基于线性网络的语音合成说话人自适应

说话人自适应算法利用说话人少量语料来建立说话人自适应语音合成系统,该系统能够合成令人满意的语音。在本文中,我们提出了基于线性网络的语音合成说话人自适应算法。该算法对每个说话人学习特定的线性网络,从而获得属于目标说话人的声学模型。通过该算法,使用200句目标说话人的自适应语料训练的说话人自适应系统能够获得和使用1000句训练的说话人相关系统相近的合成效果。
研究背景
对于一个目标说话人,如果他(她)拥有充足的训练数据,那么我们便可以建立一个说话人相关的声学模型,基于该声学模型的系统称之为说话人相关的语音合成系统。利用该系统,我们能够合成和目标说话人声音很像的语音。但是,大多数时候,目标说话人没有充足的数据,这使得合成出来的语音效果不太理想。利用说话人自适应算法,能够基于比较有限的数据来获得较好的语音合成系统,该类算法节省了大量的录音、转录和检查工作,使得建立新的声音的代价变得很小。
本文中,我们提出了基于线性网络(Linear Network, LN)的语音合成说话人自适应算法。该算法通过在源说话人声学模型的层间插入线性网络,然后利用目标说话人的数据来更新该线性网络和神经网络的输出层,从而能够获得属于目标说话人的声学模型。另外,一种基于低秩分解(low-rank plus diagonal,LRPD)的模型压缩算法被应用于线性网络。实验发现,当数据量较少的时候,通过LRPD来移除一些冗余的参数,从而能够使得系统合成的声音更加稳定。
算法描述
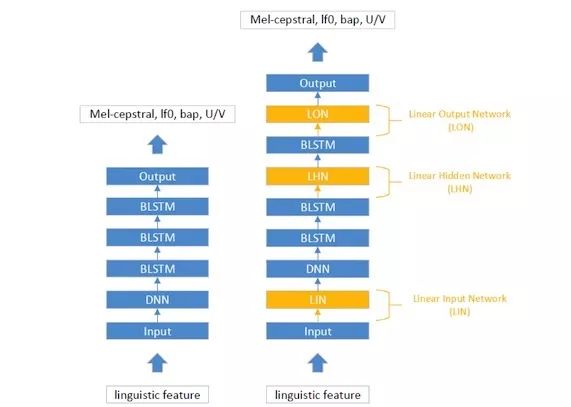
本文中,源说话人声学模型是一个基于多任务(multi-task)DNN-BLSTM的声学模型,见Fig. 1左侧。声学模型的输入为语音学特征,输出为声学特征。声学特征包括梅尔倒谱系数等。实验证明,在声学模型的底层使用深层神经网络(Deep Neural Network,DNN)可以获得更好的底层特征,并且收敛速度上相比于不使用DNN更快。在输出层上,不同的声学特征使用各自的输出层,它们仅共享声学模型的隐层。
基于线性网络的自适应算法首先被提出于语音识别领域,它的系统结构见Fig. 1右侧。根据线性网络插入的位置不同,它可以被分为线性输入网络(Linear Input Network,LIN)、线性隐层网络(Linear Hidden Network,LHN)和线性输出网络(Linear Output Network,LON)。

