清华张敏教授:个性化推荐研究进展(可解释性、鲁棒性和公平性)

[导 语]本文是清华大学张敏副教授在Byte Tech 2019 机器智能前沿论坛上的分享实录。Byte Tech 2019由中国人工智能学会、字节跳动、清华大学联合主办,清华大学数据科学研究院协办。
大家好,今天和大家分享一下个性化推荐研究进展。主要探讨三个关键词:可解释性、鲁棒性和公平性。我们大概2013年左右就开始做可解释的推荐,此后也开始逐渐研究鲁棒性和公平性。为什么这三个词很重要呢?

图说:可解释性、鲁棒性和公平性是人工智能目前面对的三个重要挑战。
可能大家对人工智能的发展非常耳熟能详。的确,在这次人工智能热潮开始之后,人们认为人工智能越来越强大。但对很多从事人工智能研究的学者来说,现在更多想的是人工智能在哪些地方遇到了最大的瓶颈。目前大家基本达成了共识:当前人工智能领域的两个核心的挑战是可解释性和鲁棒性。
除了可解释性和鲁棒性之外,从两三年前开始,国外的研究越来越关注第三个问题:公平性。我们在研究过程中发现,可解释性、鲁棒性和公平性这三点并不是完全割裂的。所以今天的报告既会分别讨论这三点,但也试图呈现它们之间的关联。因为这三个话题很大,所以我们用一个具体的领域来讨论,也就是我们课题组这些年一直在研究的个性化推荐。
首先是可解释性。什么叫可解释性?其实很简单。我们除了知道怎么做一件事,怎么完成一个任务之外,还想知道“为什么”。这个“为什么”其实有两个不同角度。首先从用户的角度来说,我们不仅希望给用户看到推荐的结果,例如在线购物网站呈现的推荐商品,还能告诉用户为什么推荐这个商品。另一个例子是新闻推荐。为什么系统从今天的几百条新闻中给用户推了这些内容。我们需要理由,并且要把这个理由解释给用户。