将U-Net用于图像去雾任务,一种具有密集特征融合的多尺度增强去雾网络 | CVPR2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI算法修炼营

这是一篇将Unet架构网络用于去雾任务的文章,主要的创新点是在于解码器的增强策略和在特征融合模块引入了用于超分辨率的反投影机制并进行了改进。整体思路简洁明了,代码也完全开源,可以重点学习boosting策略和特征融合的思想。
论文地址:https://arxiv.org/pdf/2004.13388.pdf
代码地址:https://github.com/BookerDeWitt/MSBDN-DFF
在本文中,提出了一种基于U-Net架构的具有密集特征融合的多尺度增强去雾网络。该方法是基于两种原理设计的——boosting 和 error feedback,表明它们适用于去雾问题。通过在所提出的模型的解码器中加入“Strengthen-Operate-Subtract”增强策略,本文开发了一种简单有效的增强解码器来逐步恢复无雾度图像。为了解决在U-Net架构中保留空间信息的问题,本文使用back-projection 反馈方案设计了一个特征密集的融合模块。实验表明,密集特征融合模块可以同时纠正高分辨率特征中缺少的空间信息,并利用不相邻特征。通过大量实验评估表明,所提出的模型在基准数据集以及真实世界的朦胧图像上的性能优于现有方法。
在计算机视觉领域,通常使用雾天图像退化模型来描述雾霾等恶劣天气条件对图像造成的影响,该模型是McCartney首先提出。该模型包括衰减模型和环境光模型两部分。模型表达式为:
其中, 是图像像素的空间坐标, 是观察到的有雾图像, 是待恢复的无雾图像, 表示大气散射系数, 代表景物深度, 是全局大气光,通常情况下假设为全局常量,与空间坐标 无关。
公式(1)中的 表示坐标空间 处的透射率,使用 来表示透射率,于是得到公式(2):
由此可见,图像去雾过程就是根据 求解 的过程。要求解出 ,还需要根据 求解出透射率 和全局大气光 。
实际上,所有基于雾天退化模型的去雾算法就是是根据已知的有雾图像 求解出透射率 和全局大气光 。
与许多高级视觉任务不同,诸如图像去雾问题之类的逆问题是病态严重的,其中小的测量误差通常会导致剧烈的变化。为了解决这些不适的问题,需要某些先验或仔细的算法设计才能使问题更好地解决。因此现有方法通常使用强先验或假设作为附加约束来还原透射图,全局大气光和场景辐射,并且对于去雾的深度网络,仅堆叠更多的层或使用更宽的层就无法有效提高性能。因此,为去雾问题定制设计网络模型具有极大的意义和重要性。
在这项工作中提出了一个去雾网络,该网络应遵循两个完善的图像恢复问题原理,即增强(boosting)和错误反馈(error feedback)机制。增强策略最初是用于图像去噪,主要思想是通过逐步细化先前迭代的中间结果。误差反馈机制(尤其是反投影技术)用于超分辨率,以逐步恢复退化过程中遗漏的细节。
本文首先证明了boosting策略也将促进图像去雾任务。考虑到这两个原理,本文提出了一种基于U-Net架构的具有密集特征融合(DFF)的多尺度增强去雾网络(MS-BDN)。将网络的解码器中引入图像恢复模块,具体的,在解码器中并入了“Strengthen-Operate-Subtract”(SOS)增强策略,以逐步恢复无雾图像。由于U-Net的编码器中存在下采样操作,可能无法从U-Net的解码器有效地检索空间信息。为了解决这个问题,本文还提出了一种基于反投影技术的DFF模块,以有效融合不同层次的特征,并证明了该模块可以同时保留高分辨率特征的空间信息,并利用非相邻特征进行图像去雾。大量实验评估表明,所提出的算法与最新的除雾方法相比具有出色的性能。
主要贡献:1、提出了一种多尺度增强除雾网络,将增强策略和反投影技术巧妙地结合到了图像除雾中。2、证明了该增强策略可以帮助图像除雾算法。并证明了基于反投影技术的密集特征融合模块可以有效地融合和提取不同比例的特征以进行图像去雾,并有助于提高去雾网络的性能。