实验
本文提出的算法,在中文数据集上进行实验,该数据集包含3个说话人,每个说话人有5000句话,时长约5h。数据集中语音的采样率为16k,特征提取中的窗长和窗移分别为25ms和5ms。分别用A-male、B- female和C-female来命名这三个说话人。本实验中,源说话人声学模型训练过程所使用的句子数为5000。为了对比不同句子数目下的合成效果,目标说话人的自适应数据集对应的句子数从50到1000不等。在自适应数据集之外,我们取200句话作为开发集,取20句话作为测试集(用于主观打分)。为了分析性别对自适应效果的影响,进行了三对源说话人-目标说话人之间的实验:女生-女生、男生-女生和女生-男生。另外,使用客观度量和主观测听两种方式来衡量模型的性能。客观度量主要包括:Mel-Cepstral Distortion (MCD)、root mean squared error (RMSE) of F0、unvoiced/voiced (U/V) prediction errors和开发集的MSE。主观测听主要是对系统合成的声音样本进行自然度和相似度上的打分——mean opinion score (MOS) 。
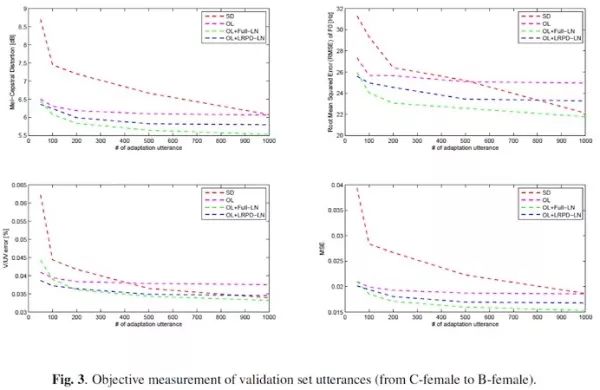
以女生-女生(C-female – B-female)为例,Fig. 3显示了不同自适应句子数目和客观度量之间的关系曲线图。其中,SD表示说话人相关系统,OL表示只更新源说话人声学模型输出层的说话人自适应系统,OL+Full-LN和OL+LRPD-LN分别表示基于Full-LN和LRPD-LN的说话人自适应系统。根据Fig. 3,随着训练/自适应句子数的增加,所有系统间的客观度量趋于相近。对比SD和另外三个自适应系统,自适应系统的性能在相同句子数目下要更优。另外,OL+LRPD-LN和OL+Full-LN相比于OL均出现性能上的跳变(提升),说明只更新输出层而不对其他层进行更新不能够得到较好的自适应效果。同时,当自适应句子数较少的时候,OL+Full-LN在客观性能上要差于OL+LRPD-LN,这是因为OL+Full-LN引入太多的参数量,出现过拟合问题。反之,在句子数多的时候OL+Full-LN在客观性能上要优于OL+LRPD-LN,此时OL+LRPD-LN由于参数量少,出现欠拟合问题。
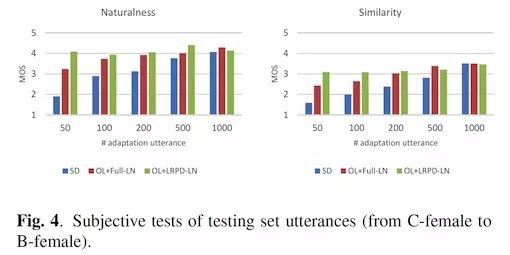
Fig. 4上对比了不同系统间的自然度和相似度。随着句子数的减少,SD系统的性能出现急剧下降,OL+LRPD-LN相比于SD和OL+Full-LN要更加稳定。与客观度量一致,在相同句子数下,OL+Full-LN和OL+LRPD-LN在性能上要优于SD。并且,OL+Full-LN和OL+LRPD-LN在200句话的性能和SD在1000句话时的性能相近。与客观度量不同,OL+LRPD-LN在500句以下的时候性能上就优于OL+Full-LN。这是因为过拟合导致合成出来的声音不稳定(虽然客观度量更优)声音的可懂度下降导致的。由此,我们依然可以得到相同的结论:当自适应句子数较少的时候,过拟合使得OL+Full-LN的性能变差。
结论
本文中,基于线性网络的说话人自适应算法被应用于语音合成领域,基于LRPD的模型压缩算法能够提高声音的稳定性。通过三对不同的源说话人-目标说话人的实验,我们发现,当自适应句子数目非常少的时候,LRPD能够提升声音的稳定性。另外,通过提出的算法,使用200句目标说话人的训练语料训练的说话人自适应系统能够获得和使用1000句训练的说话人相关系统相近的效果。
文章来源:51CTO

媒体合作请联系:
邮箱:contact@dataunion.org



