机器学习与微博:TensorFlow在微博的大规模应用与实践
借 AI 前线提供的交流机会,我给各位汇报一下 TensorFlow 在微博的使用情况和在分布式计算上的一点经验,错误疏漏不足之处,敬请批评指教。

今天的分享内容由虚到实,由概括到具体。

微博的日活和月活数量都在增长,移动端比例很高,占 91%。2017 年 4 月份的财报显示,营收同比增涨 67%,一个重要原因就是移动端抢到了用户的碎片时间。

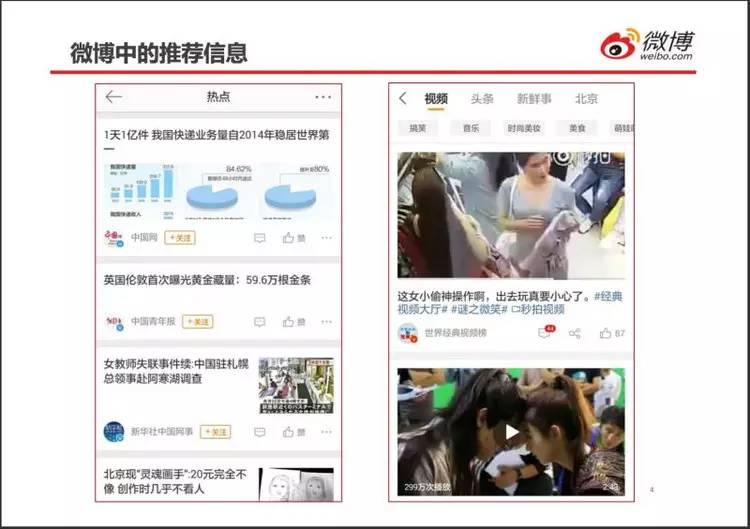
微博里随处可见推荐信息:推荐的新闻、推荐的视频、推荐的新账号。最重要还有推荐的广告。
用户登录以后,立刻就要计算推荐什么内容。拿推荐广告来说,备选的广告数以万计,需要排序给出最可能被点击的几条广告。
如果切中用户的购买需要,广告就不再是打扰。
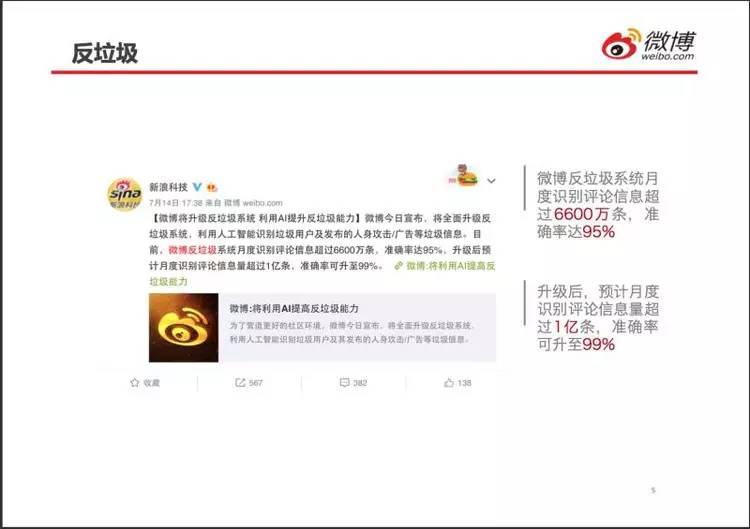
垃圾严重影响用户体验,色情、暴力、反动、低俗,宁可错杀不可漏网,十分严格。
人工智能反垃圾的目标是提高准确度、降低成本。
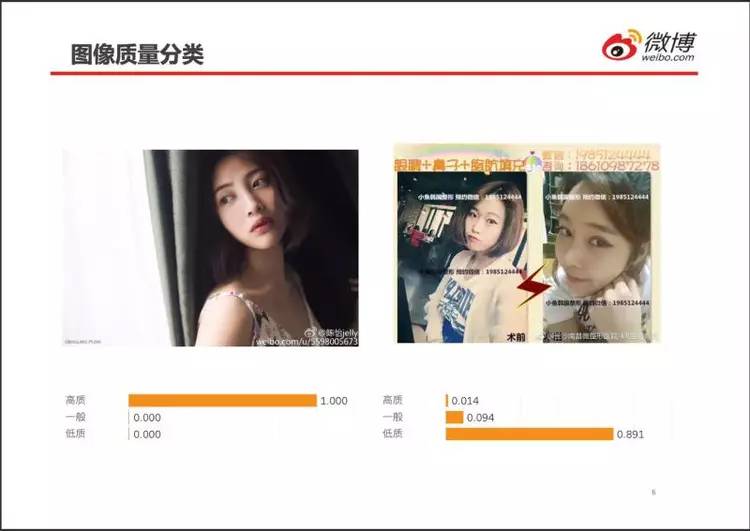
图像质量也是用户体验的基本要求。
用户可以容忍不感兴趣的图片,但很难容杂乱的图像。
例如左边的美女图,看起来赏心悦目,手机上刷过,即使不停下细看,也不会反感。
右边的图片,里面也是美女,但加上文字之后,立刻变得杂乱,版式与酒店里的小卡片相仿。很可能被认定为骗子。
明星是微博制胜的法宝。明星是公众人物,话题多、热度高、影响力大。明星粉丝狂热,消费力强。
为粉丝推荐她他喜欢的明星的行程、事件、各种评价,粉丝爱看。甚至明星代言的广告,粉丝可能都会喜欢。停留在微博的时间越长,有意无意浏览的广告就越多。正确识别明星就很重要了,如果不巧推荐了用户讨厌的明星,可能就没了刷微博的心情。
