基于PaddlePaddle的业界首个开源视频识别工具集重磅发布
视频识别工具集为开发者提供一系列较全的、效果和主流实现打平的视频分类模型。用户可一键式任务启动,构建大规模视频分类训练,从而解决视频理解、视频打标签、视频内容审核等任务,后续会继续扩展视频动作检测、视频生成等模型。
许多深度学习的文章和教程主要关注三个数据领域:图像,语音和文本。这些数据在图像分类,语音识别和文本情感分类中起到了至关重要的作用。此外,还有一种非常有趣的数据形式——视频。一方面,越来越多的视频录像设备的普及,让更多好玩有趣的视频丰富了人们的业余生活;另一方面,如何快速有效地浏览大量视频数据并将其分类, 这对于提升用户体验,挖掘潜在的商业价值显得异常重要。简而言之,视频分类就是给定一个视频片段,百度对视频中包含的内容进行分类。因为在数量巨大的视频中, 分类和标签是搜索视频的重要依据,视频能否被更多人看到, 能否受大家欢迎, 很大程度上取决于分类和标签填写是否恰当。
在了解了视频分类的基础概念之后,让人类来和机器 PK 一下,看看谁才是拥有更高准确率的『视频鉴别员』。请大家先看视频 1 和视频 2,并用一个词来总结这段视频的内容,给出他们你们心目中的分类:
这两个视频官方标注的分类是 1:鼓掌 (Applauding) 2:拆礼物 (Wrapping Present)
