Transformer多轮对话改写实践

本文介绍了多轮对话存在指代和信息省略的问题,同时提出了一种新方法-抽取式多轮对话改写,可以更加实用的部署于线上对话系统,并且提升对话效果。
1
背景
在日常的交流对话中,30%的对话会包含指代词。比如“它”用来指代物,“那边”用来指代地址;同时有50%以上的对话会有信息省略。具体可以看下面的示例。
| A1 | B1 | A2 | Label |
| 去哪里 | 长城北路公园 | 在什么地方 | 长城北路公园在什么地方 |
| 现在几点了 | 什么? | 快告诉我 | 快告诉我现在几点 |
| 确实江西炒粉要用瓦罐汤 | 特产? | 没错是我老家的特产 | 没错江西炒粉是我老家的特产 |
| 你喜欢张艺兴? |
是的 | 我也喜欢他 |
我也喜欢张艺兴 |
这张图演示了一个人机对话过程中,人(A)和系统(B)的交流过程。用户的真实意思label是对用户上一句说的话A2进行信息还原(改写)
因此在对话系统中需要结合对话的上下文才可以更好的对用户输入的语句做语义理解。
前几天有一篇论文介绍中文多轮对话的数据集[crosswoz数据集]。文中提出了一种BertContext nlu的方法利用对话历史向量增强对多轮对话语句的语义理解能力,效果非常好。但是这种方法需要大量的意图和槽的标注工作。多轮对话的数据标注工作是比较困难的,同时该方法对语句中指代槽的提取也无能为力,只能根据对话状态获取。
对于任务型对话,是可以对用户状态进行追踪。然后根据用户状态结合当前用户的输入知道用户的真实目的。目前用户状态追踪用规则做比较稳定。但是这种方法就需要我们去写很多状态机做状态之间的转移,比较繁琐。同时指代消岐和信息省略的处理能力也很低。
对于聊天系统,用户的状态就更难进行标注。
因此考虑起充分利用上下文来增强对话的语义理解能力就是一个很好的选项。其中一个有前途有实际落地效果的就是对话改写。
改写就是根据用户的聊天内容,把用户此时此刻说的话补全。输入是用户A和系统B的对话历史,然后对用户下一句说的话utterance改写为label。改写之后label里面包含了用户表达的完整信息。再通过检索信息或者语义理解引擎就可以更好的执行相应的对话策略。
去年有一篇论文介绍多轮对话改写[1],使用的方法是基于PointNetwork的生成方法,利用copy机制取得了很好的效果。这篇论文将会成为本文 的baseline。这里复现的时候没有和原论文一样分割输入,而是把输入全部连接做attention。
基于生成的方法有两个主要缺点。1是速度慢,beamsearch部分解码套路多[参考文章];2是对训练数据需求量大。Baseline论文还有一个重要的贡献是放出了一批一万多条的改写数据集,本文的实验数据也主要基于它。
2
方法
通过分析用户的对话数据,可以发现大部分的对话数据要么是正常的不用改写,要么就是用了信息省略或者指代词。因此对话改写的任务有两个:1这句话要不要改写;2 把信息省略和指代识别出来。对于baseline论文放出的数据集,有90%的数据都是简单改写,也就是满足任务2,只有信息省略或者指代词。少数改写语句比较复杂,本文训练集剔除他们,但是验证集保留。
对于用户和系统的对话历史,本文用A1/B1来分别表示用户说的话和系统的回复。对于用户说的话A2,本文要将它改写为label。
首先需要根据训练集里面label对A2做的操作进行有格式的还原。我发现90%的改写数据都满足以下两种模式之一。