明星脸识别是微博的特色,有海量的明星图片,也有巨大的识别需求。
明星脸识别有特别的困难:常用人脸识别研究所用的照片表情、造型较少,不同人之间的差别较大。而明星表情丰富,造型多变,无论男女都化妆!不少人妆容近似,有些整容脸连人脑都傻傻分不清,计算机就更难分清了。

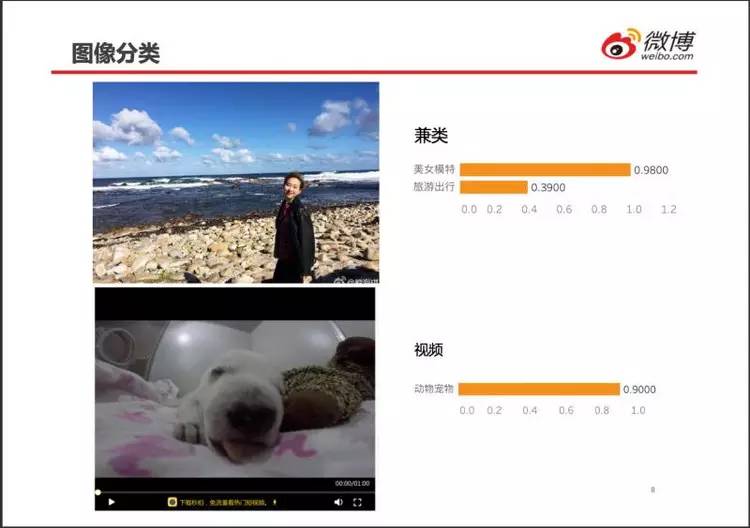
上部的图片可能归属两个及以上类别,因此称为“兼类”。
图片、视频分类的最终目的都是为了关联广告。喜欢旅游的用户就给她他推荐旅游景点、线路、酒店、机票、户外装备等。
如果广告能够切中用户本来就要买的物品,就不必费尽心机说服用户购买不必要的商品,只需要将购买场所由一个地点(网站、实体店)转移到另一个地点,将购买时间由将来转移到现在,将商品品牌由 A 切换为 B。这样广告效果自然会好很多,点击率高,用户还不反感。
例如,印度电影《三个白痴》中几次提到太空笔,我当时就特别想买一支,在京东上搜了半个小时。如果能够提前识别到这个广告点,并在播放过程中推荐购买链接,很可能立即就下单了。

但是,图像分类难,视频精细分类更难,又不得不分。短视频(5 分钟以内)方兴未艾,变现模式还不成熟,处于烧钱阶段。相对于文本、图片,短视频的带宽成本更高,消耗的用户时间更多。如果关联广告的转化率不高,入不敷出,无法长久。
务虚内容结束,下面是具体点的技术。

微博机器学习平台承担了离线训练和在线预测任务。微博实时产生的文本、图片、视频显示后转入后台,用于提取特征、离线训练。
越来越多的业务使用深度学习方法,TensorFlow/Caffe 框架被集成进来。
离线训练主要使用 GPU 机群。由于业务增长过快,计算机群有一部分来自阿里云。
这一页完全是个人理解。
对规模巨大的训练任务,TensorFlow 提供了分布式的模式。
