作画、写诗、弹曲子,AI还能这么玩?
| 全文共4780字,建议阅读时9分钟 |
选自:The Gradient
作者:Shreya Shankar
参与:Geek AI、王淑婷
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
随着深度学习的发展,算法研究已经进入一个新的领域:人工智能生成艺术作品。除了研究机器人、语言识别、图像识别、NLP 等等这些,AI 还能作画、写诗、弹曲子。惊不惊喜,意不意外?
随着深度学习取得的成功,算法研究已经进入了另一个人类认为不受自动化技术影响的领域:创造引人入胜的艺术品。
在过去的几年中,利用人工智能生成的艺术作品取得了很大的进步,其结果可以在 RobotArt 和英伟达举办的 DeepArt 大赛中看到:

虽然这些模型的技术成就令人印象深刻,但人工智能和机器学习模型能否真的像人一样具有创造性仍是一个争论的焦点。有些人认为,在图像中建立像素的数学模型或者识别歌曲结构中的顺序依赖性并非什么真正具有创造性的工作。在他们看来,人工智能缺乏人类的感知能力。但我们也不清楚人类大脑正在做什么更令人印象深刻的事情。我们怎么知道一个画家或者音乐家脑海中的艺术火花不是一个通过不断练习训练出来的数学模型呢?就像神经网络这样。
尽管「人工智能的创造力是否是真正的创造能力?」这一问题在短期内还不太可能被解决,但是研究这些模型的工作原理可以在一定程度上对这个问题的内涵作出解释。本文将深入分析几个通过机器生成的顶尖视觉艺术和音乐作品。具体而言,包括风格迁移和音乐建模,以及作者所认为的该领域未来的发展方向。
风格迁移
你对风格迁移可能已经很熟悉了,这可以说是最著名的一种通过人工智能生成的艺术。如下图所示:

这究竟是怎么做到的呢?我们可以认为每张图片由两个部分组成:内容和风格。「内容」就是图片中所展示的客观事物(如左图中斯坦福大学的中心广场),「风格」则是图画的创作方式(如梵高《星月夜》中的螺旋、多彩的风格)。风格迁移是用另一种风格对一幅图像进行二次创作的任务。
假设我们有图像 c 和 s,c 表示我们想要从中获取内容的图像,s 表示我们想要从中获取风格的图像。令 y^ 为最终生成的新图像。直观地说,我们希望 y^ 具有与 c 相同的内容、与 s 相同的风格。从机器学习的角度来看,我们可以将这个任务形式化定义为:最小化 y^ 和 c 之间的内容损失以及 y^ 和 s 之间的风格损失。
但是我们该如何得出这些损失函数呢?也就是说,我们如何从数学上接近内容和风格的概念?Gatys,Ecker 和 Bethge 等人在他们具有里程碑意义的风格迁移论文「A Neural Algorithm of Artistic Style」(https://arxiv.org/abs/1508.06576)中提出,这个问题的答案在于卷积神经网络(CNN)的架构。