对于指代消岐类,先是识别A2中的指代词“他”,同时识别出上下文中的关键信息“张艺兴”,然后替换掉“他“。

对于信息补全类,先是识别出上下文中的关键信息“天气”,然后识别出A2中需要补全信息的位置在"呢"之前。
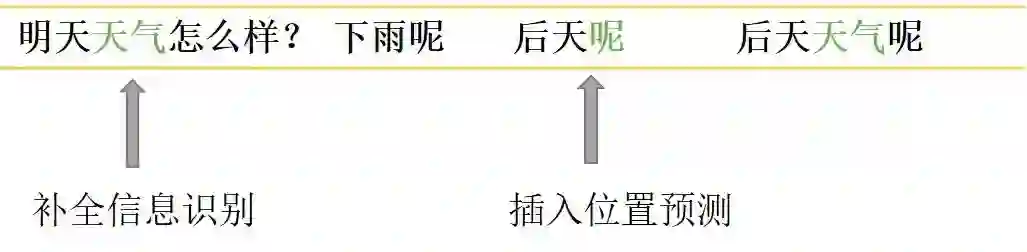
因此对于文本改写,我们可以理解为就是完成上述两个任务(可以准确覆盖90%的改写)。这里我们(微信公众号:朴素人工智能)使用了五个指针来做改写任务的预测。首先把用户输入A1和系统回复B1连接起来,再和用户输入A2(待改写语句)一起作为模型输入。中间采用transformers结构进行特征提取,也可以使用预训练的transformers比如bert或者rbt3。
Transformers结构可以通过attention机制有效提取指代词和上下文中关键信息的配对,最近也有一篇很好的工作专门用Bert来做指代消岐[2]。经过transformer结构提取文本特征后,模型结构及输出如下图。
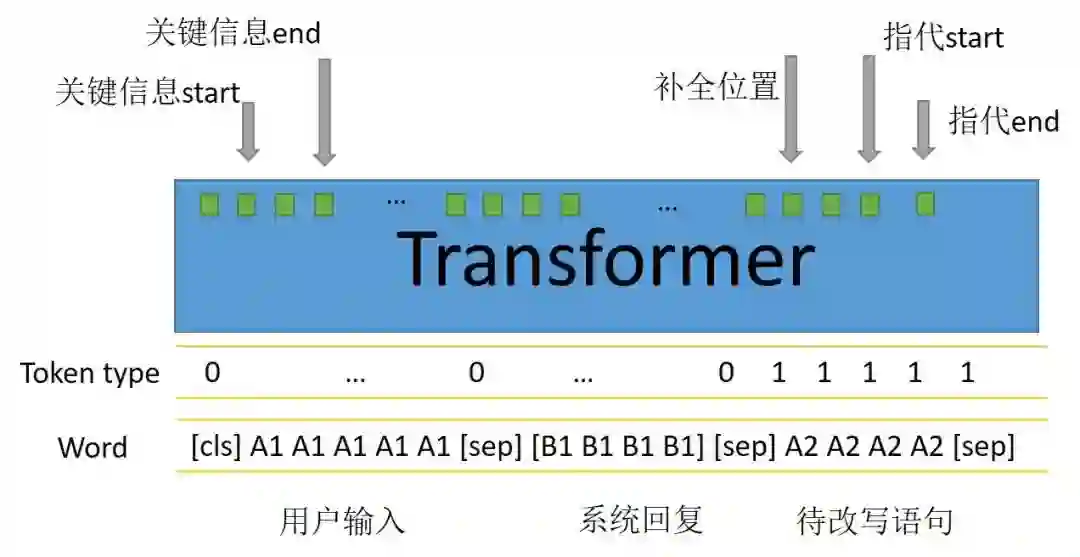
输出五个指针中:
关键信息的start和end专门用来识别需要为下文做信息补全或者指代的词;
补全位置用来预测关键信息(start-end)插入在待改写语句的位置,实验中用插入位置的下一个token来表示;
指代start和end用来识别带改写语句出现的指代词。
当待改写语句中不存在指代词或者关键信息的补全时,指代的start和end将会指向cls,同理补全位置也这样。如同阅读理解任务中不存在答案一样,这样的操作在做预测任务时,当指代和补全位置的预测最大概率都位于cls时就可以避免改写,从而保证了改写的稳定性。
3
实验结果与分析
本文对其中github中多轮对话改写数据中取了15000条做训练集,剩下2000条做验证集观察模型训练效果。本文和baseline模型用的encoder都是3层transformer的rbt3预训练模型。
3.1验证集上效果比较
| rouge-1 |
rouge-2 |
rouge-l |
|
| Baseline |
0.906 |
0.836 |
0.897 |
| 本文 |
0.907 |
0.827 |
0.88 |
Baseline基于完全copy机制的生成方法效果也非常好,本文所采用的抽取式效果相当。
备注:
1)Rouge-1
rouge-1 比较生成文本和参考文本之间的重叠词(字)数量
2) Rouge-2
rouge-2 比较生成文本和参考文本之间的 2-gram 重叠的数量
3) Rouge-L
rouge-l 根据生成文本和参考文本之间的最长公共子序列得出
3.2预测时间消耗(2000条)
| 时间 |
|
| Baseline |
1min |
| 本文 |
2s |
在小破卡上,baseline模型需要一个一个解码,预测速度慢。本文的方法采用指针预测法速度很快,具备大规模上线应用的可能性。
3.3对训练样本数的依赖
训练集样本数依次选择15000,5000,1000,500条,观察文本改写效果。验证集同上仍为2000条。
| rouge-1 |
15000 |
5000 |
1000 |
500 |
| Baseline |
0.906 |
0.865 |
0.375 |
0.09 |
| 本文 |
0.907 |
0.872 | 0.8 |
0.794 |
生成式改写任务对数据依赖比较高,即使baseline模型采用的是完全copy的机制。抽取式文本改写在小数据集上也可以产生很好的效果。这和基于序列标注的文本生成模型LaserTagger得出的结论是一致的。
3.4对负样本(不需要改写样本)的识别
本文将验证集的label作为输入给模型做改写,改写后的结果和原label进行比较。
| rouge-1 |
rouge-2 |
rouge-l |
|
| Baseline |
0.92 |
0.893 |
0.955 |
| 本文 |
0.938 |
0.926 |
0.965 |
基于指针抽取的方法对负样本的识别效果会更好。同时根据对长文本的改写效果观察,生成式改写效果较差。
3.5 改写效果一览
从左到右依次是A1|B1|A2|算法改写结果|用户标注label
你知道板泉井水吗 | 知道 | 她是歌手 | 板泉井水是歌手 | 板泉井水是歌手
乌龙茶 | 乌龙茶好喝吗 | 嗯好喝 | 嗯乌龙茶好喝 | 嗯乌龙茶好喝
武林外传 | 超爱武林外传的 | 它的导演是谁 | 武林外传的导演是谁 | 武林外传的导演是谁
李文雯你爱我吗 | 李文雯是哪位啊 | 她是我女朋友 | 李文雯是我女朋友 | 李文雯是我女朋友
舒马赫 | 舒马赫看球了么 | 看了 | 舒马赫看了 | 舒马赫看球了
4
小结
通过大量实验,可以得出如下结论。
抽取式文本改写和生成式改写效果相当
抽取式文本改写速度上绝对优于生成式
抽取式文本改写对训练数据依赖少
抽取式文本改写对负样本识别准确率略高于生成式
因此本文设计的方法更加适合线上多轮对话的改写。后续我们也会开源多种方法实现对话改写的代码。
[1]Improving Multi-turn Dialogue Modelling with Utterance ReWriter
[2]Coreference Resolution as Query-based Span Prediction
[3] https://github.com/chin-gyou/dialogue-utterance-rewriter
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