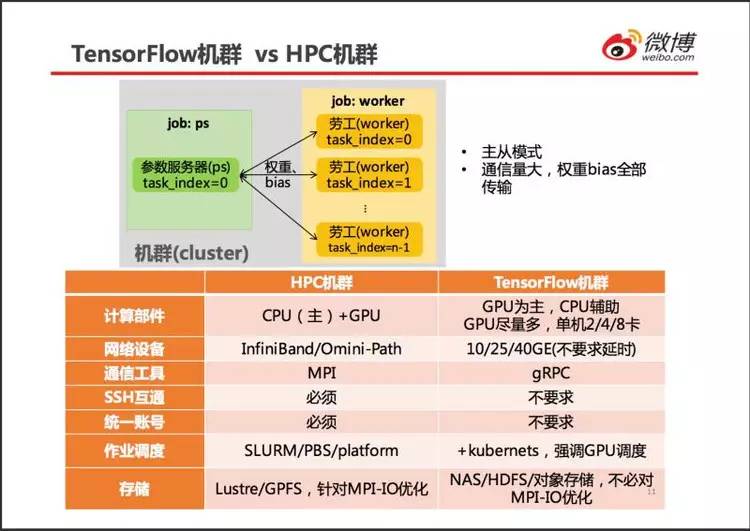
TensorFlow 分布式计算与 HPC 的 MPI(Message Passing Interface) 分布计算区别很大。用过 MPI 的人都知道,MPI 进程相互平等,保证没有瓶颈进程。MPI-IO 也设计得每个主机都能均匀分担 IO 压力。MPI 进程上的计算任务也要求均匀划分,保证各个进程的计算进度保持一致。MPI 进程之间也只交换数据块的边界,尽量减少网络流量,压缩通信时间。
TensorFlow 的分布式计算设计得简单粗暴。
若干参数服务器 (parameter server) 和若干劳工 (worker) 组成一个机群 (cluster),劳工承担运算任务,将每步运算得到的参数(权重和 bias)提交给参数服务器,参数服务器将来自所有 worker 的参数合并起来,得到全局参数,然后将全局参数发送给劳工。劳工在全局参数的基础上继续下一步运算。
TensorFlow 采用主从模式,参数服务器是瓶颈。每步都要传递所有的参数,网络流量太大,假设每个劳工上参数占用内存 1GB,机群包含 1 个参数服务器和 10 个劳工,那么每个迭代步将产生 20GB 的网络流量,按照 10GbE 网络计算,通信时间至少需 16 秒。而实际上,每个 batch 数据的运算时间可能还不足 1 秒,模型参数占用的内存可能远大于 1GB。从理论分析来看,TensorFlow 分布式运算的效率不如 MPI。
有人说深度学习只是高性能计算的一个特殊应用,我认为不是这样。
如图中表格所列,TensorFlow 机群就与 HPC 机群有重大区别。
HPC 机群的 3 大特点:高性能计算芯片(高端 CPU、GPU)、高速网络、并行存储。TensorFlow 机群只需要其中的 1 个:高端 GPU。