这就是结果的可解释性。第二个方面是系统角度的可解释性,也就是系统开发人员需要的解释。在我们实验室的研究过程中,有时候学生对我说这个结果很好或很不好,他们可能很怕我问一个问题:为什么结果会这样?为什么我们方法的效果比别人的好?如果不好,问题出在哪里?特别的,到底是哪些因素/特征/数据带来了问题,有没有可能改进?这是关于系统的可解释性。在现在的人工智能(特别是深度学习)研究中,大家对解释性机器学习探讨得比较多。很多人说深度学习的缺点是不知道结果是怎么给出来的,就是指缺少系统的可解释性。
我们现在先讨论一下面向用户的可解释性。之后在讨论鲁棒性问题时会提到系统的可解释性。
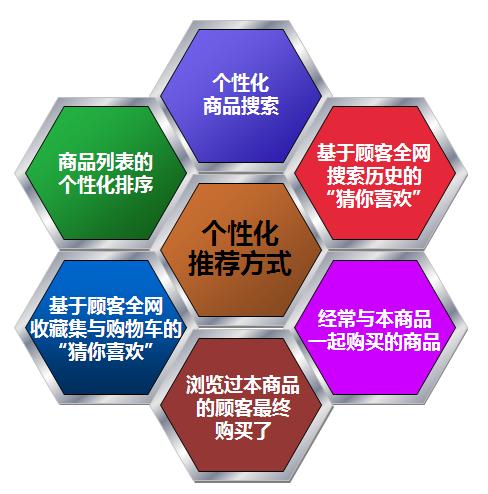
目前推荐系统已经有了非常广泛的应用。大家一定用过推荐系统,无论是新闻阅读信息流还是在线购物等。现在推荐系统给出的理由非常简单,最常见的理由之一是买了某件商品的用户也买了其他什么东西,然后说“你可能也感兴趣…”。事实上,现在推荐系统没有给出更有说服力的推荐理由的原因,并不是不想给,而是给不出来。为什么呢?我们从推荐算法说起。这里我简单介绍一下基本概念,尽量让没有推荐系统背景的朋友也能理解。
推荐系统简明原理
在推荐系统技术中,协同过滤是一个很常用也很有效的办法。在协同过滤技术中,我们经常会看到类似下图所示的矩阵。这个矩阵中记录了某个用户是否买了什么商品,这时系统根据买了同一个商品的人,还买过什么其他商品,来产生推荐的商品候选。但系统并不是直接查矩阵就把结果推出来了。人们会把这个矩阵分解成两部分:一部分是用户,另一部分是商品。这两个部分的隐变量会共享相同的维度,对接用户和商品,把它们映射到同一个空间上。