假设你通过一个已经被训练过的用于图像分类 CNN 来馈送图像。由于这样的初始化训练,网络中的每一个后继层都被设置来提取比上一层更复杂的图像特征。作者发现图像的内容可以通过网络中某一层的特征映射来表示。然后,它的风格就可以用特征映射通道之间的相关性来表示。这种相关性被存在了一个名为「Gram matrix」的矩阵中。
基于这种数据表征,作者将生成图像的特征映射与内容图像之间的欧氏距离相加,从而构建内容损失。接下来,作者将每个风格层特征映射的 Gram 矩阵之间的欧氏距离相加,从而计算风格损失。在这两个损失中,每一层的重要性都是根据一组参数来加权,可以对这些参数进行调优以获得更好的结果。
形式上,令 y^ 为生成的图像,并令 ϕj(x) 为输入 x 的 第 j 层特征映射。相应的内容损失可以被计算为:
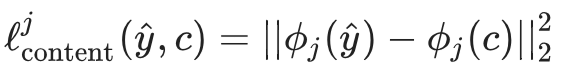
令 Gj(x) 为 ϕj(x) 的 Gtam 矩阵。相应的风格损失可以用以下形式计算,其中 F 表示弗罗贝尼乌斯范数(Frobenius norm):
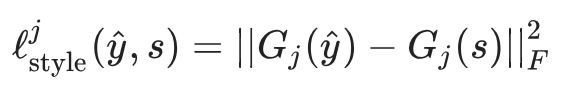
最后,我们用权重αj 和βj 对所有 L 层求和,从而得到总的损失函数:
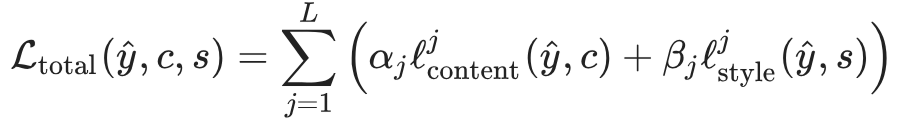
也就是说,这意味着整个网络的损失函数 Ltotal 仅仅是内容损失和风格损失的加权组合。在这里,α_j 和 β_j 除了用来每一层加权,还要控制忠实重建目标内容和重建目标风格之间的权衡。在每一步训练中,作者根据损失函数更新输入的像素,然后反复进行这种更新操作,直到输入图像收敛到目标风格图像。
前馈风格迁移
对于我们想要生成的每张图像来说,解决这个优化问题都需要时间,因为我们需要从随机噪声完美地转化到具有特定风格的内容。事实上,本文的原始算法要花大约两个小时的时间来制作一张图像,这种情况激发了更快处理的需求。幸运的是,Jognson 等人(https://arxiv.org/abs/1603.08155)在 2016 年针对该问题发表了一篇后续论文,该文描述了一种实时进行风格迁移的方法。
Johnson 等人没有通过最小化损失函数从头开始生成图像,而是采取了一种前馈方法,训练一个神经网络直接将一种风格应用到指定的图片上。他们的模型由两部分组成——一个图像转化网络和一个损失网络。图像转化网络将一个常规图像作为输入,并且输出具有特定风格的相同图像。然而,这个新模型也要使用一个预先训练好的损失网络。损失网络将测量特征重构损失,后者是(图片内容的)特征表示和风格重建损失之间的差异,而风格重建损失则是通过 Gram 矩阵计算的图像风格之间的差异。
在训练过程中,Johnson 等人将微软「COCO」数据集(http://cocodataset.org/#home)中的一组随机图像输入到图像转化网络中,并且用不同的风格创作这些图像(比如《星月夜》)。这个网络被训练用于优化来自于损失网络的损失函数组合。通过这种方法生成的图片质量与原始图片质量相当,而且这种方法生成 500 张大小为 256*256 的图片时速度比之前快了令人难以置信的 1060 倍。这个图像风格迁移的过程需要花费 50 毫秒:

在未来,风格迁移可以被拓展到其它媒介上,比如音乐或诗歌。例如,音乐家可以重新构思一首流行歌曲(比如 Ed Sheeran 的「Shape of You」),让它听起来有爵士的风格。或者,人们可以将现代的说唱诗转换成莎士比亚的五步抑扬诗风格。到目前为止,我们在这些领域还没有足够的数据来训练出优秀的模型,但这只是时间问题。
对音乐建模
生成音乐建模是一个难题,但是前人已经在这个领域做了大量工作。
当谷歌的开源人工智能音乐项目「Magenta」刚刚被推出时,它只能生成简单的旋律。然而,到了 2017 年夏天,该项目生成了「Performance RNN」,这是一种基于 LSTM 的循环神经网络(RNN),可以对复调音乐进行建模,包括对节拍和力度进行建模。
一首歌可以被看作一个音符序列,音乐便是一个使用 RNN 建模的理想用例,因为 RNN 正是为学习序列化模式而设计的。我们可以在一组歌曲的数据集合(即一系列代表音符的向量)上训练 RNN,接着从训练好的 RNN 中取样得到一段旋律。可以在「Magenta」的 Github 主页上查看一些演示样例和预训练好的模型。
之前 Magenta 和其他人创作的音乐可以生成可传递的单声道旋律或者时间步的序列,在每一个时间步上,最多一个音符可以处于「开启」状态。这些模型类似于生成文本的语言模型:不同的是,该模型输出的不是代表单个词语的独热向量,而是代表音符的独热向量。
即使使用独热向量也意味着一个可能生成旋律的巨大空间。如果要生成一个由 n 个音符组成的序列——意味着我们在 n 个时间步的每一个时间步上都要生成一个音符——如果我们在每个时间步上有 k 个可以选择的音符,那么我们最终就有 k 的 n 次方个有效向量序列。