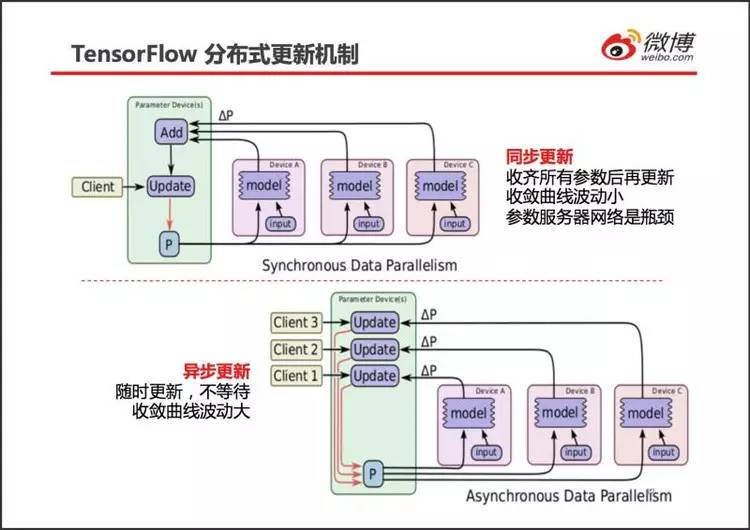
劳工在一批数据上训练得到∆W 和∆b(合称为∆P),称为一步训练。
如上图所示,所有的劳工(Device A/B/C)在完成一步训练后,暂停训练,将自己得到的∆P 发送到参数服务器(Parameter Device)。参数服务器一直等待,直到来自所有的劳工的参数变化量∆P 都接收成功。参数服务器将所有的∆P 相加取平均,然后用这个均值更新旧参数(更新公式请参见随机梯度算法),得到新参数 P,接着将 P 发送给所有的劳工。劳工在接收到新参数 P 以后,才进行下一步的训练。
与用 1 台服务器训练相比,用 N 台劳工同时训练 + 同步更新参数等价于将 batch 的规模扩大了 N 倍。具体来说,如果用 1 台服务器时,每步训练采用 100 张数字图片(batch=100), 那么用 4 个劳工得到的参数变化量(即∆P)同步更新,就相当于每步训练采用 400 张数字图片(batch=400)。从而,参数变化得更平稳,收敛更快。
同步更新也有缺点:整体速度取决于最慢的那个劳工。如果劳工之间的软硬件配置差别较大,有明显的速度差异,同步更新计算速度较慢。
为了避免劳工有快有慢造成的等待,TensorFlow 提供了异步更新策略。
如图下部所示,当有一个劳工训练得到一个参数变化量∆P 时,不妨假设是图中的 Device A,该劳工立即将∆P 发送给参数服务器。参数服务器接收到来自劳工 Device A 的∆P 后,不等待其它的劳工,立即用∆P 更新全局参数,得到全局参数 P,紧接着将 P 发送给劳工 Device A。劳工 Device A 接收到全局参数 P 后,立即开始下一步训练。