这就是常用的隐变量分解机模型。事实上,给你推荐这个商品的真正理由可能是,在你的第三个、第十个、第十二个维度代表的向量上,你的喜好和被推荐商品的这三个维度代表的向量非常匹配。但如果系统告诉用户说,“我把这个商品推荐给你,是因为你在第十二维上的特征和商品的第十二维很匹配”,用户可能会觉得莫名其妙。
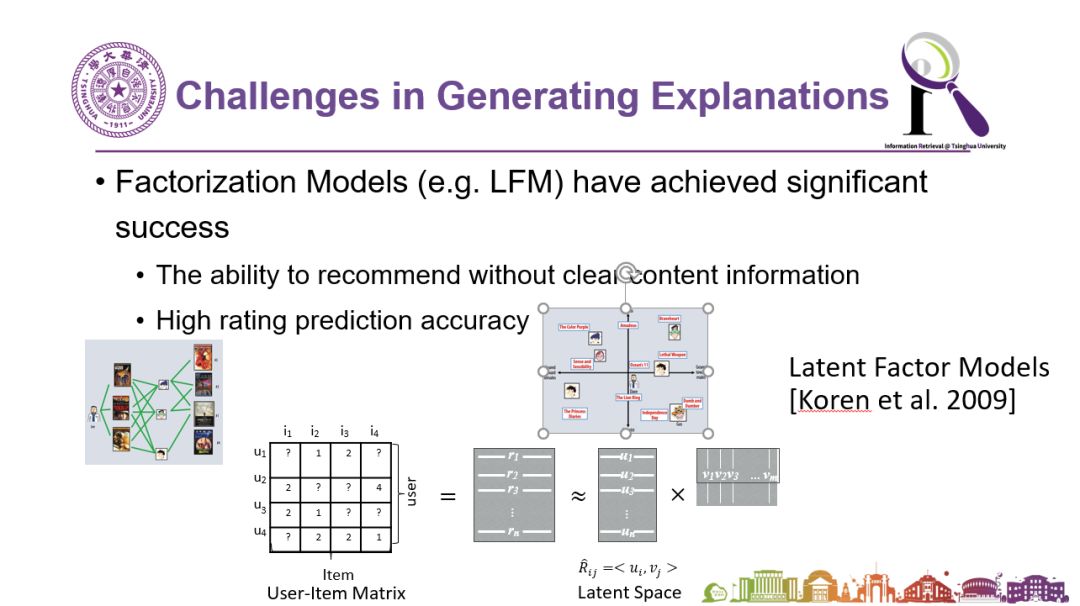
图说:分解机模型可以用来协助基于协同过滤方法的推荐系统的实现。
所以我们想知道,到底有没有一种方法,既可以给出精准的推荐,同时还能给出可靠的解释。于是人们开始在这个方向做一些尝试。我们在2014年左右提出了Explainable Recommendation这个概念(如下图)。后来也有不少人在这个方向做了相关研究,我们提出的EFM模型也成为了大家做可解释推荐时经常用来比较的baseline方法。当时的思路就是,虽然中间的隐变量是不可解释的,但如果找到中间桥梁——这个桥梁就是具体的特征,比如商品的特性——那么推荐的结果就能被解释。例如,系统在推荐一个手机的时候,会解释说这款手机拍照性能好,外观漂亮。这样可能会比较适合一个时尚的女孩。如果系统发现其他用户感兴趣的是另外的特征,就能找到别的合适的手机来推荐,例如把一款屏幕大、字体大、操作简单、待机时间长的手机推荐给你,而你正在给父母买一款智能老人机,你就很可能会被说服。我们用了这种方法后,可以把用户点击率从3%到4%,这是非常大的提升。
