CCF ADL92:自然语言理解:新学习方法及知识
对自然语言的理解是很多自然语言处理应用的必要组成部分,包括但不限于翻译,摘要,对话以及问答。在人工智能的时代,基于知识的学习对自然语言理解有极大的帮助,于是“学习”与“知识”这两种概念在今天已万众瞩目。
◆ ◆ ◆ ◆
中国计算机学会《学科前沿讲习班》第92期
自然语言理解:新学习方法及知识
2018年8月26~28日,呼和浩特, 内蒙古大学学术会议中心8号会议室
◆ ◆ ◆ ◆
对自然语言的理解是很多自然语言处理应用的必要组成部分,包括但不限于翻译,摘要,对话以及问答。在人工智能的时代,基于知识的学习对自然语言理解有极大的帮助,于是“学习”与“知识”这两种概念在今天已万众瞩目。中国计算机学会学科前沿讲习班第92期(CCF ADL 92)“自然语言理解与新‘学习’,新‘知识’”将邀请六位来自业界与学界的著名专家学者,进行为期三天的关于基本理论、算法及相关应用的讲座。这些讲座意在为学生和青年学者提供一个学习与交流平台,帮助他们理解基本的概念、研究内容与方法以及在这个领域不断增长的潮流。ADL 92将和NLPCC 2018联合举办,是NLPCC 2018 Tutorials课程。
CCF Advanced Disciplines Lectures (ADL 92) & NLPCC 2018 Tutorials
Natural Language Understanding with Novel Learning and Knowledge
Hohhot, August 26~28, 2018
Natural language understanding is an essential component for various NLP applications, including but not limited to translation, summarization, conversation and question-answering. In the artificial intelligence era, learning with knowledge significantly improves natural language understanding while the concepts of “learning” and “knowledge” are now in the spotlight. The CCF Advanced Disciplines Lectures No. 92 (CCF ADL 92) “Natural Language Understanding with Novel Learning and Knowledge” will invite six experts and professors with high reputation from both academia and industry to give lectures on the fundamental theories, algorithms, and applications on related issues. The objective of the lectures is to provide a three-day learning and communication platform for the young scholars and research students to understand the element concepts, research contents, approaches and growing tendencies in this area. ADL 92 runs in parallel with NLPCC 2018 as its tutorials.
联系方式:邮箱:nlpcc@pku.edu.cn;电话:010-82529251
学术主任:陈文亮,严睿
陈文亮

陈文亮,苏州大学计算机科学与技术学院教授、博士生导师。2013年1月回国加入苏州大学计算机科学与技术学院。2005年-2010年在日本国立情报通信研究所担任专家研究员。2011年-2012年在新加坡国立信息通讯研究院担任研究科学家。近年来在国内外主要期刊杂志和学术会议上发表三十多篇学术论文,包括AI/NLP领域国际主要学术会议如ACL、AAAI、IJCAI、EMNLP、COLING等,国际顶级杂志如ACM/IEEE 杂志、Artificial Intelligence Journal等。曾在国际主要学术会议IJCNLP-2013和COLING-2014上作讲习报告(Tutorial)。出版英文专著一本,获得美国专利一项。曾担任IALP-2015、IJCNLP-2017、CCKS-2017程序委员会主席或领域主席,多次担任AI/NLP领域顶级会议如IJCAI、AAAI、ACL等程序委员会委员。在研主持江苏省高校自然科学研究重大项目一项、国家自然科学基金一项,大型产业项目一项。主要研究领域包含语言分析、推荐系统、信息抽取、知识图谱。目前主要专注于建设基础语言分析平台和构建知识图谱。

严睿

严睿,北京大学计算机科学技术研究所研究员,博士生导师,同时担任北京大数据研究院研究员,华中师范大学与中央财经大学客座教授及校外导师,之前曾担任百度公司资深研发。共发表论文60余篇,包括NLP/AI/IR/DM多个研究领域的顶级学术会议论文如ACL, AAAI, IJCAI, WWW, SIGIR, KDD等,受邀在国际主要会议如EMNLP作讲习报告(Tutorial),担任多个重要学术会议的资深程序委员会成员(KDD, IJCAI, AAAI)和程序委员会成员(ACL, SIGIR, EMNLP等等)。主要研究领域包括对话系统,信息检索,文本挖掘,理解与生成。
日程
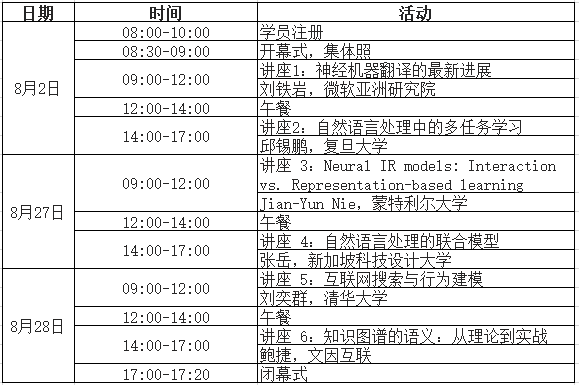
讲座及讲者
微软亚洲研究院
刘铁岩

