提升 10 倍!阿里云对象存储 OSS 可用性 SLA 技术揭秘

阿里妹导读:对象存储被广泛应用于互联网应用中,当我们打开手机观看视频、收听音乐、分享图片、浏览网页、淘宝购物时,背后的数据基本都是存在对象存储中。应用使用卡、打不开就和对象存储的可用性 SLA 有关,SLA 越高,应用体验越好。本文分享阿里云在对象存储 OSS(Open Storage Service) 的可用性 SLA (Service Level Agreement) 上的实践和技术沉淀。
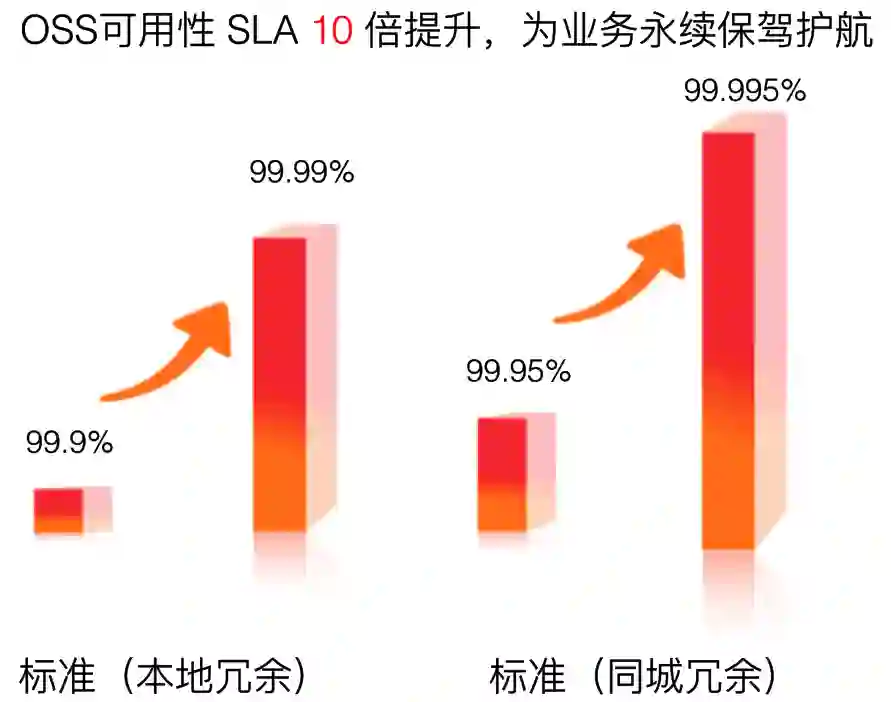
T1 机房:可用性 99.671%、年平均故障时间 28.8 小时
T2 机房:可用性 99.741%、年平均故障时间 22 小时
T3 机房:可用性 99.982%、年平均故障时间 1.6 小时
T4 机房:可用性 99.995%、年平均故障时间 0.4 小时
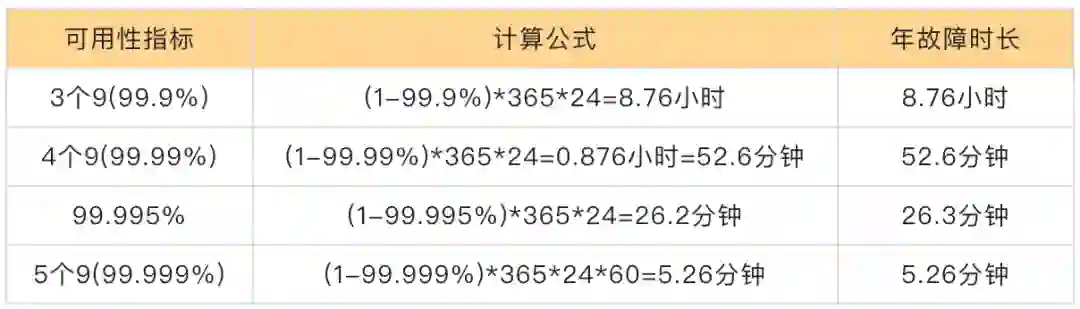
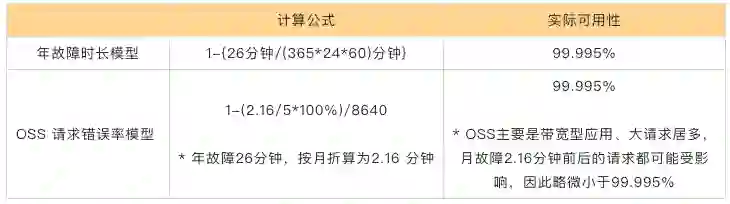