人们可能会问:“也许我们不需要理由呢?”所以我们用在线购物网站真实的数据做了实验来分析这样的解释到底有没有效果。第一组实验直接给推荐结果,没有解释;第二组给同样的推荐结果,只是同时给出了“看过这个商品的这个用户还看了什么”的简单解释,这样就可以把点击率从3.20%到3.22%;第三,我们给了新的解释,提供了例如屏幕较大,待机时间较长这样更具体的信息,发现点击率又进一步提升到4.34%。所以真实的用户实验告诉我们,只要给出了合理的解释,推荐精准度会有非常大的提升 —— 有时候人做事情需要别人给我们一个理由。

图说:可解释的推荐算法EFM的原理解释
但是,上述方法也有问题。首先,并不是所有东西都很容易找出特征。比如对新闻来说,我们很难描述这个新闻带有什么样的属性,让我们可以做类似的处理。此外,因为人的语言表达很自由,所以自然语言处理表达有非常大的多样性。比如说有人可能在评论中说“这个东西也没有明显的缺点,但是感觉不太好用”。这种情况很难快速找出完整、精准的特征描述。所以我们认为也许可以尝试把粒度提升一点,不在那么细的粒度上做特征级别的可解释性。于是这就给了我们更多的思路。下图是亚马逊购上的评论。大家可能会发现其实除了用户对商品的评论和打分之外,其他用户还会对某个用户的评论打分:分数代表了其他用户觉得这个评论到底有没有用。如果我们对所有商品都找到这样的有用的评论信息,当用户浏览购买的时候,我们可以把最有用的评论呈现给用户,那么推荐系统影响的不单是购买的结果,还会帮助用户挑选商品时的早期和中间的选择决策过程。
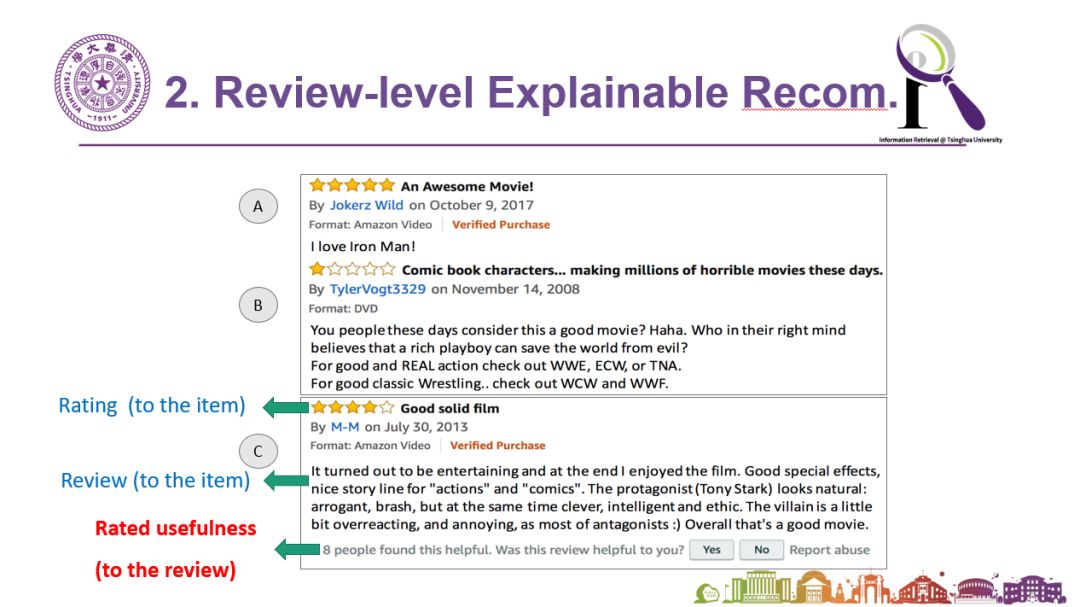
因此,我们从这个角度做了一些工作。我们首先研究是否可以自动发现评论的有用性。因为互联网上有一个重要的原则叫“lazy user”,也就是不要指望用户主动做太多事情。所以愿意给出别人的评论是否有用的用户非常少,数据就很稀疏。那么我们系统能不能自己学习出来呢?其次我们在研究有用性的过程中有没有可能把它与最终的推荐算法结合在一起?而不是仅仅判断某些评论是否有用却没有让推荐系统利用到这一点。
