新浪微博与机器学习能擦出什么火花?一文了解用户表示方法对微博用户属性分类性能的影响

【注】本文已被中文信息学报录用待发表
微博作为一种短文本社交网络,已经成为了中国最大的微博平台。微博发布门槛较低,文体个性随意,且内容形式丰富多样,因此携带有大量的用户特征信息。根据用户在社交网络上的行为信息以及其所发布内容推断用户的属性信息具有极高的研究价值和商业价值。
其中,如何根据用户数据构建良好的用户表示以便于分类器取得更好的分类效果是用户属性分类的重要问题。因此,本文探究了八种用户表示的方法对性别、年龄和地域三种属性分类结果的影响,并提出了分布式表示与One-Hot表示相结合的用户表示方法,实验表明,这种方法可以有效提高三种属性上分类器的分类性能。
作者| 哈工大SCIR 孙晓飞,丁效,刘挺
1引言
随着以微博为代表的社交平台的迅速发展,社会媒体已经成为了重要的信息来源和传播介质。微博发布门槛较低,文体个性随意,且内容形式丰富多样,具有鲜明的个人特征,因此,微博中携带有大量的用户特征信息。如何根据用户在社交网络上的行为信息以及其所发布内容推断用户的属性信息对科学研究和商业应用都有着极高的价值。
目前,主流的用户属性推断方法是基于机器学习的分类方法,亦即将属性推断问题转化为属性分类问题,在向量化的用户表示的基础上采用现有的机器学习方法对用户属性进行分类。在不改变现有成熟分类方法的前提下,如何得到更好的用户表示成为了用户属性分类问题的核心问题。
本文研究了不同用户表示方法对性别、年龄、地域三种用户属性分类性能的影响,并在现有表示方法的基础上提出了将半监督的分布式表示和One-Hot表示相结合的方法,实验结果表明,结合半监督表示和One-Hot表示的用户表示方法可以有效提高用户属性分类的效果。
2 相关研究
2.1 用户属性分类
伴随着互联网的发展Burger和Henderson[1]以及Nowson和Oberlander[2]等人首先在正式博客中进行了用户属性分类的相关研究。
随着社交网络的兴起,基于短文本的用户画像识别得到了众多学者的关注。Delip Rao[3]等人基于Twitter上的文本信息对性别、年龄、地域、政治倾向四个属性进行了识别并分别取得了72.33%、74.11%、77.08%和82.84%的准确率。他们将该问题视为二元分类问题,其研究结果表明,用户的词汇使用、标点符号使用、表情符号使用对识别准确率有较大影响。
Faiyaz Al Zamal[4]等人通过用户的朋友信息对性别、年龄和政治倾向性进行了识别,重点探讨了不同的朋友信息(如朋友数量、关系亲疏)对识别结果的影响,取得了91.8%的最高准确率。John D. Burger[5]等人基于1850万Twitter用户数据进行了性别识别的研究,通过综合多个分类模型联合识别性别,取得了92%的准确率。
Claudia Peersman[6]等人基于Netlog(一个来自比利时的社交网站)上的用户数据研究了年龄和性别的识别问题,在研究过程中,他们将性别信息也作为年龄识别的输入数据,实验结果表明,用户的性别信息可以对年龄段识别起到辅助作用。Aron Culotta[7]等人基于用户对Twitter上150个网站的公共主页的关注关系,利用逻辑回归的方法,对性别、年龄、收入、教育程度等属性进行了识别,并取得了很好的效果。
2.2 文本特征表示
单纯的文本信息在大多数情况下是无法直接用于分类任务的,必须将其中的文本信息转化为数字化的形式(向量)。
目前,主流的向量化形式有两种:独热表示(One-Hot Representation)和分布式(Distributed Representation或Word Embedding)表示。
One-Hot的形式,即向量的每一维表示一个词,如果该词在文本中出现则该维记为1(或加一),否则记为0。它把每个词都表示为一个长度等于词典长度的向量,而且向量中只有少数维度值为非0,其他维度上都为0。One-Hot表示的优点是非常简洁,但是其缺点是本身不能表示任何语义特征,向量之间是完全孤立的,无法表现彼此之间可能存在的联系。
分布式词表示(Word Embedding 或 Distributed Word Representation)由Hinton[8] [9]在1984年提出。2006年Bengio[10]提出了以神经网络模型为基础的神经概率语言模型(Neural Probabilistic Language Model)。2008 年,Collobert [11]等提出了一种计算词向量的方法。2013年,Mikolov[12] [13]等提出了CBOW(Continuous Bag-of-Word)和Skip-gram两种词向量训练模型,并制作了著名的工具包word2vec,它可以在普通个人电脑上迅速得到词的分布式表示。Mikolov[14]等人在word2vec基础上提出了doc2vec方法,可以对文档进行向量化表示。
2.3 图特征分布式表示
除了利用文本的分布式表示,一些学者也研究了图节点的分布式表示。Perozzi[15]等人提出了Deepwalk的方法,通过随机游走的方式产生若干随机序列化路径,然后通过Skip-gram模型对节点的分布式表示进行权重更新,从而学习到节点的分布式表示。
Jian Tang 等人[16]提出了学习网络节点分布式表示的LINE(Large-scale Information Network Embedding)方法。其基本假设是:相连的节点之间边权值越大,表示两个节点之间相似程度越高;两个节点之间共通连接的节点数越多,表示两个节点之间相似程度越高。基于这两种假设,LINE对节点的相似程度进行了建模并进行梯度下降的求解。
3实验方法
3.1 数据描述