U-Net如下图所示,是一个encoder-decoder结构,左边一半的encoder包括若干卷积,池化,把图像进行下采样,右边的decoder进行上采样,恢复到原图的形状,给出每个像素的预测。
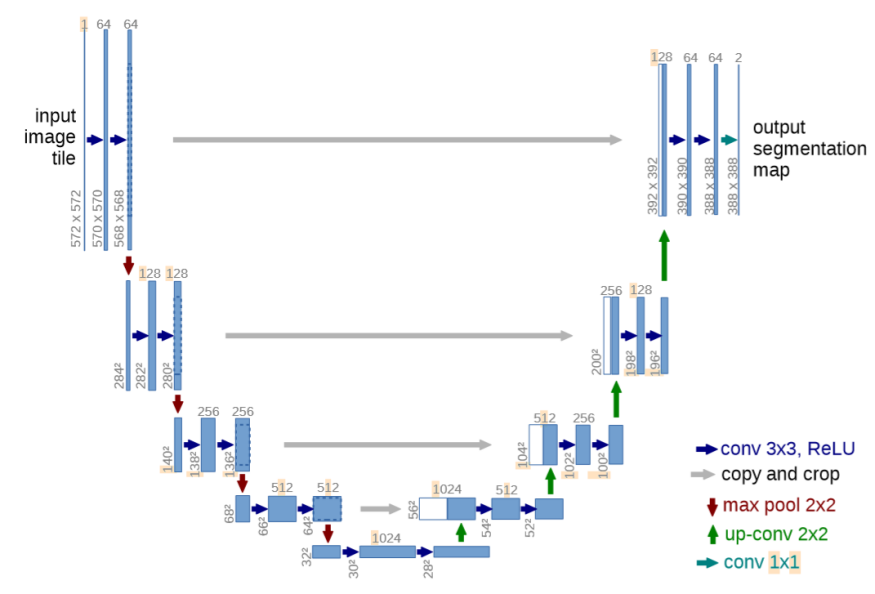
具体来说,左侧可视为一个编码器,右侧可视为一个解码器。编码器有四个子模块,每个子模块包含两个卷积层,每个子模块之后有一个通过max pool实现的下采样层。输入图像的分辨率是572x572, 第1-5个模块的分辨率分别是572x572, 284x284, 140x140, 68x68和32x32。由于卷积使用的是valid模式,故这里后一个子模块的分辨率等于(前一个子模块的分辨率-4)/2。解码器包含四个子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率一致(由于卷积使用的是valid模式,实际输出比输入图像小一些)。该网络还使用了跳跃连接,将上采样结果与编码器中具有相同分辨率的子模块的输出进行连接,作为解码器中下一个子模块的输入。
架构中的一个重要修改部分是在上采样中还有大量的特征通道,这些通道允许网络将上下文信息传播到具有更高分辨率的层。因此,拓展路径或多或少地与收缩路径对称,并产生一个U形结构。
在该网络中没有任何完全连接的层,并且仅使用每个卷积的有效部分,即分割映射仅包含在输入图像中可获得完整上下文的像素。该策略允许通过重叠平铺策略对任意大小的图像进行无缝分割,如图所示。为了预测图像边界区域中的像素,通过镜像输入图像来推断缺失的上下文。这种平铺策略对于将网络应用于大型的图像非常重要,否则分辨率将受到GPU内存的限制。
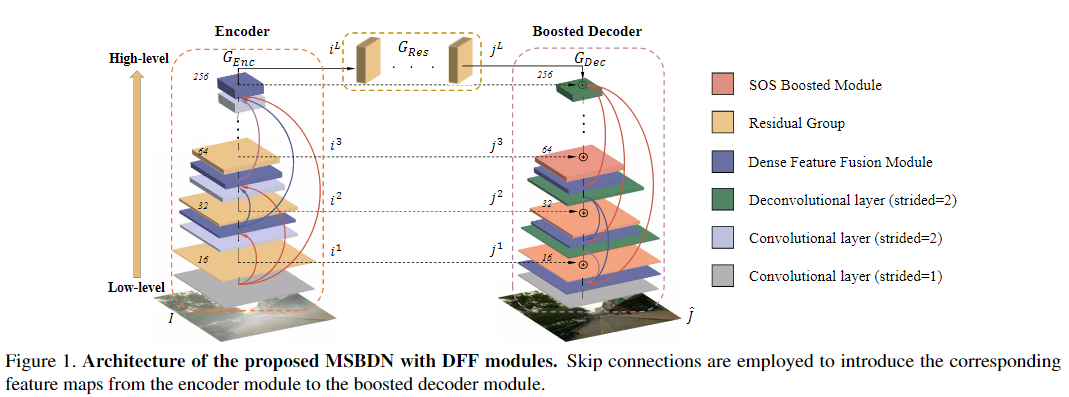
本文所提出的网络基于U-Net 架构,并设计了一种受SOS boosting方法启发的多尺度boosting解码器。从图1看出,整个网络包括三个部分:编码器模块GEnc,增强型解码器模块GDec和特征恢复模块GRes。
1、Boosting in image dehazing
增强算法已被证明对图像去噪有效。SOS(Signal-to-Noise Ratio )增强算法(可参考论文《 Boosting of image denois-ing algorithms》)基于先前估计的图像对增强图像进行细化处理。该算法已被证明可以提高信噪比(SNR),这是基于在相同但噪点较少的场景的图像上SNR方面降噪方法可获得更好的结果。
对于图像去雾,SOS增强策略的计算方式类似于:
2、Deep boosted dehazing network
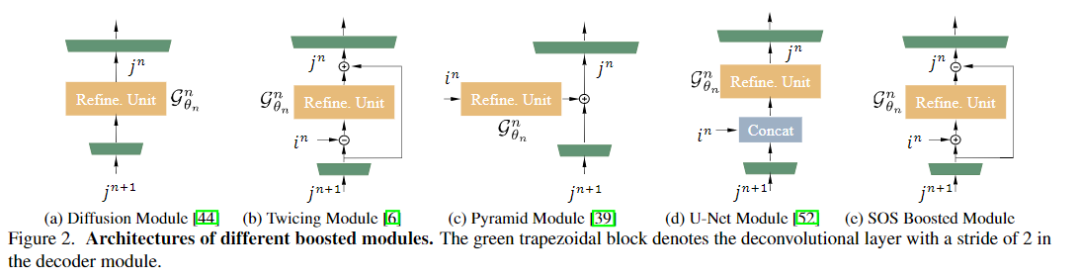
在用于去雾的U-Net网络中,将解码器即为无雾图像恢复模块。为了从特征恢复模块GRes中逐步完善特征,将SOS增强策略引入了所提出的网络的解码器中,图2(e)中说明了SOS增强模块的结构。
公式表示为:
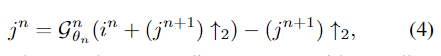
SOS boosted module的替代模块及比较
列出了用于除雾的SOS增强模块的四个替代方案。diffusion 和 twicing方法可用于设计boosting模块,如图2(a)和图2(b)所示。它们可以分别表示为
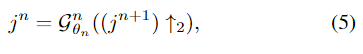
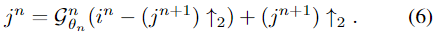
(5)(6)两式表示的方法没有充分利用特征的结构和空间信息。
另一个相关的模块是来自特征金字塔网络(FPN)的金字塔模块(如图2(c)所示)。
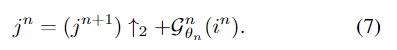
从公式可以看出,FPN看不到前一级的上采样特征。
最后,比较了原始U-Net的解码器模块(如图2(d)所示),该模块将模块中的上采样增强特征和潜在特征连接起来。
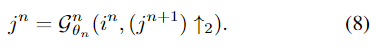
class Decoder_MDCBlock1(torch.nn.Module):
