「公平机器学习」最新2022综述
公平机器学习:概念、分析与设计最新综述论文

摘要
1 引言
机器学习是人工智能的一个重要分支,是对通 过数据或以往经验自动改进计算机系统或算法的 性能的研究[1, 2, 3]。随着数据的丰富与算力的提升, 机器学习技术得到了长足发展,已经在与大众生活 密切相关的诸多方面得到了广泛应用。受机器学习 自身本质和技术特征的影响,其预测和决策会产生 一定程度的偏见或不公平,这一问题逐渐引起科学 研究、产业界从业人员和社会公众的关注[4, 5]。在 预测和决策过程中,公平是指不存在基于个人或群 体的内在或后天特征的任何偏见、偏好、歧视或不 公正[6]。因此,一个不公平的算法是指其决策对某 一个体或特定群体存在偏见,由此引发对该个体或 群体的不公正待遇,并使其利益受到损害。

人工智能应用中的偏见歧视已经出现在不少场景。例如,机票预订系统 SABRE 和 Apollo 存在一 定程度上的不公平和偏见[7, 8],导致了航空公司之 间的不公平竞争;许多推荐系统会放大数据中的偏 见、引发不公平推荐[9, 10, 11],几乎所有的排名算法 都采取了“短视”效用优化策略,导致了不公平[12];基于深度学习的人脸识别算法极大地提高了识别 准确率,但大多数算法在男性面孔上的表现优于女 性面孔,即,人脸识别算法存在性别偏见[13, 14] ;简历 自动筛选系统通常会因应聘者无法控制的特质 (如,性别、种族、性取向等)给出带有偏见的评 测[9, 15],这样的不公平不仅会对拥有某些特征的求 职者产生歧视或偏见,也可能因错失优秀雇员而给 雇主带来损失;对电子病历或医疗记录进行分析可 预测(慢性)疾病,但是基于机器学习的疾病预测 对于某些族群的错误率明显高于其他族群,存在族 群偏见或歧视[16,17,18,19];教师评价系统 IMPACT[9, 20, 21]通过教师的年龄、教育水平、经验、课堂观察、 问卷调查等特征、学生学生考试成绩、学生问卷调 查和学校的问卷调查、教师的问卷调查等来学习并分析教师的工作表现及应得工作报酬,对贫困社区 教师可能产生系统性的较低评分,导致不公平;GRADE、Kira Talent 等大学入学评估系统通过学习 考生的就读学校、SAT 成绩、课外活动、GPA、面 试成绩等特征,给出接收/拒绝考生的结果或者考生 在所要求研究领域的潜在表现评分[22, 23],但存在对 特定种族群体的偏见和歧视[9, 24];刑事风险评估系。统 COMPAS、PSA、SAVRY 和 predPol 等[9, 25, 26], 依据被捕次数、犯罪类型、家庭地址、就业状况、 婚姻状况、收入、年龄、住房等,学习并给出被告 是否会再次犯罪的风险评分。ProPublica 曝光了这 类系统评估中的不公平和歧视[27,28];贷款发放评估 系统 FICO、Equifax、Lenddo、Experian、TransUnion 等[9],给出的针对贷款人的贷款还款计划和贷款年 利率的建议方案存在不公平,会针对女性或者某些 族群给出过高定价,造成系统性偏见[29];自然语言 处理中所依赖的历史训练数据中通常存在社会已 有成见,有放大社会对性别的已有成见的风险,导 致对不同性别群体的不公平[30]。共指消解系统 Stanford Deterministic Coreference System、Berkeley Coreference Resolution System 和 UW End-to-end Neural Coreference Resolution System 等都表现出了 系统性的性别偏见。类似的不公平现象也存在于在 线新闻、信息检索、广告投送等领域[30, 31, 32]。
机器学习已经应用于许多领域,对人们工作与 生活产生了巨大影响,而其中的公平和偏见问题直 接影响着社会和公众对其信任程度,影响着人工智 能系统的应用部署,是机器学习技术研究与应用开 发所面临的新挑战。如何对公平性进行概念定义及 度量?如何发现机器学习应用中的不公平?如何 设计公平机器学习或者具有公平属性的机器学 习?如何实现具有隐私保护或可解释性等能力的 公平机器学习,并最终实现符合伦理的机器学习?鉴于此,为明确以上挑战的内涵并进行有效应对, 本文进行了介绍与讨论,对相关研究工作进行了系 统性调研与剖析,并对公平机器学习的未来研究及 值得关注的问题进行了展望。图 1 为本文的组织架 构图。