这个分类结果是专门的视频分类人员在观看完视频后给贴的视频标签。大家可能各有各的想法,各有各的分类标签(比如 1 是鬼畜舞,2 是拆包包等等),但都是基于大家观看完视频之后根据自我的关注侧重点以及自身经验得出的结论。当看到官方标注的分类标签后,我们最起码也是认可和赞同的。那么拥有了人工智能的机器会如何对这些视频分类呢?
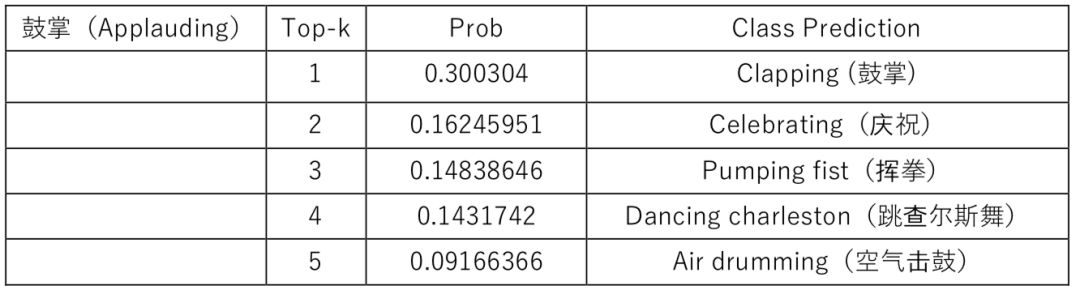
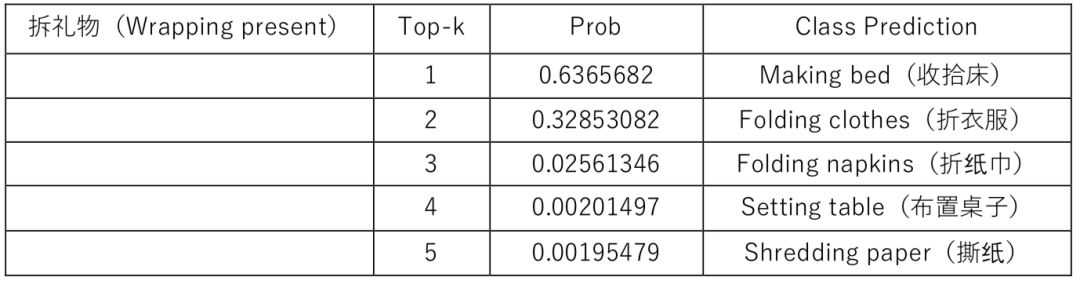
如表 1 和表 2 所示,第一列是官方视频分类标签,后三列显示了机器预测结果的前五个分类结果,按照置信概率将五个预测结果进行降序展示。显而易见的是第一个视频中的鼓掌动作行为还是被机器很好的预测了出来。至于第二个拆礼物行为,确实没有一个正确的预测结果,机器还比较充分的相信这是一个收拾床的行为,在这一点上,人类的识别准确率还是远高于机器识别的准确率。
所以结论是:在视频分类方面,人类的识别准确率远胜于机器,因此人人皆可『视频鉴别员』。
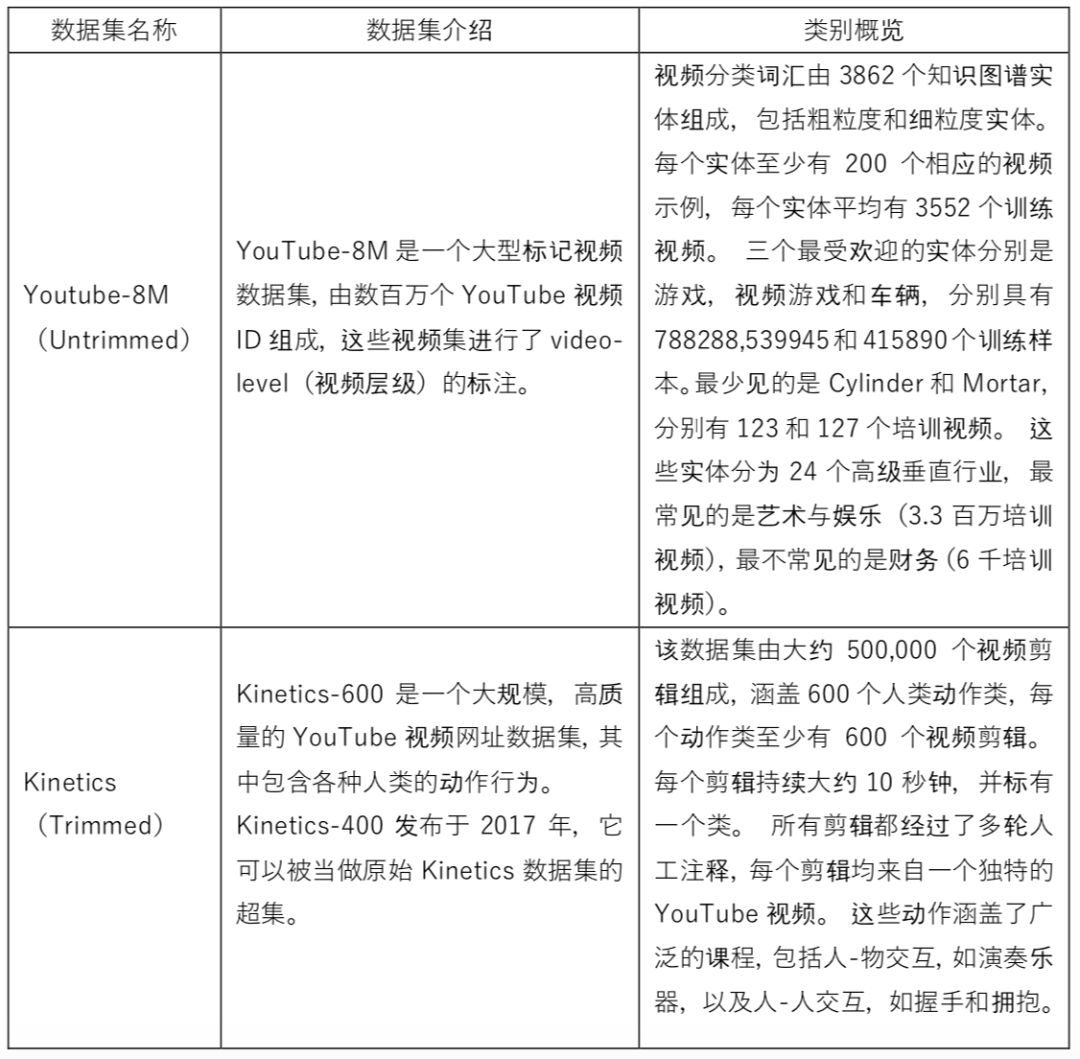
虽然网络上有大量用户上传的视频数据,但是这些数据大多缺少视频分类标签,如果直接拿过来使用进行训练会导致效果不佳。在学术届,通常会有一些公开的、已经打过完整标签的数据集来进行算法训练。对于视频分类领域,主要包含两大类数据集,一类是剪辑过的(trimmed),另一类是未剪辑过的(untrimmed)。前者是指经过剪辑的视频只包含待识别类别的内容;后者是指未经过剪辑的视频会包含除了动作/场景/物体之外的其他很多信息。
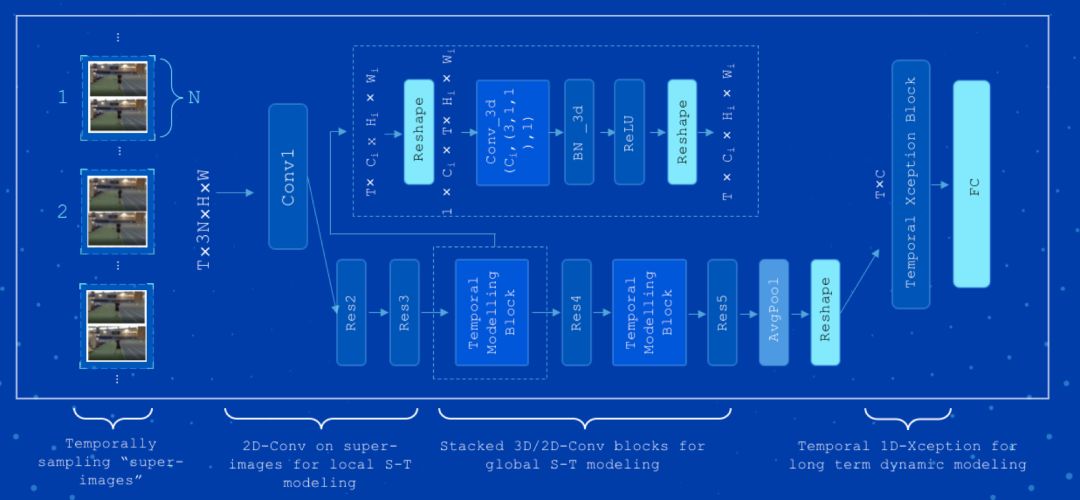