通过新浪微博API和分布式爬虫,本文共获取到2万用户的属性数据、文本数据和1千万条关系网络结构数据。
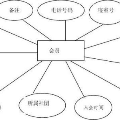
用户的属性数据包括性别、年龄和地域。其中,性别为男和女,年龄为大于30岁和小于30岁,地域划分为北部、南部和西部(见图3-1)。为了简化地域分布的划分,本文不考虑地域为“其他”和“海外”的用户的属性分类问题。
用户的文本数据包括微博、表情符号、短连接。最后,采用LTP[17]分词平台对文本进行了分词处理。
关系网络结构数据为微博的关注关系,通过这种关系我们构建了用户的社交网络关系图。
图 3-1 地域划分示意图
3.2 数据清洗
从微博上获取的原始数据含有大量的噪声数据。噪声的来源包括:大量的公众号的存在(如公司微博、产品微博、粉丝团等)、用户信息错误或过期(如年龄信息错误和求学、工作等带来的地域迁移等)、无意义微博(如许多微博接入应用发布的微博)等。我们采用了以下五种方式对数据进行清洗。
(1) 通过人工标记若干敏感词进行过滤:移除用户名中带有“公司”“公共主页”“粉丝团”“基金”“旅行”等敏感词汇的用户。
(2) 根据用户活动频率过滤:本文要求集中的用户要求必须为活跃用户。活跃用户被定义为满足以下三条特征的用户
a. 最近一周内至少发布过一条微博;
b. 最近一月内至少发不过5条微博的用户;
c. 微博总数大于20条。
(3) 删除出生日期在2010年之后和1950年之前的用户(即年龄小于五岁和大于65岁的用户)。
(4) 根据用户发布的微博中带有地域信息的微博对用户地域信息进行更新。
(5) 根据微博来源过滤微博:微博发布时会带有来源信息(如“来自 iPhone客户端”“来自 微博 weibo.com”等),根据我们的观察,我们收集了若干合理微博来源,移除了来源为“勋章馆”“优酷土豆”“美拍”等不合理来源的微博。
3.3 用户表示
本文采用了五种用户表示方法,分别是One-Hot表示、基于用户文本的分布式表示、基于用户关系网络的分布式表示、半监督的网络分布式表示和联合表示。
3.3.1 One-Hot表示
One-Hot表示是最常见的文本向量化表示形式,即向量的每一维表示一个词,如果这个词在文本中出现则记为1,否则记为0。One-Hot表示的优点是非常简洁,但是其缺点是本身不能表示任何语义特征,向量之间是完全孤立的,无法表现彼此之间可能存在的联系。为了避免维度过大,本文通过卡方检验的方式选取了10000个词作为特征。为了取得更好的结果,在词特征的基础上同时加入了表情符特征(emoticon)、短连接特征(URL)和用户名特征(user name)。
3.3.2 基于文本的用户分布式表示
基于word2vec的分布式表示:首先基于word2vec工具,首先对词进行向量化,获得词的低维表示。然后将用户所使用的词进行池化(Max Pooling),亦即对所有用户使用的词汇的词向量在每一维度上取最大值,以得到用户的向量化表示。
基于doc2vec的分布式表示:将每个用户视为一篇文档,文档的句子即用户所发布的微博。因此,通过doc2vec工具就可以直接获得用户的向量化表示。
3.3.3 基于网络结构的用户分布式表示
由于仅有的两万用户之间所构建的关系网络图较为稀疏,无法得到较好的节点分布式表示,而全网关系网络图又过于庞大,会给数据的存储和学习速度带来较大的压力,因此,我们对在两万用户关系网络图的基础上进行了两次广度优先搜索,对原始网络图进行了扩展,其过程如图3-2。
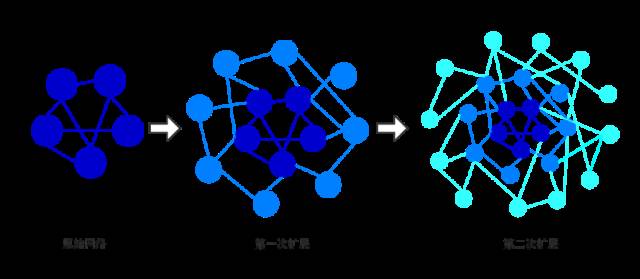
图 3-2 网络图扩展示意图
针对上述网络结构,我们采用了基于CBOW(Continuous Bag-of-Word)模型的Deepwalk[15]工具和LINE[16]工具对网络结构进行了建模以学习网络结构中用户的分布式表示。
3.3.4 半监督的网络分布式表示
上述两种学习分布式表示的方法都是采用无监督的方式,可以产生一般化的用户分布式表示从而用于多种任务,然而,这种方法并没有利用任何的有标记数据,其结果是产生的向量不具有任务针对性,为了提升实验的效果,我们在学习用户分布式表示中加入一些有监督的信息,从而使得学到的的用户表示更加适用于用户画像任务。
我们在Deepwalk的基础上采用了两种半监督方法学习用户的向量化表示:
一种最直接的方法就是在Deepwalk得到的随机游走路径中插入一定的有监督信息,然后在新的路径中学习用户的分布式表示,如原路径为:
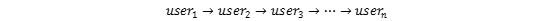
则插入有监督信息(label)后路径为:
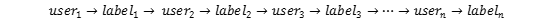
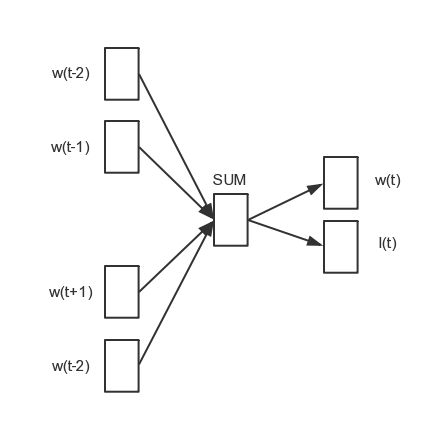
图 3‑3有监督的CBOW模型
另一种方式是直接将词w对应的label信息(记为lw)加入到word2vec模型中,其模型如图 3-3所示。
在通过w的上下文context(w)后,不仅计算p(w |context(w)),还要计算p(lw |context(w)),并对权重进行更新。根据和向量计算p(lw |context(w))的方法是逻辑回归,其损失函数如式 (3-1) (3-2) 。
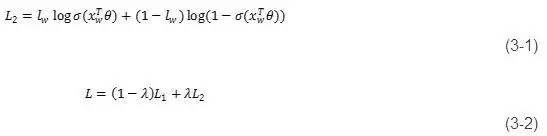
其中xw表示词w的上下文向量的加和,θ表示待学习参数,σ表示sigmoid函数。表示word2vec模型中的损失函数,L1表示CBOW模型中针对于w的的context损失函数,L2表示针对于w的label的损失函数,λ表示L2的权重。
其优化的目标函数如式(3-3)、(3-4)、(3-5)、(3-6),采用梯度上升法求解。