所以我们设计了下图中的模型,这是一个基于注意力机制网络(Attention network)的深度学习模型。我们在这个模型中,试图在最终给出评论推荐的同时,通过中间注意力的机制的选择,挑出更有用更可靠的评论。这个工作我们发表在2018年的WWW会议上。模型的效果非常好,与经典的推荐算法以及基于深度学习的算法等state of art方法相比,我们的模型都会有统计意义上显著的提升。此外,模型是否考虑Attention,效果会有非常大的差异和变化。如下图所示。
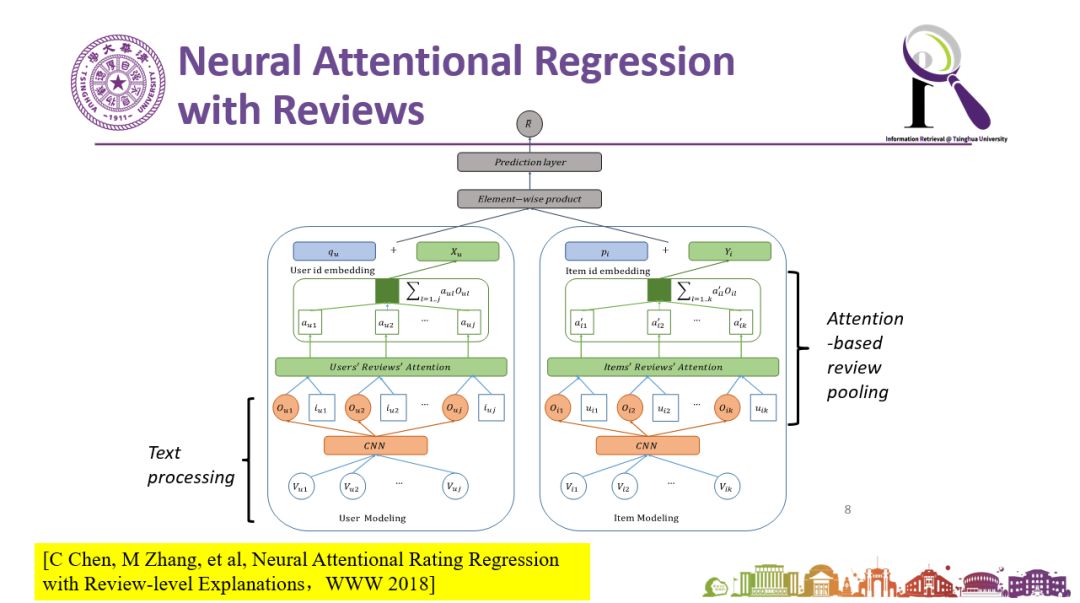
图说:基于Neural Attention Network来给出评论级别的可解释的推荐算法。
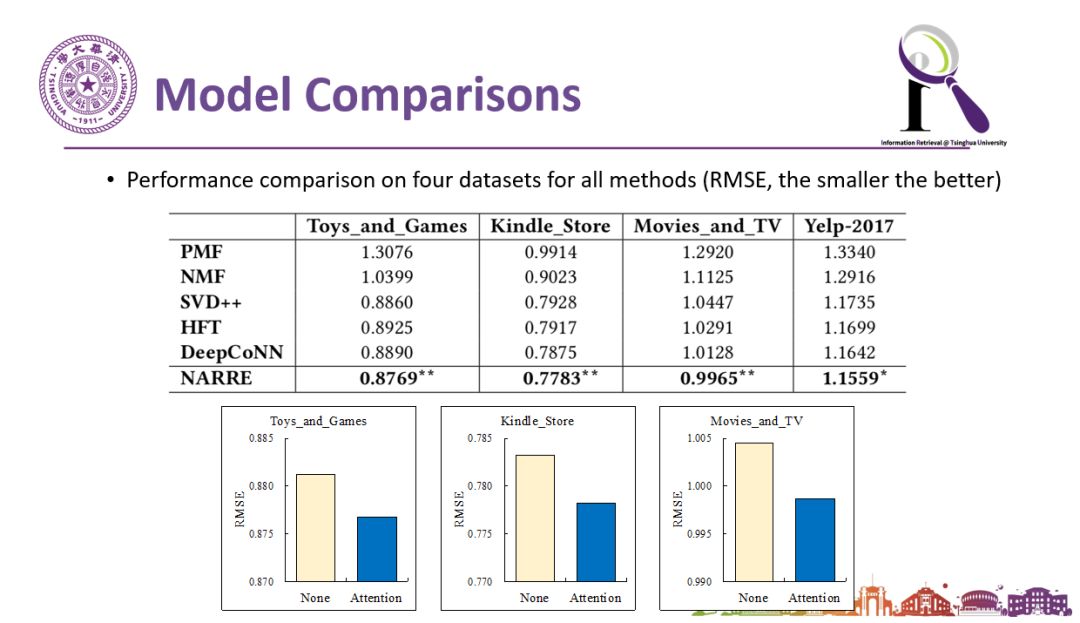
图说:加入了基于attention 机制的可解释推荐方法,模型的性能得到显著提升。
怎么看这个模型对用户是否有效?我们对比了几种常见的方式。比如现在大多数购物网站主要有以下几种方式对评论排序:
时间排序,最近的评论在前面;
随机排序;
排除垃圾评论后按照内容长度排序(因为一般认为越长的评论越有用)。
然而,基于时间和长度的排序往往效果比随机还要差,而我们提出的方法表现更好。这里有一点值得注意的是,事实上,我们这个拿来做标准答案的大规模用户标注的有效性数据,是有偏的(bias)。因为曾经被人评过有用的东西,会因为马太效应,更容易被其他人认为有用。而那些事实上有用,但却没有机会立刻呈现的评论会永远沉寂下去。而这个bias也是我们所说的“不公平性”的情况之一。所以我们做了第三方更客观的评价,发现这种bias的确存在,而通过算法分析找到的方法,比靠用户在系统中的投票,是更可靠更有效的方法。