def __init__(self, num_filter, num_ft, kernel_size=4, stride=2, padding=1, bias=True, activation='prelu', norm=None, mode='iter1'):
super(Decoder_MDCBlock1, self).__init__()
self.mode = mode
self.num_ft = num_ft - 1
self.down_convs = nn.ModuleList()
self.up_convs = nn.ModuleList()
for i in range(self.num_ft):
self.down_convs.append(
ConvBlock(num_filter*(2**i), num_filter*(2**(i+1)), kernel_size, stride, padding, bias, activation, norm=None)
)
self.up_convs.append(
DeconvBlock(num_filter*(2**(i+1)), num_filter*(2**i), kernel_size, stride, padding, bias, activation, norm=None)
)
def forward(self, ft_h, ft_l_list):
if self.mode == 'iter1' or self.mode == 'conv':
ft_h_list = []
for i in range(len(ft_l_list)):
ft_h_list.append(ft_h)
ft_h = self.down_convs[self.num_ft- len(ft_l_list) + i](ft_h)
ft_fusion = ft_h
for i in range(len(ft_l_list)):
ft_fusion = self.up_convs[self.num_ft-i-1](ft_fusion - ft_l_list[i]) + ft_h_list[len(ft_l_list)-i-1]
if self.mode == 'iter2':
ft_fusion = ft_h
for i in range(len(ft_l_list)):
ft = ft_fusion
for j in range(self.num_ft - i):
ft = self.down_convs[j](ft)
ft = ft - ft_l_list[i]
for j in range(self.num_ft - i):
ft = self.up_convs[self.num_ft - i - j - 1](ft)
ft_fusion = ft_fusion + ft
if self.mode == 'iter3':
ft_fusion = ft_h
for i in range(len(ft_l_list)):
ft = ft_fusion
for j in range(i+1):
ft = self.down_convs[j](ft)
ft = ft - ft_l_list[len(ft_l_list) - i - 1]
for j in range(i+1):
# print(j)
ft = self.up_convs[i + 1 - j - 1](ft)
ft_fusion = ft_fusion + ft
if self.mode == 'iter4':
ft_fusion = ft_h
for i in range(len(ft_l_list)):
ft = ft_h
for j in range(self.num_ft - i):
ft = self.down_convs[j](ft)
ft = ft - ft_l_list[i]
for j in range(self.num_ft - i):
ft = self.up_convs[self.num_ft - i - j - 1](ft)
ft_fusion = ft_fusion + ft
return ft_fusion