3.3.5 联合表示
在上述模型的基础上,将One-Hot表示和网络结构的半监督分布式表示所获取到的向量进行拼接,构建了联合表示的用户向量。这种表示方法可以同时利用文本信息和网络结构信息。
3.3 模型选择
本文选择的分类模型是逻辑回归模型,对于地域属性中的多分类问题采用的是Softmax回归(在下文中统一称之为逻辑回归)。逻辑回归是一种较为成熟的分类器,相比于贝叶斯分类器,逻辑回归对实数向量的支持更好;而相比于SVM和神经网络等分类器,逻辑回归的模型更为简单,训练速度更快,可以迅速得到实验结果;而相对于集成学习,逻辑回归由于模型简单且对经验等因素依赖较小,其结果更适合体现输入数据不同对最终实验结果的影响。基于以上原因,本文选择了逻辑回归模型作为分类器。
4实验结果
4.1 One-Hot表示
集成学习的主要思想使用多种分类器对数据进行分类,起到弱分类器加和得到强分类器的效果。本文对上述的五中不同特征采用了不同的分类器,分别得到其临时分类结果后,将结果输入到总分类器中,得到最终结果。其中,特征分类器得到的结果是K维实数向量,其中K表示属性的值域大小(如对年龄K=1,对地域K=3)。
最终采用五折交叉验证后的结果如表1所示:
表1 One-Hot表示实验结果

