用户画像之用户性别识别

性别是人类差异最大的特征之一,又是群体行为、偏好和需求等方面的基本影响因子之一;性别识别的重要性和价值性不言而喻,每个用户画像产品的构建,基本都会遇到性别标签的识别需求。
目前业内用户性别识别的方法很多,最大的特点是基于用户的行为进行用户识别,识别的准确性也参差不齐。作者认为影响识别准确性的关键原因在于这些用户行为蕴含的性别影响因子有多大,如果性别的区别对这些行为没有多大的影响力,那模型和算法的准确性将会遇到明显的瓶颈。同时,基于用户行为的性别识别涉及的数据面非常广、数据依赖链条很长、数据计算复杂度很高,识别效能反而成为了痛点!
在这里,作者分享一下贝聊的用户性别识别模型:基于用户信息(姓名)的用户性别识别方法!这虽然只是一个单因素识别模型,但是实际识别准确率却高达 90% 以上,为什么效能这么高?主要是因为性别对命名的影响至关重要!下面我们分步骤来讲解下贝聊的用户性别识别模型构建过程。
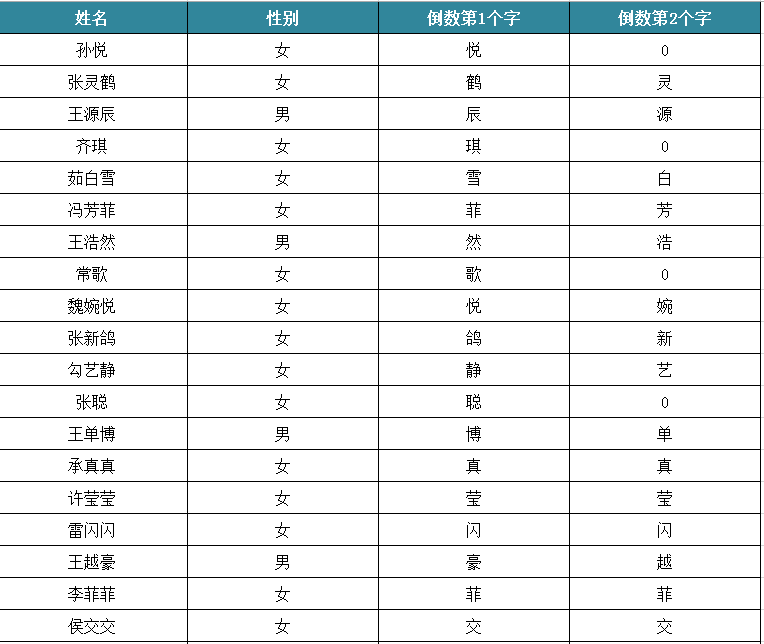
因为姓名 + 性别不能大概率锁定出唯一的用户,所以姓名和性别的数据敏感度并不高,通过百度等搜索引擎可以轻松获得,这里不详述。贝聊有自身的数据样本,并且进行了数据脱敏处理,初期过滤了一个十多万条“姓名—性别“的高精度种子样本库(已足够用!),并进行分词处理,结果库如下图(图中数据并非贝聊真实用户,仅是演示案例!)
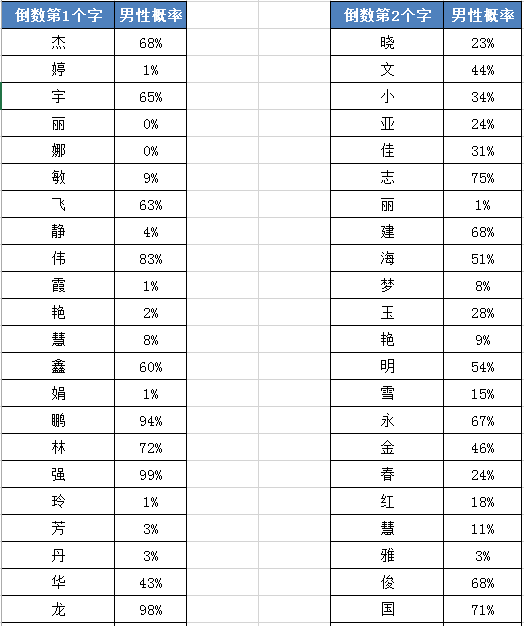
贝聊的用户性别识别模型对不同词在姓名中的位置做了区分,因为同一个词用在名字的不同位置的性别含义有较大区别!例如:“海”字,在用作名字的最后一个词时,男性概率高达 95%;但作为名字的中间词时,男性概率仅有 51%(基本是一个中性词)。经过样本数据的计算,统计出每个词的性别概率,结果库如下图所示(演示数据!)