讲座1:神经机器翻译的最新进展
摘要:神经机器翻译(NMT)近年取得了令人瞩目的成功。本课程中,我将首先介绍 NMT 的基本概念与发展现状,而后指出NMT的学习与推断过程中遇到的一些技术性挑战,并讨论如何用创新性研究解决这些问题。特别地,我将谈谈双重学习,一种可以利用机器翻译的对称结构有效地从单语言数据中学习的新的学习范式。而后我将介绍一些其它的技术,包括一种基于 MCTS 的解码方法,它可以避免标准光束搜索导致的短视推断;一种新的网络结构——熟思网络 (deliberation nets),它通过在解码过程中使用多轮精炼而取得更好的翻译结果。在这些新技术的帮助下,我们已经在中译英的新闻翻译中达到人类水准。最后,我将指出NMT方面的一些其它重要研究方向。
讲者简介:刘铁岩博士,微软亚洲研究院副院长,领导机器学习和人工智能方向的研究工作。在学术方面,刘博士的先锋性研究促进了机器学习与信息检索之间的融合,被国际学术界公认为“排序学习”领域的代表人物。近年来刘博士在深度学习、分布式学习、博弈学习、对偶学习等方面也颇有建树,在顶级国际会议和期刊上发表论文200余篇,被引用近17000次。他的研究工作多次获得最佳论文奖、最高引用论文奖、Springer十大畅销华人作者、Elsevier 最高引中国学者等。他受邀担任了包括SIGIR、WWW、KDD、ICML、NIPS、AAAI、ACL在内的诸多顶级国际会议的程序委员会主席或领域主席;包括ACM TOIS、ACM TWEB、Neurocomputing在内的知名国际期刊副主编。他被聘为卡内基-梅隆大学(CMU)客座教授、诺丁汉大学荣誉教授、中国科技大学教授、博士生导师;他被评为IEEE会士, ACM杰出会员,担任了CCF青工委副主任,中文信息学会(CIPS)信息检索专委会副主任,中国云体系创新战略联盟常务理事,中国工业与应用数学学会大数据与人工智能专委会委员,上海国际金融与经济研究院首届理事。在产业方面,刘博士发明的机器学习技术被广泛应用在十几种微软产品中,贡献了上百项技术专利,大大提升了微软在搜索引擎、云计算、人工智能领域的全球竞争力。他的团队发布了LightLDA、LightGBM、Multiverso等知名的机器学习开源项目,并且为微软CNTK项目提供了分布式训练的解决方案,他的团队所参与的开源项目在Github上已累计2万余颗星。近年来他的团队与中国本土龙头企业进行深入战略合作(例如华夏基金、东方海运、中国太平等),成功助力传统企业实现数字化、智能化转型。
复旦大学
邱锡鹏