4.2 利用文本的用户分布式表示
本节使用word2vec和doc2vec两个工具通过用户的文本数据分别学习用户的分布式表示,并采用逻辑回归分类器对用户的不同属性进行分类。
利用基于word2vec(生成的向量长度为100,窗口大小为5,模型为CBOW模型,算法为Hierarchical Softmax模型)生成的用户分布式表示实验结果见表 2。
表2 word2vec实验结果

利用基于doc2vec(生成的向量长度为100,窗口大小为5,模型为CBOW模型,算法为Hierarchical Softmax模型错误。)生成的用户分布式表示实验结果见表3。
表3 doc2vec实验结果

从实验结果的对比可以看出,单纯词向量累加的形式所获取到的用户分布式表示并不能有效地提高实验的效果,相反,各个参数都有所下降。与之相比,采用doc2vec工具直接得到的用户分布式的表现表示虽然较之词袋模型仍然有所下降,但是却要高于word2vec累加的表现。
4.3 基于网络结构的用户分布式表示
本节中,我们使用Deepwalk和LINE两个工具通过用户的关系网络数据分别学习用户的分布式表示,并采用逻辑回归分类器对用户的不同属性进行分类。
基于DeepWalk(生成的向量长度为100,窗口大小为5,模型为CBOW模型,算法为Hierarchical Softmax模型,五折交叉验证)生成的用户分布式表示实验结果见表4。
表4 Deepwalk实验结果

基于LINE(一度节点生成的向量长度为200,二度节点生成的向量长度为200,总长度为400)生成的用户分布式表示实验结果见表5。
表5 LINE实验结果

从实验结果可以看出,用户的网络结构信息蕴含了丰富的用户画像信息。这一结论与Delip Rao[3]等人在Twitter上做用户画像工作所得到的结论不同,原因是Delip Rao等人只利用了用户社交网络的数量信息——朋友数、粉丝数、粉丝中属性分布比例——而没有利用更深层的网络结构信息。
另外,性别属性的准确率、召回率、F1值都接近词袋模型的结果,而年龄、地域属性的三个参数都要高于词袋模型的表现。造成这种结果的原因是,用户关系网络本身是对用户的一种聚类的体现,用户之间的连接更倾向于在相近年龄段、相近地域的人之间产生,因此对于年龄和地域两个属性而言,用户网络结构比用户用词习惯含有更多的相关信息。
4.4 基于网络结构的半监督用户分布式表示
本节使用半监督的Deepwalk算法通过用户的关系网络数据分别学习用户的分布式表示,并采用逻辑回归分类器对用户的不同属性进行分类。
基于插值方式的Deepwalk(生成的向量长度为100,窗口大小为5,模型为CBOW模型,算法为Hierarchical Softmax模型)生成的用户分布式表示实验结果见表6。
表6 半监督插值Deepwalk实验结果

表7 半监督word2vec实验结果基于半监督word2vec的Deepwalk生成的用户分布式表示实验结果见表7。
表7 半监督word2vec实验结果

根据实验结果可以看出,半监督的Deepwalk方法得到的用户分布式表示可以更好地对性别、年龄和地域三个属性进行分类。
4.5 One-Hot表示与分布式表示集成学习
本节在4.1节的基础上加入用户网络结构获得的用户表示,以提高分类效果。其实验结果见表8。
表8 One-Hot表示与分布式表示集成学习实验结果

