被喻为新黄金、新石油、新货币。是的,当今人人都知道:从审计到电子商务,数据对企业来说非常有价值。但是为了发挥出数据的作用,企业中的管理者就要区分数据能做什么和不能做什么。
LeCun认为:“对于用机器学习赋能业务,数据非常重要。你需要数据来训练你的系统。拥有的数据越多,系统就越准确。因此,不管从技术目标还是业务角度来看,数据都是多多益善的。”
但使用一段时间,你就会发现数据成了油腻的培根:也就是说,它无法让智能化的机器更加智能。
“无论是Facebook、Deep Mind、Google Brain还是其他机构的研究者,我们在研究人工智能时,都不使用内部数据来测试它们,”LeCun说道。“使用公共数据能够将我们的方法与学术界其他人的进行比较。拥有更多数据对于开发更好的方法并不重要。实际上,我们使用尽可能少的数据量,来使模型达到很好的表现。”
在学术研究中尤其如此,其中关键角色不是要处理大量的数据,而是成为LeCun所说的“新思想的先锋”。
“数据对于利用机器学习创造业务非常重要。你需要数据来训练你的系统。拥有的数据越多,系统就越准确。”
——Yann LeCun
同时,构建人工智能战略的企业需要在寻找解决方案之前进行自我评估。“这取决于AI对你的系统有多重要,”LeCun指出。“如果只想应用现有的AI方法,可以直接使用云服务。那么这样会相对容易。”一些企业和出租技术可以帮助人工智能的部署。
最大的挑战是那些希望建立自己的工程团队的公司。LeCun说:“总体来说,现在对人工智能工程师和科学家们的需求很高,而人才很稀缺,所以你必须付高价来雇佣他们。”
两种学习方式,一个光明的未来

LeCun概述了人工智能中两种不同类型的学习:监督学习和无监督学习。监督学习适用于大部分机器学习的场景。利用监督学习,研究人员们训练模型来更好地识别图像或其他形式的输入。比如你可以把它想象成旋钮,通过自动调整,使机器的输出更接近你想要的。
虽然无监督学习或“自我监督”的学习在当今机器学习中占比很小,但却拥有很大的潜力。LeCun说:“这种学习方法是从本质上预测我们在世界上所感知到的一切。
现在的情况似乎是,需要预测将要发生什么才能获得下一步的突破。但可以肯定的是,对于科学家、学术界和高科技巨头来说,探索无监督学习的吸引力太大了。
这个研究的回报将能够完成我们目前不能做的所有应用。所以,希望能拥有智能虚拟助理,同他们交谈并理解你所说的一切。他们会切实地在日常生活中真正地帮助到你。
“这有点像电影《她》,你看过那部电影吗?”
简单介绍一下:这部电影在2013年由Spike Jonze执导,讲的是Joaquin Phoenix扮演的一个孤独作家,爱上了由Scarlett Johansson配音的虚拟助手。LeCun毫不掩盖对它的喜爱之情。

《她》电影海报
“这部影片描绘了人工智能成熟后,人们和他们的虚拟助手之间可能会发生交流,”他补充道说。“我们离发展出这样的AI技术还有很长的路要走。主要是因为现有的机器缺乏常识。”
“家猫都比最聪明的机器要更通人性”
——Yann LeCun
常识?但是在很多情况下机器不会比人类做出更好的决定吗?机器必须具有常识或者表现出来么?
LeCun解释了为什么他们不这样做:“我们没有能力让机器学习庞大的背景知识:我们在生命的最初几周和几个月中得到了关于世界的大量背景知识,这和很多动物类似。”
因此,我们都知道机器人不能触水,就更别说洗碗水了。LeCun认为:我们制造不出灵巧的机器人,因为这些都超出了目前机器人技术的最新水平。不是我们无法制造机器人,而是我们不知道如何建立他们的大脑。我们不知道如何训练机器人理解我们的日常活动,例如绕过障碍以及如何放置物品。
鉴于LeCun在人工智能应用方面的地位,他的话听起似乎有些草率。但是,当他考虑到人工智能在医疗等领域的飞速发展时,他仍然对人工智能的未来抱有很大的希望与好奇。
他认为,通过医学图像分析,可以训练卷积神经网络来检测CT扫描图或MRIS中的肿瘤,或者从皮肤图像中检测黑色素瘤,这将对放射学产生深远的影响。
这正应了LeCun在7月8日,也就是58岁说过的一句话:“深度网络既优雅又闪耀。”
相关报道:
https://www.forbes.com/sites/insights-intelai/2018/07/17/yann-lecun-an-ai-groundbreaker-takes-stock/#84757b4586c8
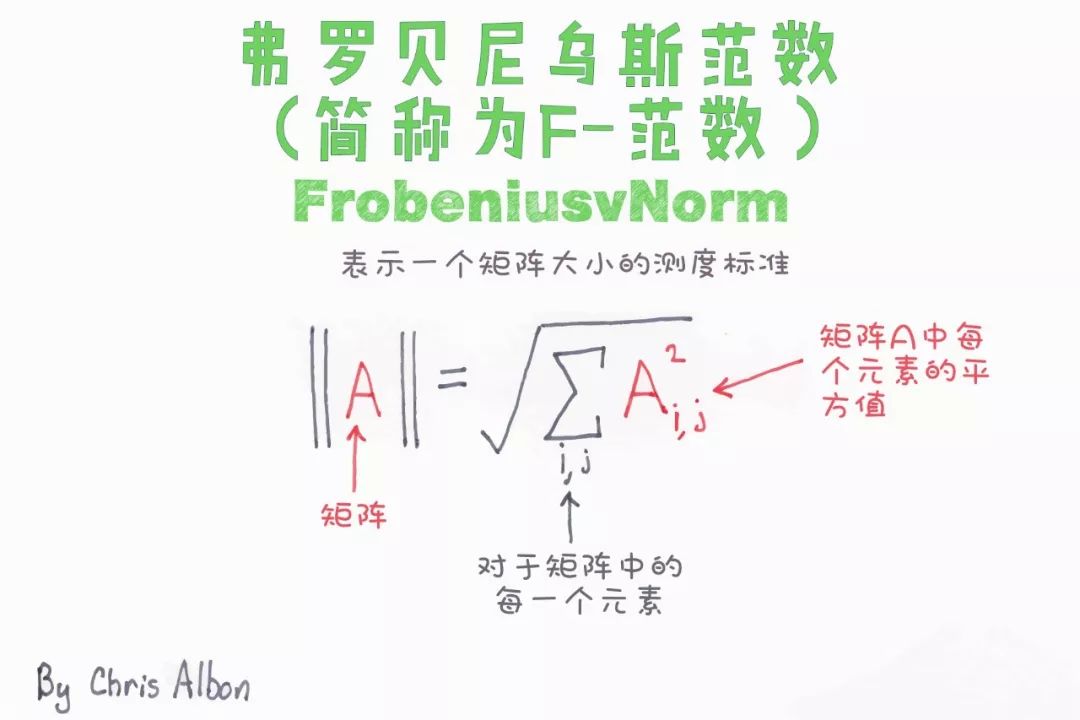
【今日机器学习概念】
Have a Great Definition

Contributors
回复“志愿者”加入我们