讲座2:自然语言处理中的多任务学习
摘要:过去几年,深度学习在自然语言处理中取得了很大的进展,但进展的幅度并不像其在计算机视觉中那么显著。其中一个重要的原因是数据规模问题。因为自然语言处理任务的标注成本一般都比较高,所以语料规模一般都不是很大,这就限制了一些深度模型在自然语言处理中的应用。然而,自然语言处理的一个特点是不同任务之间都有一定的相关性,比如词性分析和句法分析两个任务可以促进。这样在自然语言处理中,一种可以有效解决数据稀缺问题的方法是多任务学习。多任务学习是将多个任务一起学习,充分挖掘多个任务之间的相关性,来提高每个任务的模型准确率,从而可以减少每个任务对训练数据量的需求。目前,多任务学习已经在大部分自然语言处理任务上取得了非常好的效果。本报告主要讲述在自然语言处理中的多任务学习方法,主要包括不同的共享模式(硬共享、软共享和并行共享)和具体的多任务学习模型,以及如何从多领域、多层次、多语言、多模态等角度来设计多任务的学习方式。
讲者简介:邱锡鹏,复旦大学计算机科学技术学院副教授,博士生导师,于复旦大学获得理学学士和博士学位。中国中文信息学会青年工作委员会执委、计算语言学专委会委员、中国人工智能学会青年工作委员会常务委员、自然语言理解专委会委员。主要研究领域包括人工智能、机器学习、深度学习、自然语言处理等,并且在上述领域的顶级期刊、会议(ACL/EMNLP/IJCAI/AAAI等)上发表过50余篇论文。自然语言处理开源工具FudanNLP作者,2015年入选首届中国科协青年人才托举工程,2017年ACL杰出论文奖。
蒙特利尔大学
聂建云
(Jian-Yun Nie)

讲座3:Neural IR models: Interaction vs. Representation-based learning
摘要:深度学习技术在图像处理与语音处理取得的巨大成功激起了人们对神经信息检索的极大兴趣。目前主要有两大类信息检索模型:基于表示的模型和基于交互的模型。前者致力于为文档和查询建立适当的表示,而后者尝试学习他们之间的匹配模式。试验结果表明,交互模型较表示模型而言更具优势。在本课程中,我们将回顾两类模型中的主要方法,分析它们的成功与失败,并讨论神经信息检索的未来研究方向。
讲者简介:聂建云(Jian-Yun Nie)是蒙特利尔大学的教授,他在信息检索和自然语言处理领域工作了三十余年。他的研究在信息检索领域涉及广泛,包括信息检索模型,跨语言信息检索,查询扩展和理解,查询日志的利用等等。聂建云在信息检索与自然语言处理领域发表了许多论文。他是6个国际期刊的编委,并长期担任信息检索与自然语言处理领域主要会议的程序委员。他曾担任SIGIR 2011的会议主席,并即将担任 SIGIR 2019 的程序委员会主席。
新加坡科技设计大学
张岳

讲座4:自然语言处理的联合模型
摘要:联合模型可以同步解决多种问题,已被广泛应用在自然语言处理中,包括联合分词与词性标注,联合名称实体识别与情感分类,联合句法和语义分析等等。与分离模型相比,联合模型具有两大优势。其一,联合模型允许多任务间的交互,从而通过分享信息取得更高准确率。其二,与传统的流水作业方法相比,联合模型减少了任务间的错误传播。联合模型包括基于图的方法,基于转换的方法,统计方法,神经方法,联合训练分离解码的方法,联合解码分离训练的方法,以及联合训练联合解码的方法。这次讲座将介绍现有的联合模型,并将它们总结为以上几类。我们也将讨论对抗训练,一种在联合模型中被用于消除域的差异的技术。
讲者简介:张岳目前在新加坡科技设计大学担任助理教授。在2012年7月加入新加坡科技设计大学之前,曾在英国剑桥大学担任博士后研究助理。曾获得英国牛津大学的博士和理学硕士学位,以及中国清华大学的工商管理硕士学位。研究方向包括自然语言处理,机器学习以及人工智能,曾集中研究过统计分析,解析,文本综合,机器翻译,情感分析和股票市场分析。曾担任Computational Linguistics,Transacation of Association of Computational Linguistics (常设评审委员会) 和 Journal of Artificial Intelligence Research 等顶级期刊的评论员,IEEE Transaction on Big Data 和 ACM Transactions on Asian and Low-Resource Language Information Processing 的副主编,ACL, COLING, EMNLP, NAACL, EACL, AAAI, IJCAI 等会议的审稿委员,COLING 2014/18, NAACL 2015, EMNLP 2015/17, ACL 2017/18 的领域主席,IALP 2017的程序委员会主席。
清华大学
刘奕群