从实验结果可以看出,结合One-Hot特征与网络关系的分布式特征得到的用户表示可以得到更高的准确率、召回率和F1值,事实上,目前得到的准确率是所有实验中效果最好的。
5 结论
针对新浪微博上的用户属性分类问题,我们研究了八种不同的用户表示方法对性别、年龄、地域是那种属性分类效果的影响。同时,本文提出了一种半监督的分布式表示方法。实验表明,将半监督表示与One-Hot表示相结合的联合表示在三个属性上皆取得了最好的实验结果。
参考文献
[1] Burger J D, Henderson J, Kim G, et al. Discriminating gender on Twitter[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 1301-1309.
[2] Nowson S, Oberlander J. The Identity of Bloggers: Openness and Gender in Personal Weblogs[C]//AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs. 2006: 163-167.
[3] Rao D, Yarowsky D, Shreevats A, et al. Classifying latent user attributes in twitter[C]//Proceedings of the 2nd international workshop on Search and mining user-generated contents. ACM, 2010: 37-44.
[4] Al Zamal F, Liu W, Ruths D. Homophily and Latent Attribute Inference: Inferring Latent Attributes of Twitter Users from Neighbors[J]. ICWSM, 2012, 270.
[5] Burger J D, Henderson J, Kim G, et al. Discriminating gender on Twitter[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 1301-1309.
[6] Peersman C, Daelemans W, Van Vaerenbergh L. Predicting age and gender in online social networks[C]//Proceedings of the 3rd international workshop on Search and mining user-generated contents. ACM, 2011: 37-44.
[7] Culotta A, Ravi N K, Cutler J. Predicting the Demographics of Twitter Users from Website Traffic Data[C]//Proceedings of the International Conference on Web and Social Media (ICWSM), in press. Menlo Park, California: AAAI Press. 2015.
[8] Hinton G E. Distributed representations[J]. 1984.
[9] Hinton G E. Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society. 1986, 1: 12.
[10] Bengio Y, Schwenk H, Senécal J S, et al. Neural probabilistic language models[M]//Innovations in Machine Learning. Springer Berlin Heidelberg, 2006: 137-186.
[11] Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C]//Proceedings of the 25th international conference on Machine learning. ACM, 2008: 160-167.
[12] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[13] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
[14] Le Q V, Mikolov T. Distributed representations of sentences and documents[J]. arXiv preprint arXiv:1405.4053, 2014.
[15] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 701-710.
[16] Tang J, Qu M, Wang M, et al. LINE: Large-scale Information Network Embedding[C]//Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
[17] Che W, Li Z, Liu T. Ltp: A chinese language technology platform[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Demonstrations. Association for Computational Linguistics, 2010: 13-16.
专属福利:中国国内级别最高、规模最大的人工智能大会——中国人工智能大会(CCAI)将于7.22-7.23在杭州举行,目前大会 8 折 专属优惠门票火热抢购中,赶快扫描下方图片中的二维码或点击【阅读原文】火速抢票吧。
中国人工智能大会(CCAI),由中国人工智能学会发起,目前已成功举办两届,是中国国内级别最高、规模最大的人工智能大会。秉承前两届大会宗旨,由中国人工智能学会、阿里巴巴集团 & 蚂蚁金服主办,CSDN、中国科学院自动化研究所承办的第三届中国人工智能大会(CCAI 2017)将于 7 月 22-23 日在杭州召开。
作为中国国内高规格、规模空前的人工智能大会,本次大会由中国科学院院士、中国人工智能学会副理事长谭铁牛,阿里巴巴技术委员会主席王坚,香港科技大学计算机系主任、AAAI Fellow 杨强,蚂蚁金服副总裁、首席数据科学家漆远,南京大学教授、AAAI Fellow 周志华共同甄选出在人工智能领域本年度海内外最值得关注的学术与研发进展,汇聚了超过 40 位顶级人工智能专家,带来 9 场权威主题报告,以及“语言智能与应用论坛”、“智能金融论坛”、“人工智能科学与艺术论坛”、“人工智能青年论坛”4 大专题论坛,届时将有超过 2000 位人工智能专业人士参与。