在可解释性方面还有更多要讨论的问题,比如应该用产生式的方法还是判别式的方法,我们的观点是都可以。还有怎么评价这个解释的有效性呢?我们觉得一个可行的思路是要和用户的行为结合在一起。另外,推荐算法可能带来的偏差怎么处理?尤其是解释本身是否带来不公平性?这也是非常容易存在的一个问题,有可能变成哲学问题。
鲁棒性问题
第二个要讨论的问题,是鲁棒性。这个问题涉及到很多方面。在个性化推荐领域,鲁棒性问题的具体表现之一是很严重的数据缺失的挑战。我们都知道可以根据用户的历史做推荐,但如果一个新用户什么历史都没有,你要怎么做推荐呢?这称作冷启动(cold-start)问题。
在推荐系统中有一类方法基于协同过滤,还有一类方法是基于内容匹配,前者虽然一般来说效果更好但是无法处理冷启动情况,而后者即使冷启动时还能够工作。我们可以把他们融合起来,用历史数据学到给这两种方法分配的权值:例如0.8和0.2。冷启动的时候,协同过滤那部分是0,但还至少有0.2权重的基于内容(content-based)的方法能够使用。但很显然对不同用户、不同的商品,这种融合的权值应该是不一样的。所以我们提出一个思路(如下图):我们不要固定选好一个对所有人一样的权值,而是提出一个统一的框架(unified framework),自动用注意力网络学习出在不同的情况下不一样的权值。如果大家感兴趣的话,可以看一下我们发表在CIKM 2018上的论文:Attention-based Adaptive Model to Unify Warm and Cold Starts Recommendation。效果确实非常好,能非常有效地解决冷启动问题,并且对总体效果非常有帮助。