由异步更新参数的过程可知,它等价于只用 1 台服务器训练:都是每次用一小批(batch)图像训练更新参数,只是各批数据的上场顺序不能事先确定,上场顺序由劳工的随机运行状态确定。
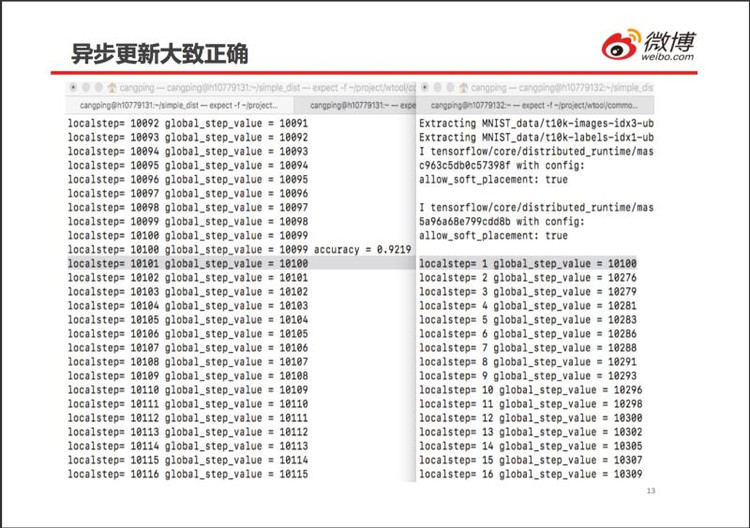
刚开始运算时,劳工 0(左边) 先算了 10100 步(对应 localstep), 此后劳工 1(右边)才开始运算。这说明,在异步运算模式下,劳工之间确实不相互等待。劳工 0 和劳工 1 都运算了全局第 10100 步 (global_step_value),说明运算的剖分并不十分准确。
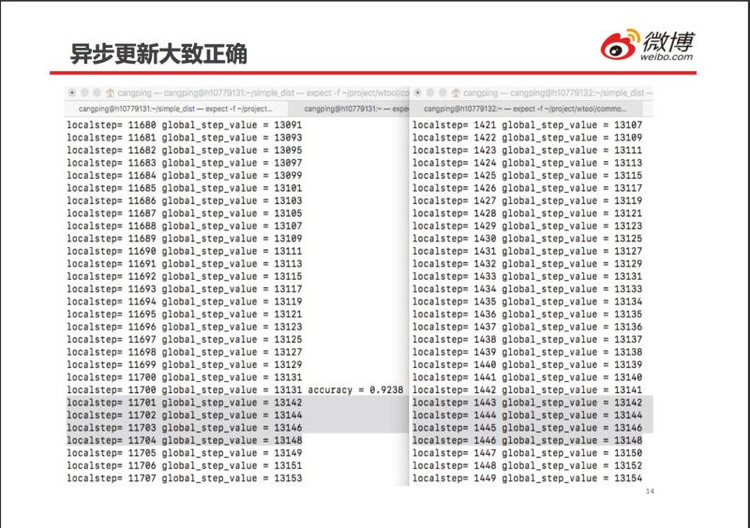
2 个劳工都执行了第 13142、13144、13146、13148 步,但都没有执行 13143、13145、13147 这 3 步。这说明 Tensorflow 异步更新的任务指派会随机出错,并不是绝对不重不漏。所幸随机梯度法对更新顺序没有要求,少量的错误对最终计算结果影响不大。
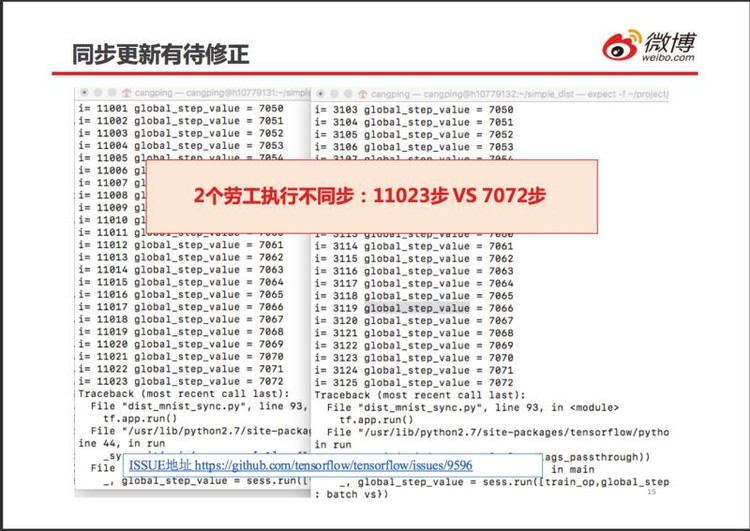
同步更新模式不能真正地同步执行,将程序杀死的时候,2 个劳工执行完的步数相差很多。劳工 0 本地执行了 11023 步之后,全局步数竟然只有 7072,肯定出错了。
网络上也有人报告了这个错误:
https://github.com/tensorflow/tensorflow/issues/9596,
TensorFlow 开发者已经确认这是一个漏洞,但尚未修复。

以 MNIST 手写数字识别为例,上部分公式迭代一步就使用所有 n 个样本。
下部公式将所有样本分割成若干批次(batch)。