3、Dense Feature Fusion Module
U-Net架构有很多限制,例如:编码器的下采样过程中缺少空间信息,并且不相邻层之间的特征之间缺乏足够的连接。要纠正高层特征中缺失的空间信息并充分利用这些非相邻层级的特征,一种直接的方法是首先将所有特征重新采样到相同的比例,然后将它们与bottleneck(连接层和卷积层)融合在一起作为DenseNet 中的节点。但是,简单地使用串联对于特征融合不太有效,因为来自不同层级的特征具有不同的比例和尺寸。
超分辨率的反投影(back-projection)技术是一种有效的方法,旨在通过最大程度地减少估计的高分辨率结果和多个低分辨率输入图像之间的重构误差来生成高分辨率内容。在《Bilateral back-projection for single image super resolution》中,针对具有单个低分辨率输入的情况开发了一种迭代反投影算法。
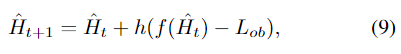
基于式(9)中的反投影算法,本文提出了一种DFF(Dense Feature Fusion Module)模块,用于有效地纠正丢失的信息并利用非相邻级别的特征。提出的DFF旨在通过错误反馈机制进一步增强当前层级的特征,并在编码器和解码器中使用。如图1所示,在每个层级引入了两个DFF模块,一个在编码器中的残差组之前,另一个在解码器中的SOS增强模块之后。编码器/解码器中增强的DFF输出直接连接到编码器/解码器中的所有剩下的DFF模块,以进行特征融合。
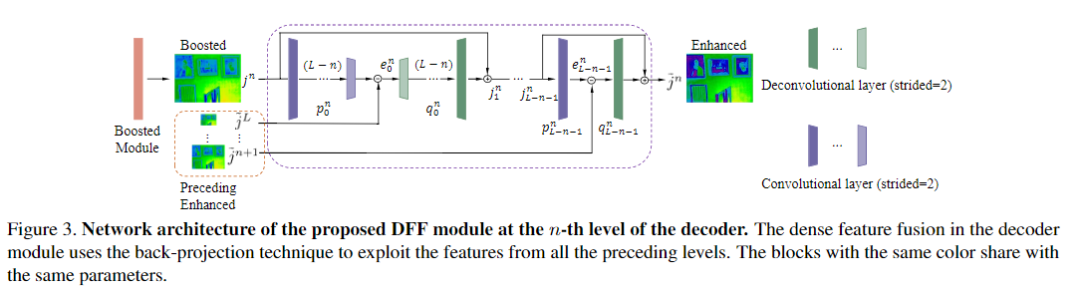
解码器的第n级DFF(图3中所示)由下式定义:
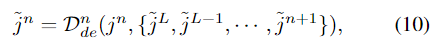
具体的更新细节可以参考原文。
class Encoder_MDCBlock1(torch.nn.Module):
def __init__(self, num_filter, num_ft, kernel_size=4, stride=2, padding=1, bias=True, activation='prelu', norm=None, mode='iter1'):
super(Encoder_MDCBlock1, self).__init__()
self.mode = mode
self.num_ft = num_ft - 1
self.up_convs = nn.ModuleList()
self.down_convs = nn.ModuleList()
for i in range(self.num_ft):
self.up_convs.append(
DeconvBlock(num_filter//(2**i), num_filter//(2**(i+1)), kernel_size, stride, padding, bias, activation, norm=None)
)
self.down_convs.append(
ConvBlock(num_filter//(2**(i+1)), num_filter//(2**i), kernel_size, stride, padding, bias, activation, norm=None)
)
def forward(self, ft_l, ft_h_list):
if self.mode == 'iter1' or self.mode == 'conv':
ft_l_list = []
for i in range(len(ft_h_list)):
ft_l_list.append(ft_l)
ft_l = self.up_convs[self.num_ft- len(ft_h_list) + i](ft_l)
ft_fusion = ft_l
for i in range(len(ft_h_list)):
ft_fusion = self.down_convs[self.num_ft-i-1](ft_fusion - ft_h_list[i]) + ft_l_list[len(ft_h_list)-i-1]