这个空间可能相当大,而且到目前为止我们的创作仅仅局限于单声道音乐,它在每个时间步上只播放一个音符。而我们听到的大多数音乐都是复调音乐。复调音乐的一个时间步上包含多个音符。想象一下一个和弦,或者甚至是多种乐器同时演奏。现在,有效序列的数量是巨大的——2^(k^n)。这意味着谷歌的研究人员必须使用一个比用于文本建模的 RNN 更复杂的网络:与单个词语不同,复调音乐中每个时间步上可以有多个音符处于「开启」状态。
还有一个问题,如果你曾经听过电脑播放的音乐——尽管是人类创作的音乐——它仍然可能听上去像机器人创作的。这是因为,当人类演奏音乐时,我们会改变节奏(速度)或者力度(音量),让我们的表演有情感的深度。为了避免这种情况,研究人员不得不教该模型稍稍地改变节奏和力度。「Performance RNN」可以通过改变速度、突出某些音符以及更大声或更柔和地演奏来生成听起来像人类创作的音乐。
如何训练一个能有感情地演奏音乐的模型呢?实际上有一个数据集完美适用于这个目标。雅马哈电钢琴比赛数据集包括现场演出的 MIDI 数据:每首歌被记录为一个音符序列,每一个音符都包含关于演奏速度(弹奏音符的力度)和时间的信息。因此,除了学习要演奏哪些音符,「Performance RNN」还利用人类表演的信息去学习如何演奏这些音符。
最近的这些发展就好比是一个用一根手指弹奏钢琴的六岁孩子与一个富有感情地演奏更复杂乐曲的钢琴演奏家之间的区别。然而,还有很多工作要做:「Performance RNN」生成的一些样本仍然一听起来就是人工智能生成的,因为它们没有固定的音调或者像传统歌曲那样重复主题或旋律。未来的研究可能会探索该模型能够为鼓或者其他乐器做什么。
但是就目前的情况而言,这些模型已经发展到足以帮助人们创造他们自己的音乐的地步。
人工智能生成艺术作品的未来
过去几年中,机器学习和艺术的交叉研究迅速发展。这甚至成为了纽约大学一门课程的主题。深度学习的兴起对这个领域产生了巨大的影响,重新唤起了人们对表示和学习如图片、音乐、文本等大量非结构化数据的希望。
我们现在正在探索机器生成艺术作品的可能性。未来,我们可能会看到机器学习成为艺术家的工具,比如为草图上色、「自动完成」图像、为诗歌或小说生成大纲等。
凭借更强的计算能力,我们可以训练能够在诸如音频、电影或其它形式复杂的媒介上泛化的模型。现在已经有可以根据任何新文本生成相应音频和口型同步的视频的模型。Mor 等人的「musical translation network」能够在乐器和音乐流派之间进行一种声音风格迁移。Luan 等人展示了适用于高分辨率图像的真实风格迁移。这种机器生成的媒体文件的潜在应用价值是巨大的。
我们可以无休止地讨论通过人工智能生成的艺术作品是否真正具有创造性。但或许可以从另一个角度来看待这个问题。通过对人类的创造力进行数学化建模的尝试,我们开始对人类的艺术作品为何如此具有感染力有了更深刻的理解。
原文链接:https://towardsdatascience.com/from-brain-waves-to-arm-movements-with-deep-learning-an-introduction-3c2a8b535ece
【邀请函】质量保障体系建设及本科教学工作审核/合格评估专题研修班
喜欢我们就多一次点赞多一次分享吧~
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~