先来介绍百度的自研模型 StNet 模型、Attention Cluster 模型和 Attention LSTM 模型。其中 StNet 模型发表于 AAAI2019,由于拥有卓越的分类能力,它曾助力百度计算机视觉团队夺取了 ActivityNet Kinetis Challenge 2018 挑战赛的冠军。该模型提出“super-image"的概念,在 super-image 上进行 2D 卷积,建模视频中局部时空相关性。另外通过 temporal modeling block 建模视频的全局时空依赖,最后用一个 temporal Xception block 对抽取的特征序列进行长时序建模。该框架在动作识别方面优于一些最先进的方法,可以在识别精度和模型复杂性之间取得令人满意的平衡。图 1 为 StNet 模型的框架结构:
视频识别工具集提供了了基于 Kinetics 数据集训练出的 StNet 模型:
https://paddlemodels.bj.bcebos.com/video_classification/stnet_kinetics.tar.gz
Attention Cluster 采用了视频多模态特征注意力聚簇融合方法,曾助力百度计算机视觉团队夺得 2017 年的 Kinetics600 大赛冠军。该模型通过带 Shifting operation 的 Attention clusters,处理经过 CNN 模型抽取特征的视频的 RGB、光流、音频等数据,实现视频分类。图 2 为 Attention Cluster 模型的框架结构。