TensorFlow 的异步更新,就是不同的劳工使用不同的小批训练样本来更新权重和 bias,不能事先确定每个劳工的更新顺序。具体举例:假设有 2 个劳工执行训练任务,劳工 0 负责更新奇数批次样本 b1/b3/b5…b499,劳工 1 负责更新偶批样本 b2/b4,…,b500。
由于各种随机因素,样本的使用顺序可能是 b1àb3àb5àb2àb7àb4à…因为样本的批次划分本身就是随机的,这样乱序更新仍然是随机的,对最终结果没有什么影响。
TensorFlow 同步更新时,对所有劳工得到的梯度求平均,然后更新权重和截距。仍然假设有 2 个劳工,它们分别训练第 1 批和第 2 批样本得到梯度∆w1 和∆b1 截距分别为∆w2 和∆b2,同步之后的梯度如图中所示。

从而,同步更新等价于一次使用 2m 个训练样本,正则化系数和 batch 大小都扩大为原来的 2 倍而已。如果劳工数量很多(例如 20 个),那么同步更新就等价于一次使用 2000 个训练样本,与划分 batch 的初衷不符。因此,建议不要使用同步更新。
注意公式里红色的(2m)
下面是一个具体优化案例:
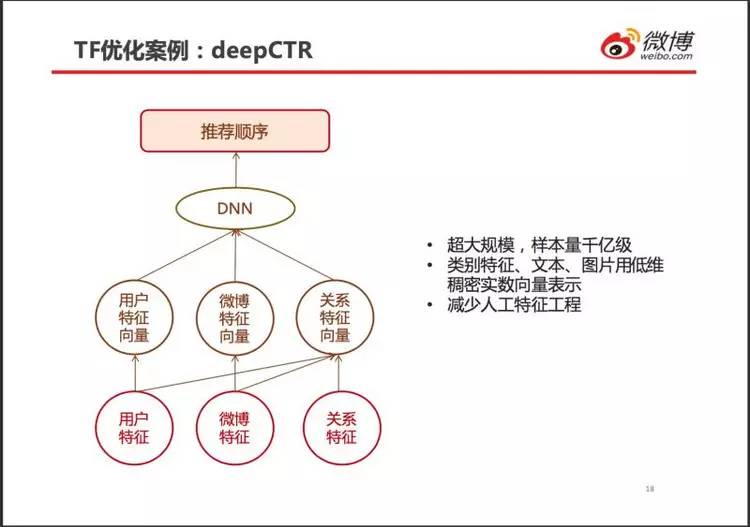
CTR(Click-Through-Rate,点击通过率)是营收的关键。
对候选广告按点击可能性排序,然后插入到用户信息流之中。
deepCTR 不完全是特征工程,输入层与隐层的连接关系也是不全连接。
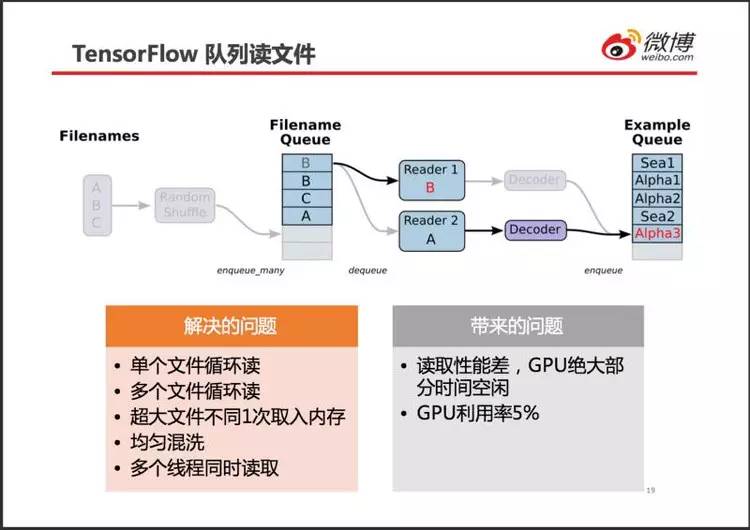
千亿样本数据近百 TB,为提高效率,采用多人推荐过的 TensorFlow 队列。
个人理解,队列的设计初衷很好(如图中表格所示),但实际性能很差,GPU 利用率只有 5%。查找原因发现,程序卡在线程同步操作上,而这个线程同步就来自于 TensorFlow 队列。于是尝试用别的方式读取训练样本文件。