if self.mode == 'iter2':
ft_fusion = ft_l
for i in range(len(ft_h_list)):
ft = ft_fusion
for j in range(self.num_ft - i):
ft = self.up_convs[j](ft)
ft = ft - ft_h_list[i]
for j in range(self.num_ft - i):
# print(j)
ft = self.down_convs[self.num_ft - i - j - 1](ft)
ft_fusion = ft_fusion + ft
if self.mode == 'iter3':
ft_fusion = ft_l
for i in range(len(ft_h_list)):
ft = ft_fusion
for j in range(i+1):
ft = self.up_convs[j](ft)
ft = ft - ft_h_list[len(ft_h_list) - i - 1]
for j in range(i+1):
# print(j)
ft = self.down_convs[i + 1 - j - 1](ft)
ft_fusion = ft_fusion + ft
if self.mode == 'iter4':
ft_fusion = ft_l
for i in range(len(ft_h_list)):
ft = ft_l
for j in range(self.num_ft - i):
ft = self.up_convs[j](ft)
ft = ft - ft_h_list[i]
for j in range(self.num_ft - i):
# print(j)
ft = self.down_convs[self.num_ft - i - j - 1](ft)
ft_fusion = ft_fusion + ft
return ft_fusion
与其他采样和级联融合方法相比,由于反馈机制的原因,该模块可以更好地从递进层的高分辨率特征中提取高频信息,通过将这些差异逐步融合到下采样的潜在特征中,空间信息可以补救。另一方面,该模块可以利用所有先前的高级特征,并作为纠错反馈机制来完善增强功能以获得更好的结果。
4 实现细节
如图1所示,所提出的网络包含四步卷积层和四步反卷积层。在每个卷积和反卷积层之后使用负斜率为0.2的Leaky ReLU激活函数。残差组由三个残差块组成,在GRes中使用了18个残差块。在编码器模块的第一卷积层中,将卷积核大小设置为11×11像素,在所有其他卷积和反卷积层中,将卷积核大小设置为3×3。通过联合训练MSBDN和DFF模块,并使用均方误差(MSE)作为损失函数来约束网络输出和ground truth。所有实验均在NVIDIA 2080Ti GPU上进行。
class Net(nn.Module):
def __init__(self, res_blocks=18):
super(Net, self).__init__()
self.conv_input = ConvLayer(3, 16, kernel_size=11, stride=1)
self.dense0 = nn.Sequential(
ResidualBlock(16),
ResidualBlock(16),
ResidualBlock(16)
)
self.conv2x = ConvLayer(16, 32, kernel_size=3, stride=2)
self.fusion1 = Encoder_MDCBlock1(32, 2, mode='iter2')
self.dense1 = nn.Sequential(
ResidualBlock(32),
ResidualBlock(32),
ResidualBlock(32)
)
self.conv4x = ConvLayer(32, 64, kernel_size=3, stride=2)
self.fusion2 = Encoder_MDCBlock1(64, 3, mode='iter2')