每5分钟错误率 = 每5分钟失败请求数/每5分钟有效总请求数*100%服务可用性 =(1-服务周期内∑每5分钟错误率/服务周期内5分钟总个数)*100%按照全年 26 分钟故障为基础,年故障时长模型可用性为 99.995%。而 OSS 的请求错误率模型下,全年 26 分钟平均到每月大约故障 2.16 分钟,按每5分钟错误率来算,如果请求在 2.16 分钟内则全部失败,按比例来说错误率为 (2.16/5)*100%,此时可用性为:
1-{(2.16/5)*100%}/8640=99.995%可以看出,它和年故障市场模型的可用性相同,但 OSS 上主要是带宽型应用、大请求居多,因此在故障的 2.16 分钟前后的请求都会受影响,导致可用性会稍微小于 99.995%,从某种意义上讲 OSS 的请求错误率模型略微严格。
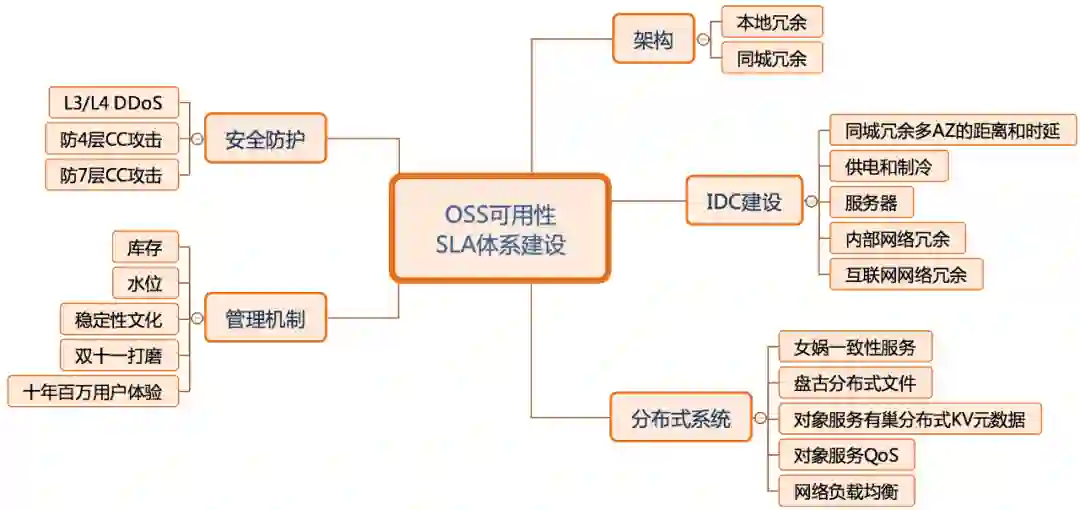
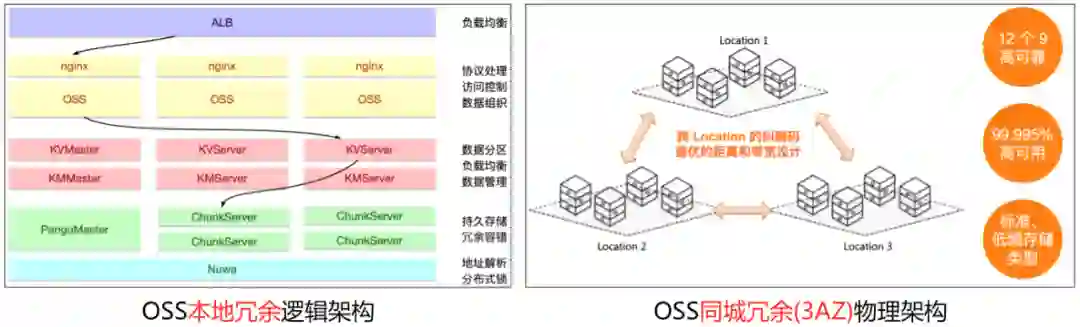
1)同城冗余多 AZ(Available Zone) 的距离和时延设计。在公共云部署时,会遵循阿里云 IDC 与网络架构设计规则及 AZ 选址标准,特别是要满足 OSS 的多 AZ 设计要求时,会严格要求时延和距离。