2 公平性概念及度量
公平性问题一直是哲学、政治、道德、法律等 人文社科领域感兴趣的话题,公平性概念的提出和探讨始于上世纪 60 年代[33, 34]。能够确保每个人都 有平等的机会获得一些利益的行为,称为公平的行 为,或者称这样的行为具有公平性。不能够确保每 个人平等地获得一些利益,使得弱势群体的利益受 到损害的行为,称为不公平的行为,或者称这样的 行为具有不公平性。歧视和偏见是与不公平相关联 的概念,不公平的行为又称为具有偏见的行为或者 歧视的行为。如果机器学习的预测或决策结果能够 确保每个人都有平等的机会获得一些利益,就称该 机器学习具有公平性,并称之为公平机器学习。公 平性研究已经有 50 余年的历史,无论概念定义、 还是度量标准都得到了极大的发展,不同文化具有 不同偏好和观点视角,导致了人们对公平存在多种 不同的理解方式。目前还没有公平性的普适定义, 为了满足各种应用需求,产生了各种各样的公平性 定义和概念。对于歧视类型的了解,有助于各种公 平性概念定义的理解[6]。下面讨论歧视的类型、公 平性定义及度量等。
歧视可以由三个层次的从属概念来刻画[35]:① 什么行为?②什么情况下?③对谁造成了歧视?行为是歧视的表现形式,情况是歧视的作用领域或 场景,而歧视的理由描述了受到歧视的对象的特 征。从造成歧视的理由是否有明确表述的角度,歧 视呈现直接性歧视和间接性歧视两种主要形式。从 歧视的行为是否能够被解释角度,歧视分为可解释 性歧视和不可解释性歧视。此外,系统性歧视刻画 了文化和习俗等方面的负面影响所带来的歧视,统 计性歧视刻画了社会成见的不良后果所导致的歧 视。


3 机器学习的公平性分析
机器学习各个阶段所涉及的数据、技术和算法 都可能存在导致模型预测不公平的偏见。偏见是引 发歧视和导致不公平的主要来源。本节对机器学习 中可能存在的各种形式的偏见以及不公平性的发 现技术等进行介绍和讨论。
精确方法
精确方法主要是基于离散优化 (DiscreteOptimization)理论来形式化验证神经网 络中某些属性对于任何可能的输入的可行性,即利 用可满足性模理论(Satisfiability Modulo Theories, SMT)或混合整数线性规划(Mixed Integer Linear Programming, MILP)来解决此类形式验证问题。这 类方法通常是通过利用 ReLU 的分段线性特性并在 搜索可行解时尝试逐渐满足它们施加的约束来实 现的。图 2 梳理了典型模型鲁棒性精确分析方法的 相关研究工作。
偏见的类型
Friedman 和 Nissenbaum 首先开展了偏见相关 方面的研究,给出了计算机系统中偏见分析的一个 框架,并结合应用案例进行了阐释[8]。Baeza-Yates 从数据、算法和用户交互等方面对网页生态系统中 的相关偏见进行了定义和剖析[57]。Olteanudeng 等 分析了数据平台及其相关技术特征,从产生的来源 和表现的形式,阐述总结了社交数据相关的偏见 [58]。Sures 和 Guttag 从数据生成、模型开发及部署 两阶段出发,定义和分析了机器学习中可能存在的 五种偏见[57]。本文从机器学习生命周期中所含的数 据管理、模型训练、模型评测、模型部署等阶段出 发[59],对各个阶段中存在的偏见进行了梳理(参见 图 3)。下面从数据、算法和人机交互三个方面(图 4),对机器学习中的主要偏见进行分类介绍和讨 论。

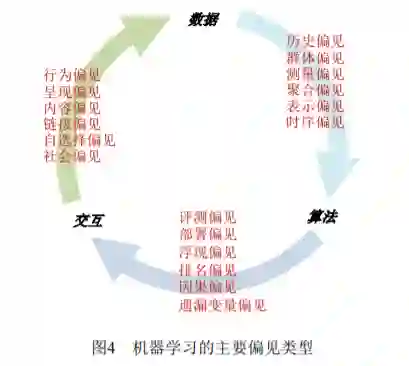
不公平的发现
发现机器学习的不公平是纠正偏见和消除歧 视的前提。歧视类型和偏见类别的概念定义为发现 不公平提供了不同视角下的可能技术路径。机器学 习中不公平发现的主要技术包括关联规则挖掘、k 最邻近分类、概率因果网络、隐私攻击和基于深度 学习的方法等。表 4 对不公平发现技术进行了对比。

4 公平机器学习的设计