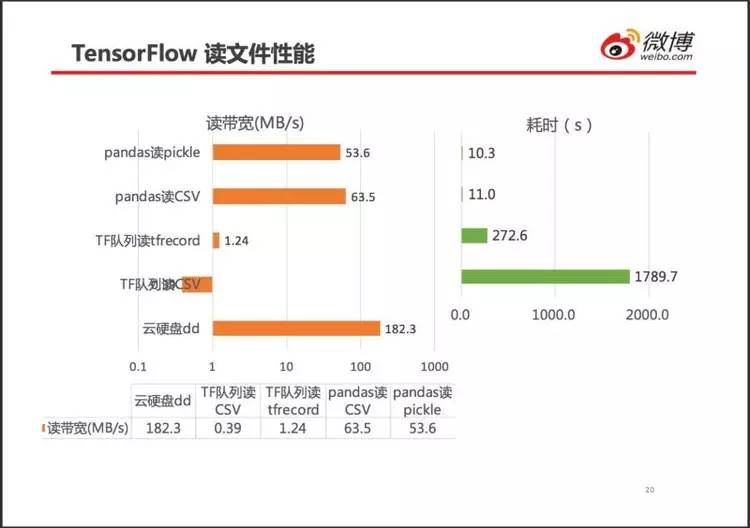
左图横轴采用对数坐标。
队列读以 CSV 带宽只有极限带宽的 1/467,队列读取 tfrecord 格式文件带宽提升至 1.24MB/s,提高至 3.2 倍。由于 tfrecord 格式文件较小,读完一个文件的耗时降低至 15%(272.6/1789.9)。
用 pandas 读取文件带宽达到极限带宽的 35%。最终舍弃 TensorFlow 队列,选用 pandas 读 CSV 文件。
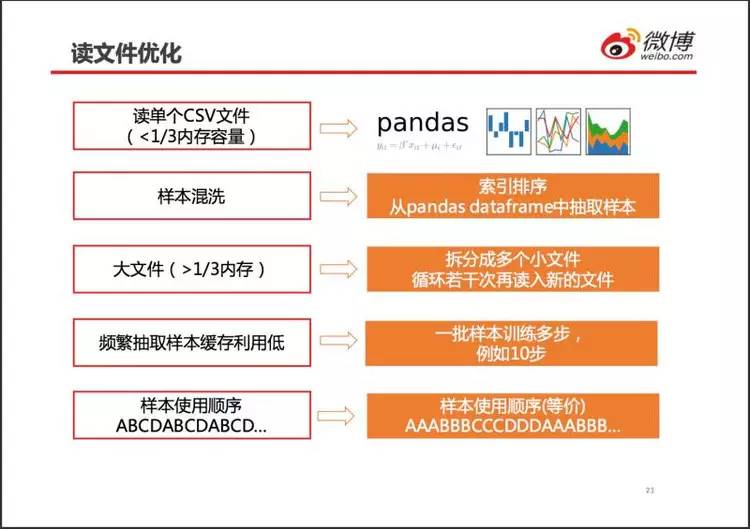
当 CSV 文件小于 1/3 内存时,直接用 pandas 一次性读入内存。不用 tf 队列,数据混洗就要程序员自己完成,所幸不麻烦。
对大于内存 1/3 的文件,直接拆分成多个小文件。需要程序员自行保证均匀使用各个小文件。
最后给各位汇报一个小游戏。

用 MNIST 训练得到的 CNN 网络来识别汉字,“霸”字被识别为 1。这点很容易理解,得到的 CNN 网络只有 10 个类别,不得不在 0~9 个数字中选一个。
因为“霸”字与任何数字都不像,识别为任何数字的“概率”应该都不太大吧,例如都小于 0.2(随便说的数值)。可是实际情况却是这样:0~9 分类对应的概率差别很大,最大接近 0.8,最小接近 0,卷积网络识别汉字的时候不会犹豫不决,错得十分坚定。
从这个小实验里可以发现几个问题:
图像的特征究竟是什么?如果有,如何用这些特征来区分不认识的图像(比如这个例子里的汉字)?
如何控制一个网络的泛化能力?这个例子中的泛化能力看起来太强了,以致于把汉字都识别成数字了。目前看来,CNN 的泛化能力几乎是听天由命。
softmax 后的值真的代表概率吗?看起来它们仅仅是和为 1 正数。概率本质的随机性体现在哪里呢?