2)供电、制冷冗余。OSS 对象存储是多区域部署的云服务,几乎每年都会遇到自然灾害、供电异常、空调设备故障等问题,在数据中心建设时要做好双路市电和柴油发电机备电的设计,以及连续制冷能力。
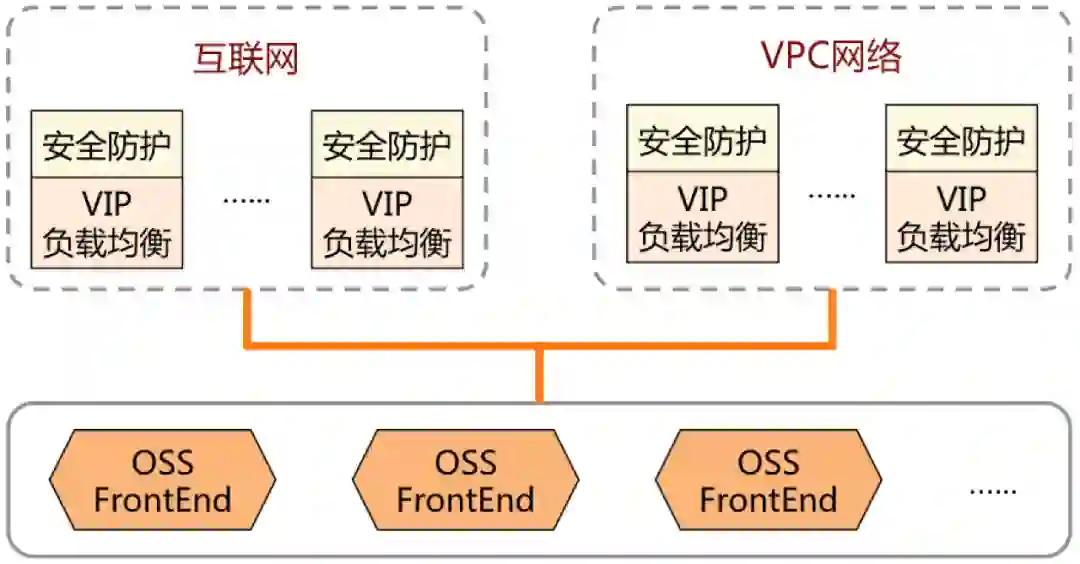
3)网络冗余。OSS 作为公共云服务,既要提供外部的互联网访问、VPC 网络访问,还要提供分布式系统的内部网络连接,它们都需要做好冗余设计。
外部网络。互联网接入多运营商的 BGP 和静态带宽,实现公网访问的冗余。同时,VPC 网络的接入则通过阿里云网络的冗余。
-
内部网络。OSS 是分布式存储,由多台服务器组成,采用内部网络将多台服务器连通起来,通过数据中心的机柜级交换机、机柜间交换机、机房间交换机的分层设计实现冗余,即使某台网络设备故障,系统仍然能够正常工作。
4)服务器。OSS 采用貔貅服务器系列优化性价比,基于分布式系统和软件定义存储的需求,硬件上采用通用服务器(commodity server),并提供冗余的网络接口,无需采用传统存储阵列双控冗余设计的定制硬件。