讲座5:互联网搜索与行为建模
摘要:当用户与网络搜索引擎进行交互时,会以提交查询、重构查询、结果点击、光标移动等形式留下丰富的隐式反馈信息。这些用户行为信号包含了有关用户如何在网络搜索情境下检索的有价值信息,从而对理解人类信息感知过程和搜索引擎系统的性能提升非常重要。在本次讲座中,我将首先讨论用户在桌面端和移动端搜索过程中查询、检索以及点击结果的行为模式。基于这些已发现的用户搜索模式,我们将讨论一些流行的行为模型:从单用户到用户群,从同构到异构的结果环境,从单个查询到多个查询。而后,我们将通过几个例子说明这些模型如何帮助搜索引擎优化结果排列,用户意图理解和用户界面/评估指标的设计。
讲者简介:刘奕群,清华大学计算机系长聘副教授,兼任中国人工智能学会理事,中国中文信息学会理事、信息检索与内容安全专委会副主任等职务。主要研究兴趣集中在信息检索与互联网搜索技术。受邀担任国际著名学术期刊FnTIR联合主编,国际高水平学术会议SIGIR 2017短文主席、SIGIR2018程序委员会主席、NTCIR-13程序委员会主席等重要学术职务。获得2015年北京市科学技术一等奖、2010年钱伟长中文信息处理科学技术奖—汉王青年创新一等奖。2016年获得国家自然基金委优秀青年科学基金资助。2017年获得自然科学基金重点基金资助。
文因互联
鲍捷

讲座6:知识图谱的语义:从理论到实战
摘要:知识图谱技术部分地源于过去二十年来发展起来的语义网技术,但是其“语义”部分在实践中往往被忽略了,表现为实践中的知识图谱往往仅被作为数据来查询,而没有有效利用知识推理。深层次的原因,在于经典的图谱语义的定义在现实工程中,存在成本高昂、难以处理现实“脏数据”等问题。本教程总结了在工程中运用语义的一些基本方法。分为三部分:1)先简单回顾经典语义网的基于模型论的语义定义,包括RDF和OWL的基础语义;2)分析了经典语义在落地中遇到的种种困难;3)总结了一些语义落地的最佳实践,如推理闭包、词向量方法、用查询替代推理、规则的可维护性、混合推理等。
讲者简介:鲍捷博士,文因互联CEO,联合创始人。研究领域涉及人工智能多个方向,如自然语言处理、语义网、机器学习、描述逻辑、语义维基、上下文建模、语义信息论、规则语言、封闭世界推理、策略建模、语义数据集成、模块化本体、协作本体构建、网络隐私保护、神经网络、数据挖掘和图像识别等。在 International Joint Conferences on Artificial Intelligence (IJCAI)、International Semantic Web Conference (ISWC)、Extended/European Semantic Web Conference (ESWC), 和 Asian Semantic Web Conference (ASWC) 等期刊和会议上发表 70 多篇论文。曾任 W3C OWL(Web本体语言)工作组成员,在此期间,合作撰写了OWL2 的 W3C 规范文档。先后参与组织 50 多场国际学术会议和学术研讨会,并任中国中文信息学会语言与知识计算专业委员会委员、W3C顾问委员会委员、中国计算机协会会刊编委,中文开放知识图谱联盟(OpenKG)发起人之一。
地点和注册方式
现场注册和报到地点:内蒙古自治区,呼和浩特市,内蒙古大学学术会议中心
会议地点:内蒙古自治区,呼和浩特市,内蒙古大学学术会议中心8号会议室
即日起至2018年8月26日,注册请登录:
http://tcci.ccf.org.cn/nlpcc/2018/index.php
或扫描以下二维码:

NLPCC 2018官网二维码

NLPCC 2018/ADL 92注册网站二维码
注册、注册费及缴费说明
1.根据注册先后顺序录取,报满为止;
2.CCF会员在注册网站中注册时,需填写CCF会员号,并在注册网通过认证,否则将按非会员处理;
3.在注册网站中可以在线缴纳注册费,无法在线缴纳注册费的,可通过银行转账缴纳注册费(具体见7);
4.注册费包括讲课资料、视频资料和3天会议期间午餐,其他食宿、交通自理;
5.缴费后确因个人原因未参加者,扣除报名费30%(开具服务费发票);
6.2018年8月25日(含)前注册并缴费:CCF会员和学生2500元/人,非会员3000元/人;2017年8月26日(含)及现场注册缴费:会员、学生、非会员均为4000元/人。与NLPCC 2018同时注册,享受优惠价格(具体见NLPCC 2018会议通知);
7.注册后可以通过银行转账方式缴纳注册费,账户信息如下:
开户行:北京银行北京大学支行
户名:中国计算机学会
账号:0109 0519 5001 2010 9702 028
请务必注明:参会者姓名NLPCC2018
中国计算机学会

长按识别二维码关注我们
点击“阅读原文”,报名参会。