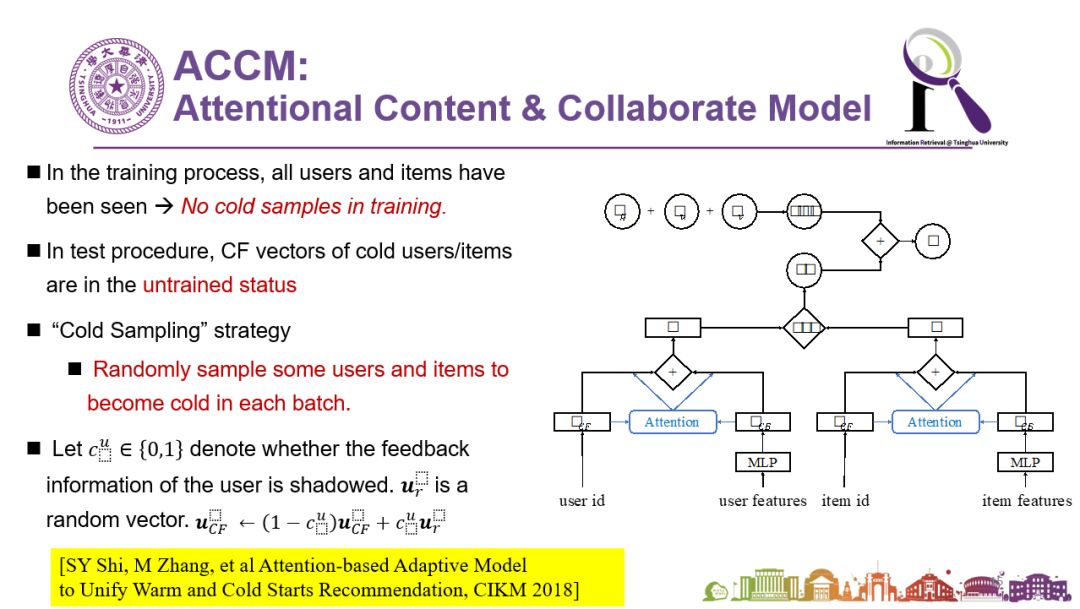
图说:统一的框架可以解决冷启动推荐问题。
更有趣的是,当学生把下图拿给我的时候,我觉得这可以算是个很漂亮的工作了,因为这项工作同时也体现了系统的可解释性。为什么刚才提到的模型结果很好呢?这是因为通过学习到的不同Attention,会发现左上角是新的item(例如新商品或新的消息),右下角是新的用户。对于信息充足的情况和信息严重不足的情况(新的商品+新的用户),这幅图都给了解释。所以你会发现,当我们解决鲁棒性的同时,对于系统级别的可解释性也有非常大的改善。
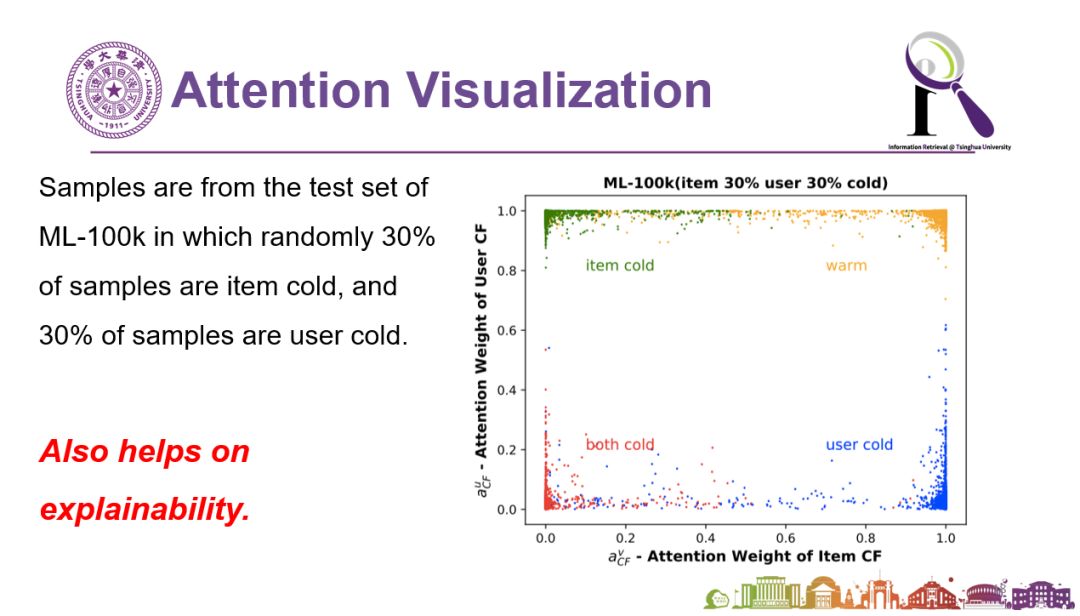
图说:提升推荐系统的鲁棒性同时也可能提升系统的可解释性。
公平性问题
最后我们用很短的时间再探讨一下公平性问题。公平性问题很值得注意。比如2018年的一个研究发现,在两个公开数据集MovieLens和LastFM上,对男性的推荐效果比对女性推荐效果好,对老人和18岁以下年轻人的推荐效果,比18岁到50岁之间的人群的推荐效果更好,这不是系统有意识地产生偏见,可能和数据量以及用户习惯有关,但是不公平性的确存在。另一方面对被推荐物及相关信息也存在不公平性,例如我们前面讨论过的对评论的不公平性,以及更多推荐流行的东西,也会带来对不热门的东西的不公平性。有时候对用户和对物品的公平性,是有冲突的。例如我们希望增加推荐的多样性,但是有研究表明,增加多样性的时候提升了对被推荐物的公平性,但是却降低了对用户的公平性。

图说:推荐系统对不同人群的效果不同,降低了对用户和对推荐物的公平性。