self.dense2 = nn.Sequential(
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64)
)
self.conv8x = ConvLayer(64, 128, kernel_size=3, stride=2)
self.fusion3 = Encoder_MDCBlock1(128, 4, mode='iter2')
self.dense3 = nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
self.conv16x = ConvLayer(128, 256, kernel_size=3, stride=2)
self.fusion4 = Encoder_MDCBlock1(256, 5, mode='iter2')
#self.dense4 = Dense_Block(256, 256)
self.dehaze = nn.Sequential()
for i in range(0, res_blocks):
self.dehaze.add_module('res%d' % i, ResidualBlock(256))
self.convd16x = UpsampleConvLayer(256, 128, kernel_size=3, stride=2)
self.dense_4 = nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
self.fusion_4 = Decoder_MDCBlock1(128, 2, mode='iter2')
self.convd8x = UpsampleConvLayer(128, 64, kernel_size=3, stride=2)
self.dense_3 = nn.Sequential(
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64)
)
self.fusion_3 = Decoder_MDCBlock1(64, 3, mode='iter2')
self.convd4x = UpsampleConvLayer(64, 32, kernel_size=3, stride=2)
self.dense_2 = nn.Sequential(
ResidualBlock(32),
ResidualBlock(32),
ResidualBlock(32)
)
self.fusion_2 = Decoder_MDCBlock1(32, 4, mode='iter2')
self.convd2x = UpsampleConvLayer(32, 16, kernel_size=3, stride=2)
self.dense_1 = nn.Sequential(
ResidualBlock(16),
ResidualBlock(16),
ResidualBlock(16)
)
self.fusion_1 = Decoder_MDCBlock1(16, 5, mode='iter2')
self.conv_output = ConvLayer(16, 3, kernel_size=3, stride=1)
def forward(self, x):
res1x = self.conv_input(x)
feature_mem = [res1x]
x = self.dense0(res1x) + res1x
res2x = self.conv2x(x)
res2x = self.fusion1(res2x, feature_mem)
feature_mem.append(res2x)
res2x =self.dense1(res2x) + res2x
res4x =self.conv4x(res2x)
res4x = self.fusion2(res4x, feature_mem)
feature_mem.append(res4x)