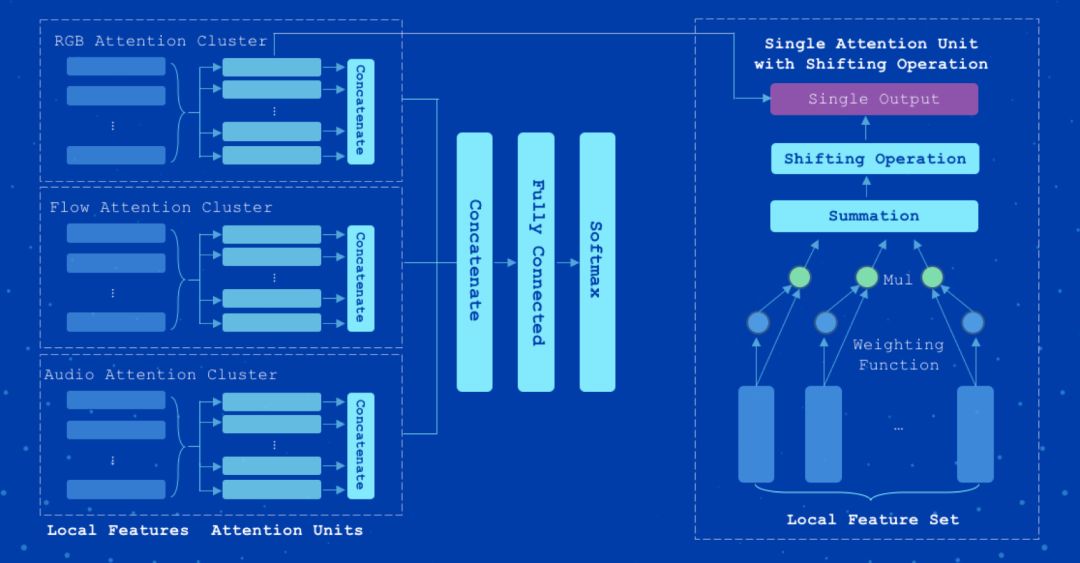
以下模型是基于 Youtube-8M 训练出的 Attention cluster 模型:
https://paddlemodels.bj.bcebos.com/video_classification/attention_cluster_youtube8m.tar.gz
Attention LSTM 是视频分类中的常用模型,具有速度快精度高的特征。该模型采用了双向长短记忆网络(LSTM),将视频的所有帧特征依次编码。与传统方法直接采用 LSTM 最后一个时刻的输出不同,该模型增加了一个 Attention 层,每个时刻的隐状态输出都有一个自适应权重,然后线性加权得到最终特征向量。图 3 是 Attention LSTM 的框架结构。
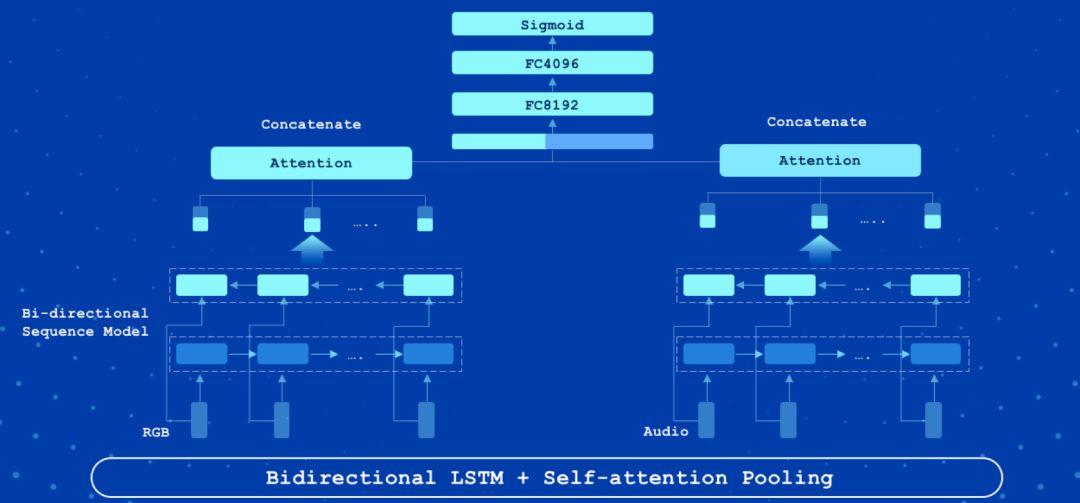
以下是基于 2nd-Youtube-8M 数据集训练的 Attention LSTM 模型:
https://paddlemodels.bj.bcebos.com/video_classification/attention_lstm_youtube8m.tar.gz
NeXtVLAD 是 2nd-Youtube-8M 比赛中最佳单模型,该模型弱化了时序关系,适合建模短视频。图 4 为 NeXtVLAD 模型的框架结构。