这些问题,我还没有想明白,这里提出来,请各位朋友批评指教。
回答:cache 基本没有影响。batch_size 会有影响,最关键还是线程锁的问题。
回答:这个涉及到业务,不便透露。可以私下交流。
回答:数据并行,因此研究分布式运算。
回答:业务上具体做法不便透露。这里提醒一下,微博有举报、屏蔽功能。
回答:资源管理和分布式计算尝试过几种方案,开源软件 + 自行定制。多种机群,安全级别和管理方式不完全一样,因此资源管理方式(网络、存储、权限)也不一样。
回答:GPU 利用率是成本核算的重要指标,很重视。查看 GPU 利用率比较简单:命令行 nvidia-smi,英伟达还有专门的库,提供轻量级的 C、JAVA 等接口。
提高 GPU 利用率经验:如果显存能装得下,尽量使用 1 个模型训练;设定显存使用量(例如 0.5),将 2 个及以上作业放在同一个 GPU 上。IO 性能差的话,会导致数据供应不上,从而 GPU 利用低。PPT 中 deepCTR 优化案例就是这个情况。batch 太小、权重矩阵过小,都会导致不能充分利用 GPU 的大量核心(通常有 4000-5000 个),利用率低。
回答:目前没有对比过 tf 队列和 spark df。
今日荐文
点击下方图片即可阅读

2017 年已经过去 218 天,大数据杂谈 80 篇精选文章千万别又双叒叕错过啦
CNUTCon 全球运维技术大会将于 9 月 10-11 日在上海举行,大会主题是“智能时代的新运维”,并特设“大数据运维”专场,邀请了来自腾讯、苏宁等公司大咖分享他们在最新运维技术实践过程中遇到的坑与经验,更有 Google、Uber、eBay、BAT 等一线技术大牛现场为你解疑答惑,点击“阅读原文”了解更多精彩!9 折限时优惠,本文的读者在报名时输入 CNUTCon666 还可再减 200 哦!