为了开发公平机器学习系统或者确保机器学 习系统的公平性,人们建立了一系列公平机器学习 的设计方法。这些设计方法可以从三个维度来粗略 划分:其一,面向特定的机器学习任务,如,自然 语言处理、人脸识别、推荐系统、分类问题、回归 问题、聚类问题等;其二,针对专门的机器学习技术或算法,如,深度学习、强化学习、决策树学习、 集成学习、表示学习、对抗学习等;其三,依据机 器学习的生命周期,分为预处理、中间处理和后处 理[89, 90]。本文将从机器学习的生命周期维度,介绍 和讨论公平机器学习的设计。
5 公平性与隐私保护
隐私是个人或群体不愿意泄露的敏感信息,包 括身份、属性及其相关的数据。隐私保护就是通过 适当的政策法规和技术手段来保障个人或群体的 隐私不被泄露。公平性是确保个人或群体都有平等 的机会获得一些利益的行为的性质。不公平行为源 于基于个人或群体的敏感属性的带有偏见或歧视 的决策。对个人或群体敏感属性/数据进行隐私保护,可以防止歧视者获得并利用敏感属性/数据采取 带有偏见或歧视的决策。显然,公平性和隐私保护 有着一定的联系。
6 公平性与可解释性
解释是对概念或行为提供可理解的术语说明。机器学习的可解释性是指以人类或用户可以理解 的方式对其行为和结果进行说明的能力[176, 177]。一 方面,可解释性对于公平机器学习的应用部署具有 重要的意义,另一方面,可解释性能够对机器学习 的公平性满足与否进行说明和判定,有助于改善机 器学习的公平性。
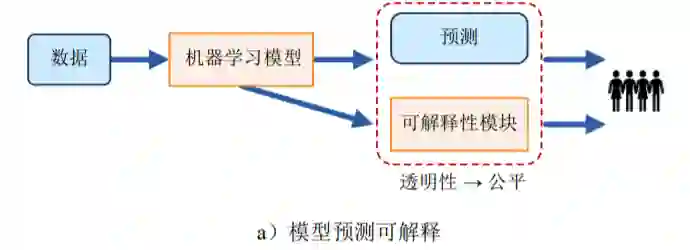
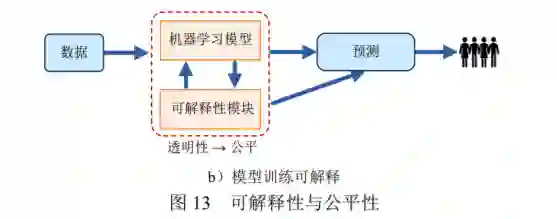
7 进一步工作展望
机器学习已经获得长足发展,基于机器学习的 预测/决策已逐渐渗透到人类社会的各个方面,在自 然语言处理、图像处理、个性化推荐、语音识别以 及自动驾驶等领域获得广泛应用,机器学习预测的 公平性直接影响着个人或群体的日常生活,影响着 用户对机器学习应用部署的信心和接受程度。虽然 公平机器学习逐渐受到了关注,但是总体而言,相 关研究尚处于起步阶段,仍存在许多亟待解决的问 题和挑战,如下是一些值得关注的研究:
(1)公平性定义及其度量歧视和公平是道德、政治、哲学、法学等人文 社科领域关注的热点问题,并且在多个方面仍然存 在争议[187]:公平应该是确保每个人都有平等的机 会获得一些利益,还是应该把对弱势群体的伤害降 到最低?是否可以通过参照某些特定的非歧视模 式来确定不公平性?隶属于自然科学技术领域的 机器学习的公平或非歧视又意味着什么?该领域 研究人员建立的 20 余种公平性的概念定义及度量 是否已经足够用来解决机器学习中的公平性问 题?现有的一些公平性概念定义及度量是不能被 同时满足的[50],如何处理这些冲突和不相容?如何 从最大限度降低弱势群体伤害、特定的非歧视模式 等视角,建立机器学习公平性的概念定义及度量?这些视角下的不公平性定义及度量与现有公平性 概念定义及度量是否存在不一致,如何协调和统 一?符合群组公平性的群组内个体是否存在不公 平?如何针对性地选择适合具体机器学习任务的 公平性度量?这些都是机器学习的公平性概念定 义及度量亟待解决的问题。
(2)公平机器学习的评测评测机器学习的不公平性是机器学习应用开 发和部署的必要环节[188, 189],对于提升机器学习的 可信性具有重要的意义[190]。FairTest 能够通过模型 输 出 结 果 和 受 保 护 群 体 之 间 的 无 根 据 关 联 (Unwarranted Associations),发现诱发不公平影响 的关联缺陷,测试可疑的缺陷,并帮助开发人员调 试降低不公平影响[191]。Themis 能够自动完成机器 学习模型的群组公平性测试及歧视因果分析,能通 过随机测试生成技术对不公平性进行定量评估 [192]。AEQUITAS 能够通过对输入训练数据随机采 样,发现导致个体不公平性的歧视性输入,检测出 个体不公平性漏洞,还能对机器学习模型再训练以 降低模型决策的不公平[193]。Agarwal 等使用符号执 行和局部可解释组合技术来生成个体公平性黑盒 测试的测试用例,其数量高达 Themis 的 3.72 倍[194]。此外,IBM、Microsoft 和 Google 等公司分别开发 出了 AIFairness 360、FairLearn 和 ML-fairness-gym 等公平性综合工具平台[195, 196],用于评测和消除机 器学习的不公平性。尽管如此,公平性测试研究还 相当有限。一方面,需要扩展已有机器学习模型的 测试技术[188, 189],使之能应用于公平性测试。另一 方面,在软件测试领域已有了成熟的技术和方法 [197],机器学习的公平性测试可以从中得到借鉴, 如,变异测试[193, 198]、蜕变测试[199, 200]、白盒测试[201] 等。