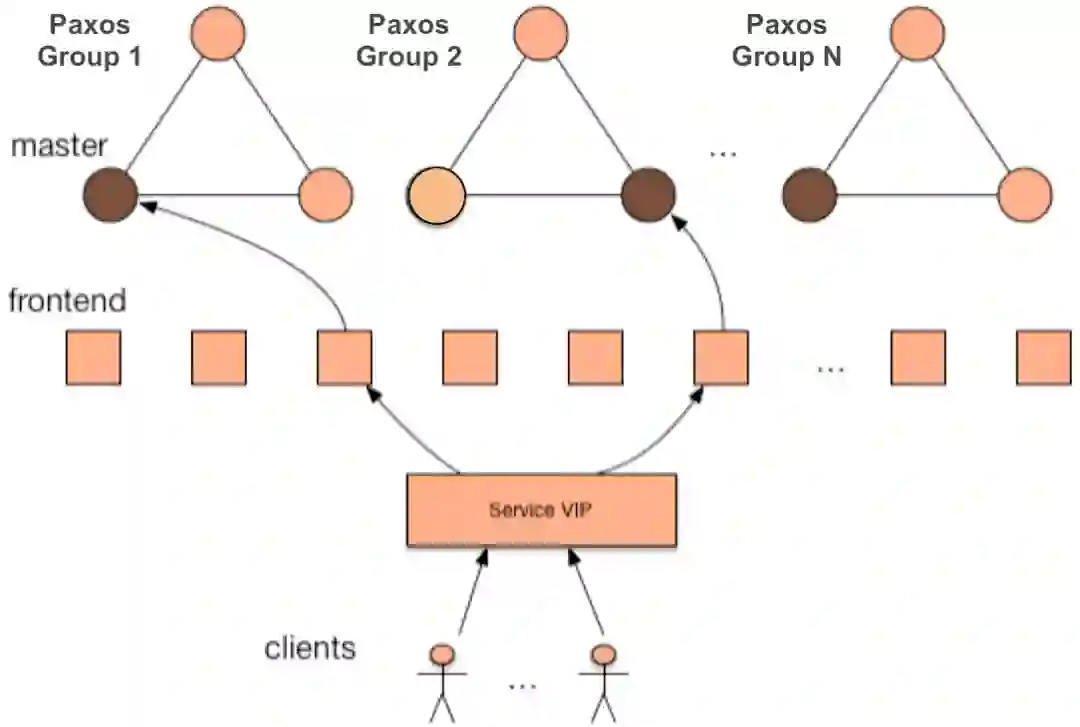
前端机通过 VIP 做负载均衡。主要实现两个功能:第一点,负责维护众多客户端的长连接通信,从而保证客户端请求能够均衡到后端;第二点,向客户端隐藏后端的切换过程,同时提供高效的消息通知功能。
后端由多个服务器组成 PAXOS 组,形成一致性协议核心。对客户端提供的资源(文件,锁等),在后端都有归属的 Paxos Group仲裁,它采用 PAXOS 分布式一致性协议进行同步,保证资源的一致性和持久化。为了提供更好的扩展能力,后端提供了多个 Paxos Group。
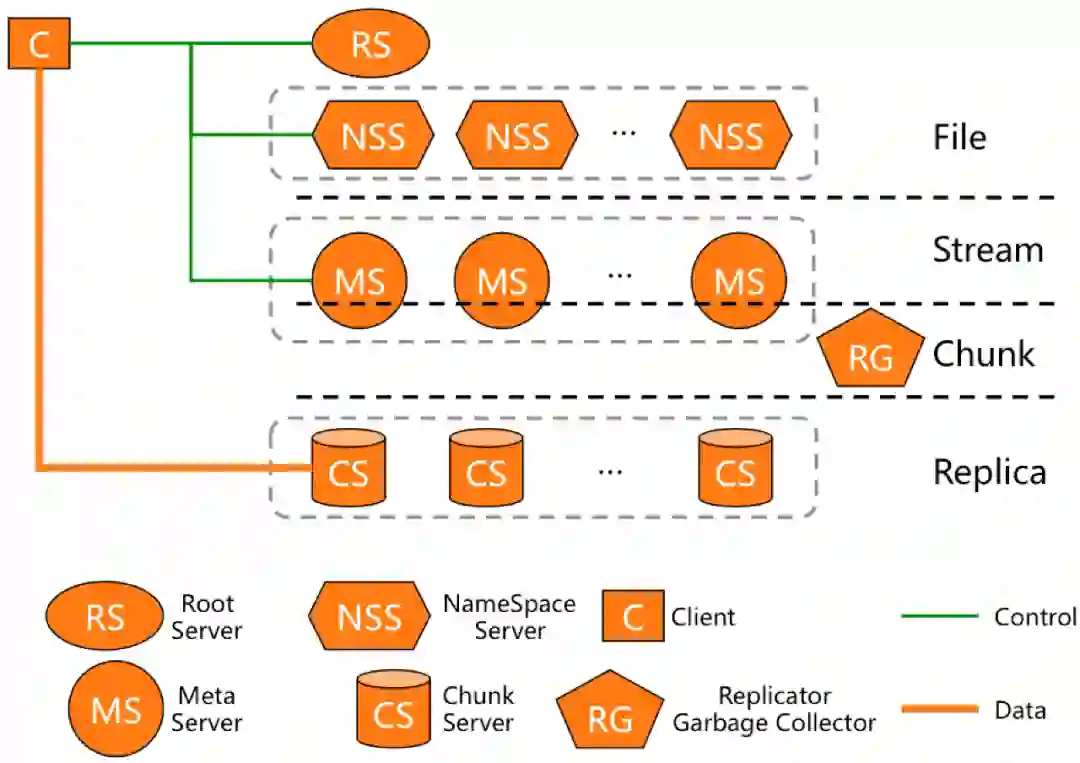
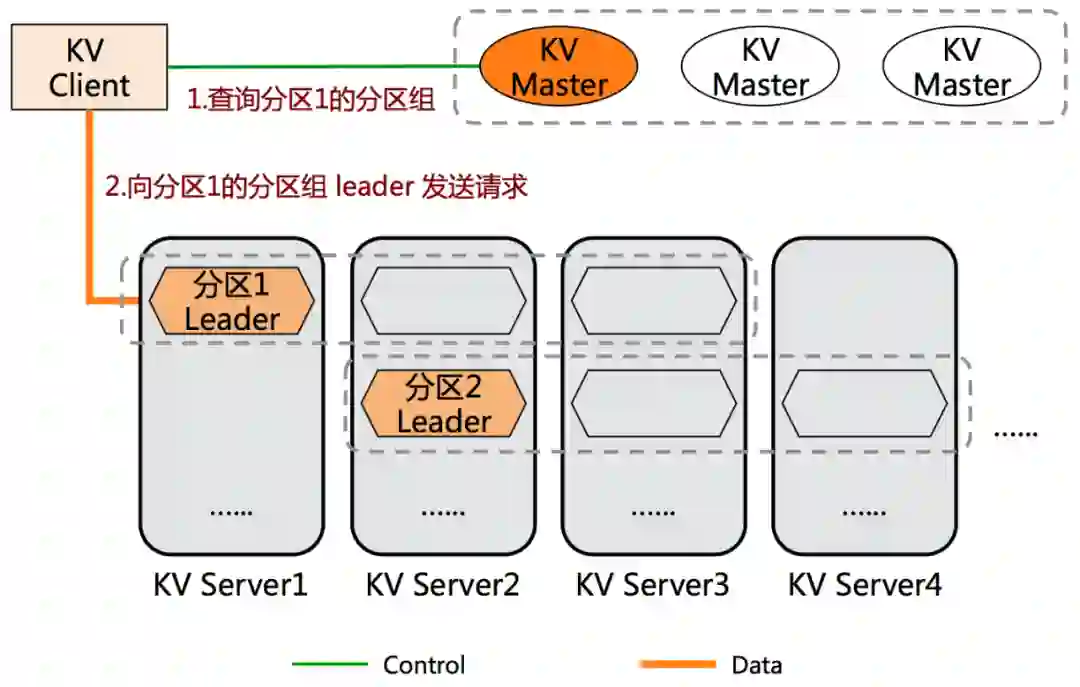
安全攻击的一个目的,就是让 OSS 之上的业务受损失,让整体的可用性降低。
安全攻击的两种方法,就是拥塞 OSS 有限的带宽入口(拥塞带宽)、耗尽 OSS 的计算资源(耗尽资源)。