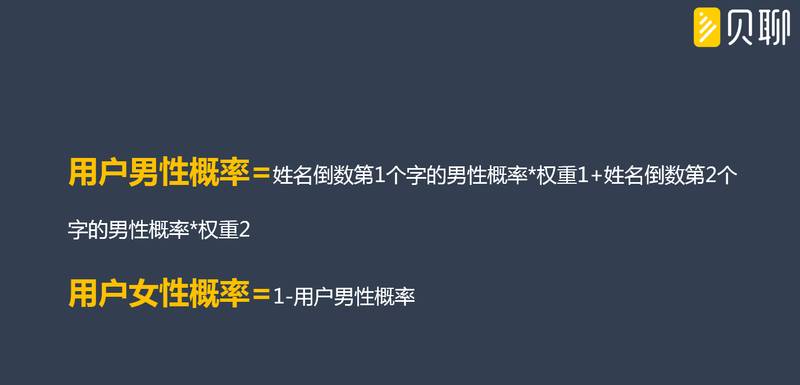
基于用户信息的用户性别识别模型构建非常简洁,因为是文本数据,也不需要用到相对复杂一些的逻辑回归等算法,模型构建的思路基本上是“词性—性别概率”关系库构建的逆过程。姓名的识别概率公式如下图:
计算出用户性别的识别概率后,通过设定阈值,即可得到用户的性别标签。整体而言,模型计算量非常小,可解释度很高,模型出错时问题容易追踪,预测效能非常好!
计算用户性别识别概率后,通过设定不同的阈值,可以得到不同的预测准确性。相对来说,阈值越低(例如预测男性概率大于 50% 时,就算男性,否则女性),则可预测的用户面较大,阈值越高(例如预测男性概率大于 60% 时,才算男性,小于 40% 才算女性),则预测的准确性得到保障,但有部分用户没法识别。
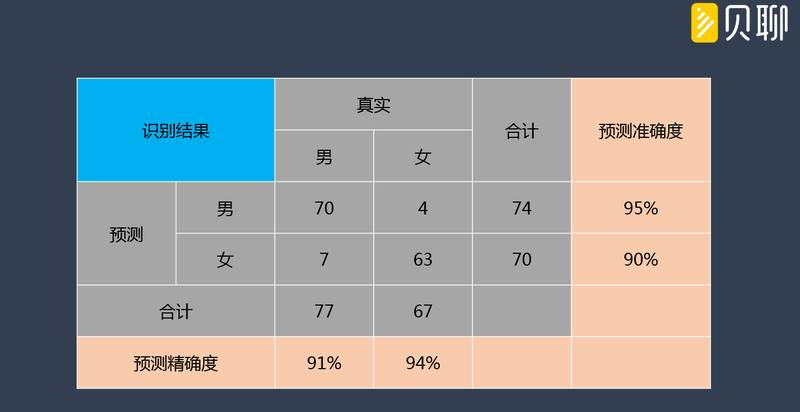
上图,我们抽取了部分贝聊员工来做模型结果验证测试(阈值设定为 50%);从数据来看,模型准确性非常高,呈现出以下特点:
预测准确度和精确度,都高于 90%;其中男性的预测准确度更高,女性的预测精确度更高;说明相对而言,女性用户一般不会采用男性化字眼的名字。
预测结果仍有 5%-10% 左右的误差率;这应该是男性命名女性化,女性命名男性化影响所致,或者命名性别中性化。在单因素模型下,只能通过调整阈值来解决,否则就需要引入其他因子,构建多因素识别模型。
根据作者的经验,基于用户姓名的用户性别识别模型具有较好的适用性、可部署性和延展性,在研究单因素识别方法方面提供了一定的参考价值;也可以在此基础上,引入其他因素,提高模型的准确性。
注:部分公司可能没有用户的姓名,只有用户昵称,这是数据局限性的问题,当然也期待大家进行基于用户昵称的用户性别识别模型的准确性。
本文系贝聊技术团队原创文章,已经授权 InfoQ 公众号转发传播。
今日荐文
点击下方图片即可阅读

关于用户画像产品构建和应用的几点经验