res4x = self.dense2(res4x) + res4x
res8x = self.conv8x(res4x)
res8x = self.fusion3(res8x, feature_mem)
feature_mem.append(res8x)
res8x = self.dense3(res8x) + res8x
res16x = self.conv16x(res8x)
res16x = self.fusion4(res16x, feature_mem)
#res16x = self.dense4(res16x)
res_dehaze = res16x
in_ft = res16x*2
res16x = self.dehaze(in_ft) + in_ft - res_dehaze
feature_mem_up = [res16x]
res16x = self.convd16x(res16x)
res16x = F.upsample(res16x, res8x.size()[2:], mode='bilinear')
res8x = torch.add(res16x, res8x)
res8x = self.dense_4(res8x) + res8x - res16x
res8x = self.fusion_4(res8x, feature_mem_up)
feature_mem_up.append(res8x)
res8x = self.convd8x(res8x)
res8x = F.upsample(res8x, res4x.size()[2:], mode='bilinear')
res4x = torch.add(res8x, res4x)
res4x = self.dense_3(res4x) + res4x - res8x
res4x = self.fusion_3(res4x, feature_mem_up)
feature_mem_up.append(res4x)
res4x = self.convd4x(res4x)
res4x = F.upsample(res4x, res2x.size()[2:], mode='bilinear')
res2x = torch.add(res4x, res2x)
res2x = self.dense_2(res2x) + res2x - res4x
res2x = self.fusion_2(res2x, feature_mem_up)
feature_mem_up.append(res2x)
res2x = self.convd2x(res2x)
res2x = F.upsample(res2x, x.size()[2:], mode='bilinear')
x = torch.add(res2x, x)
x = self.dense_1(x) + x - res2x
x = self.fusion_1(x, feature_mem_up)
x = self.conv_output(x)
return x数据集:RESIDE dataset、HazeRD dataset、NTIRE2018-Dehazingchallengedataset
1、对比实验
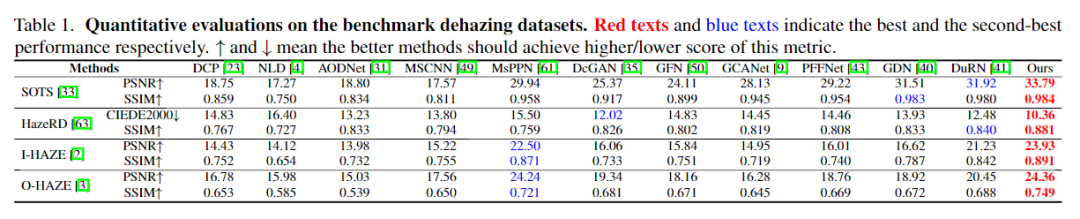

2、消融实验
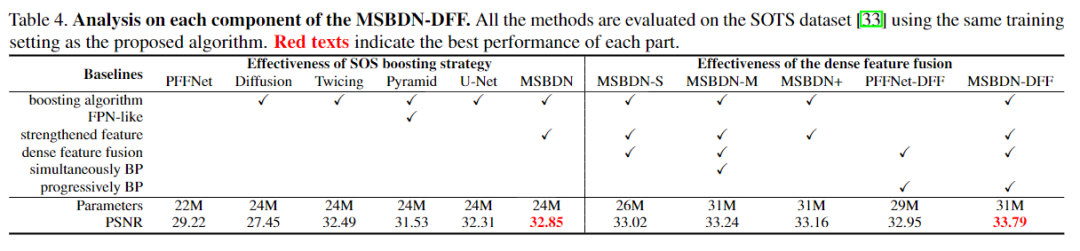

更多实验细节,可以参考原文。
下载
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020所有论文和300+篇代码开源的论文项目,开源地址如下:
https://github.com/amusi/CVPR2020-Code
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2100+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加微信群
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