安全攻击的三类攻击方式,针对拥塞带宽的网络流量型攻击(L3/L4 DDoS),针对耗尽资源的 4 层 CC 攻击(链接资源)、7 层 CC 攻击(应用资源)。

库存管理。公共云服务是重资产模式,需要自己管理供应链库存,智能预测资源需求,按需提供服务是可用性的基本保证。
水位管理。对象存储是云存储服务,监控容量水位、带宽水位、QPS 等水位能力,进行动态的智能调度,可以优化系统的可用性。
稳定性文化。从开发、设计、测试、运维等环节制定稳定性制度,追求卓越的可用性能力。
双十一锤炼和百万级用户打磨。OSS 长期参与阿里集群双十一业务支撑,在业务洪峰的不断锤炼下,持续淬炼产品的架构、特性、稳定性。在阿里云的公共云服务体系下,有百万级用户的打磨,支撑各行各业的负载。经年累月的技术积累,总结了持续提升可用性的机制。
 送书啦
送书啦
伏羲(Fuxi)作为阿里巴巴最初创立飞天平台时的三大服务之一,十年来经历了怎样的技术演进?9 位技术专家深度解析,全面介绍伏羲调度系统及各子领域的关键技术进展,并以双11为典型场景进行最佳实践的介绍,为你呈现大数据分布式调度技术的深水区玩法。
识别下方二维码加「阿里妹」好友,回复 “送书” 立即获取吧~