(3)公平机器学习新模式
机器学习概念复杂、种类丰富,当前关于公平机器学习的研究大多集中于决策树、朴素贝叶斯、 神经网络等方面,前文对此进行了着重介绍,但对 公平强化学习、公平联邦学习等的研究也已出现。强化学习依据奖励函数来选择行为策略,学习过程 的公平性体现于[202]:算法选择差行为的概率不会 高于选择好行为;算法不会偏好低质量的行为。公 平强化学习需要研究符合公平性的奖励函数和行 为策略设计算法。主分量分析会因群体的不同导致 不同的重构误差[203],公平主分量分析要求能够保 持不同群体具有相当的数据保真度(Fidelity)以实 现平衡的重构误差。动态公平性是为了适应群体的 时间演化特征而提出的[204, 205],动态公平机器学习 需要构建群体动态模型和决策反馈影响机制的学 习算法。迁移学习将某一任务的训练模型用于另一 任务,弥补了机器学习中训练数据的不足,公平迁 移学习需要克服从源域到目标域迁移过程中引发 的各种不公平[206]。联邦学习是一种分布式机器学 习范式,可以让成员在不共享数据的基础上联合建 模。联邦成员在共享加密的模型参数和中间计算结 果的同时,也会共享各自存在的不公平,甚至叠加 不公平。公平联邦学习需要有效的机制来避免这些 不公平性[207, 208]。元学习利用以往的经验知识来指 导新任务的学习,具有“学会如何学习”的能力,在 学会如何学习的同时,难免会积累历史的不公平。公平元学习需要研究消除不公平累积的学习策略 和记忆机制[209, 210]。适应需求和性能优良的机器学 习新模式不断提出,对此进行重点关注,集中产出 一批具备引领性、原创性、实用性的研究成果,进 一步研究建立集公平性为一体的新型公平机器学 习模式显得十分必要。
(4)符合伦理的机器学习
机器学习的公平性、隐私保护和可解释性是同 属人工智能伦理范畴的概念和属性。欧盟委员发布 的《可信赖 AI 的伦理指导原则》(Draft Ethics Guidelines for Trustworthy AI)指出,可信赖 AI 应 满足七个方面的条件要求:受人类监管、技术的稳 健性和安全性、隐私和数据管理、透明度、非歧视 性和公平性、社会和环境福祉、问责制等[211]。国际 电气电子工程师协会发布了《符合伦理设计:人工 智能和自主系统促进人类福祉的远景》(Ethically Aligned Design: A Vision for Prioritizing Human Well-being with Autonomous and Intelligent Systems)[212],对于人工智能和自主系统的伦理设 计提供了指导性建议。人工智能发展的新机遇得益于机器学习的成功,机器学习作为人工智能的一个 重要分支,在人类决策中发挥着愈来愈重要的作 用,机器学习应用的推广有赖于人们对其信任程度 的提高,符合伦理(Ethically Aligned)的机器学习 是必然的发展方向[213, 214, 215]。一方面,机器学习的 目标是模型预测的精准度,公平性、隐私保护、可 解释性等要求势必带来精准度的损失,这一矛盾是 可信赖 AI 需要折衷考虑的问题,以寻求不同要求 间的最优平衡;另一方面,当前针对可信赖 AI 的 研究大多是从公平性、隐私保护或可解释性等单一 维度进行的,而这些维度之间既存在某种程度上的 一致性,也存在相互制约的情形,因此,集成公平 性、可解释性、隐私保护的伦理机器学习的一体化 机制、算法、模式和框架是值得开展的研究[173, 174]。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“FMLS” 就可以获取《「公平机器学习」最新2022综述》专知下载链接