最后一分钟时间分享一下我们在用户行为的不公平性上发现的有趣现象。人们常在看新闻的信息流时经常说这个文章质量太差了,怎么给我推荐这些呢?事实上我们来看看点击率,会吃惊地发现:低质量的新闻总体点击率(下面左图中的蓝线)始终比高质量新闻点击率(图中的红线)高,甚至我们会发现有一些用户在点击之前其实是知道这条新闻的质量肯定不怎么样的,但人们还是有猎奇心理,“我知道它不太好可我就是要点”,点完以后发现这条新闻质量果然是不怎么样。但反过来,对推荐系统来说就感到很奇怪了——用户们你们明明喜欢点的呀,怎么还觉得不好呢。所以这种大量存在的点击的偏置也是不公平的,是对高质量新闻的不公平。
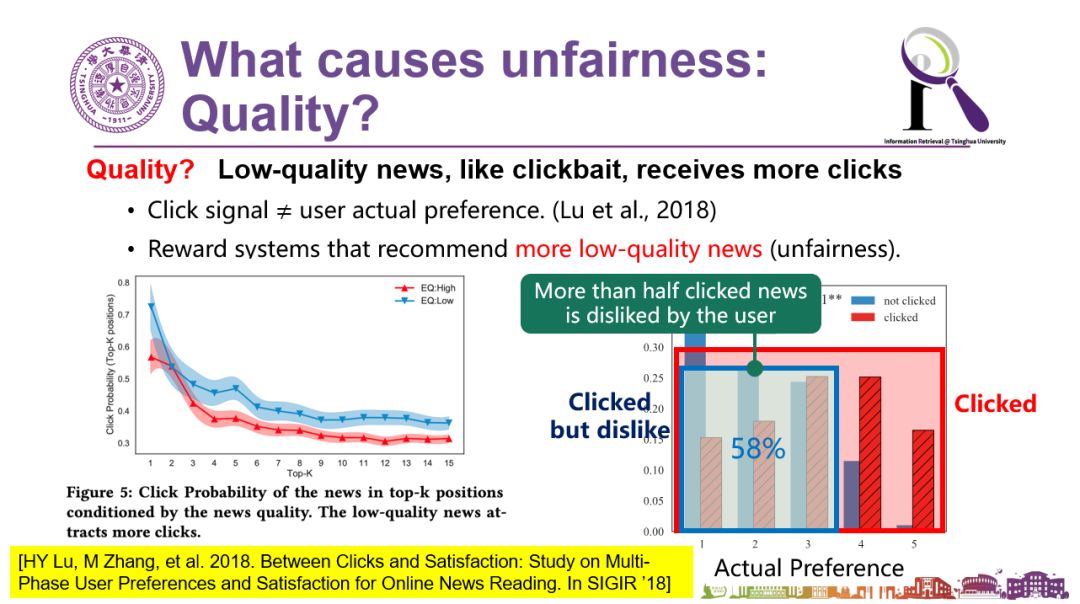
图说:低质量新闻的点击率始终比高质量新闻的点击率高。
怎么解决呢?从算法思路可以一定程度上来解决。我们的思路是不要光看点击,不能只拿点击率来做评价指标,而要看用户的满意度。这个满意度虽然没有被用户显式地给出来,但是可以从用户的行为找到蛛丝马迹来进行自动分析。相关的工作我们发表到了2018年的SIGIR上(文章和主要方法可见下图)。
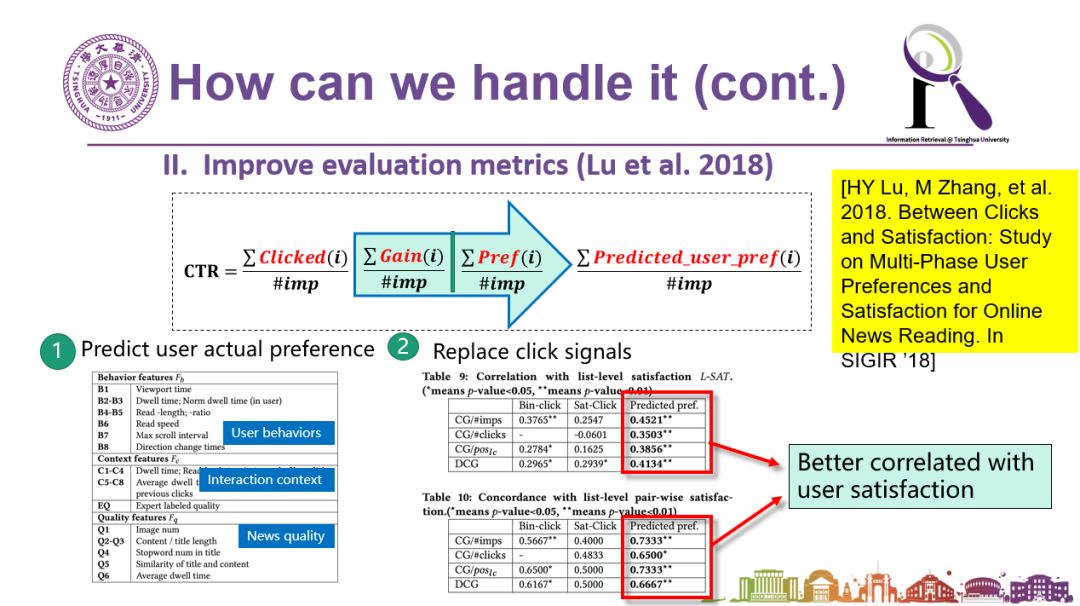
图说:低质量新闻的点击率始终比高质量新闻的点击率高。
以上是我今天跟大家简短分享的内容,主要是希望大家关注到可解释性、鲁棒性、公平性这三个非常重要的因素,而且这三个因素并非独立存在,而是在相互作用的。如果我们希望有一个更好的人工智能系统,一定要在这三个方面做进一步的工作。真正智能化的人工智能技术依然前路漫漫,还有非常多的挑战和非常多的机会等待我们去发现和面对。
编辑:文婧
校对:洪舒越