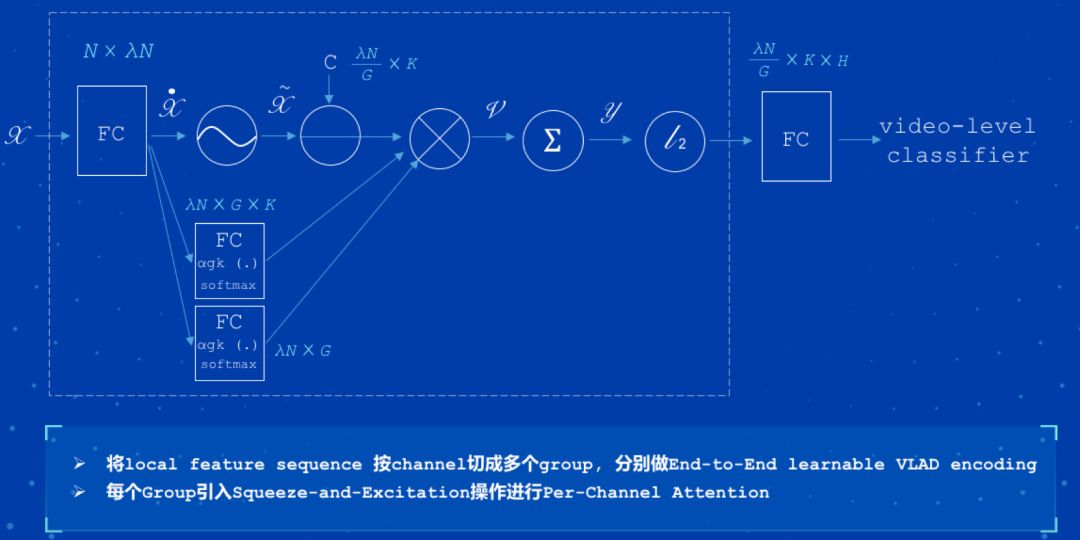
以下是基于 Youtube-8M 数据集训练的 NeXtVLAD 模型:
https://paddlemodels.bj.bcebos.com/video_classification/nextvlad_youtube8m.tar.gz
Nonlocal 是视频非局部关联建模模型,该模型通过引入类似 self-attention 机制,计算效果好,但是计算量大。图 5 为 Nonlocal 模型的框架结构。
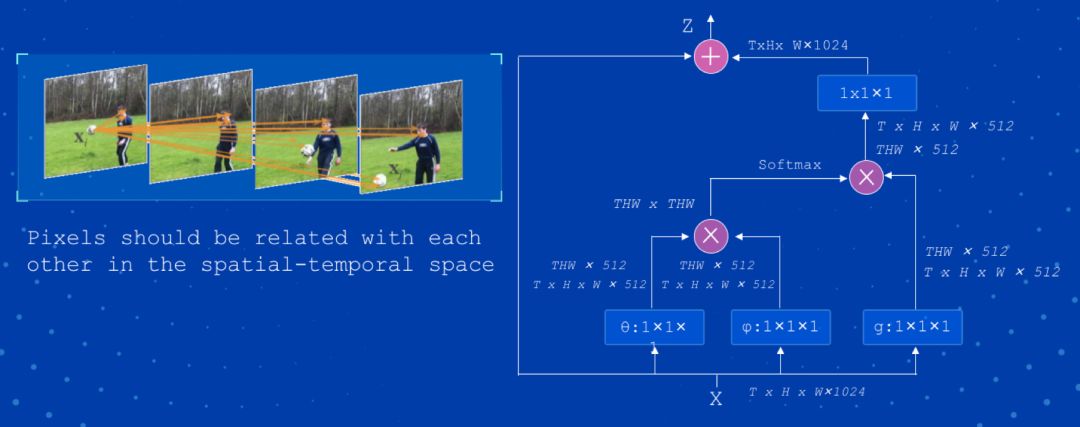
以下是基于 Kinetics 数据集训练的 Nonlocal 模型:https://paddlemodels.bj.bcebos.com/video_classification/nonlocal_kinetics.tar.gz
TSN 模型是基于 2D-CNN 经典模型,首次引入序列信息到视频分类,证明序列信息有效性。图 6 为 TSN 模型的框架结构。

以下是基于 Kinetics 数据训练的 TSN 模型:https://paddlemodels.bj.bcebos.com/video_classification/tsn_kinetics.tar.gz
TSM 在 TSN 基础上进行了改进,应用基于时序移位的简单高效视频时空建模方法。该模型简单高效,计算简单。图 7 为 TSM 模型的框架结构。
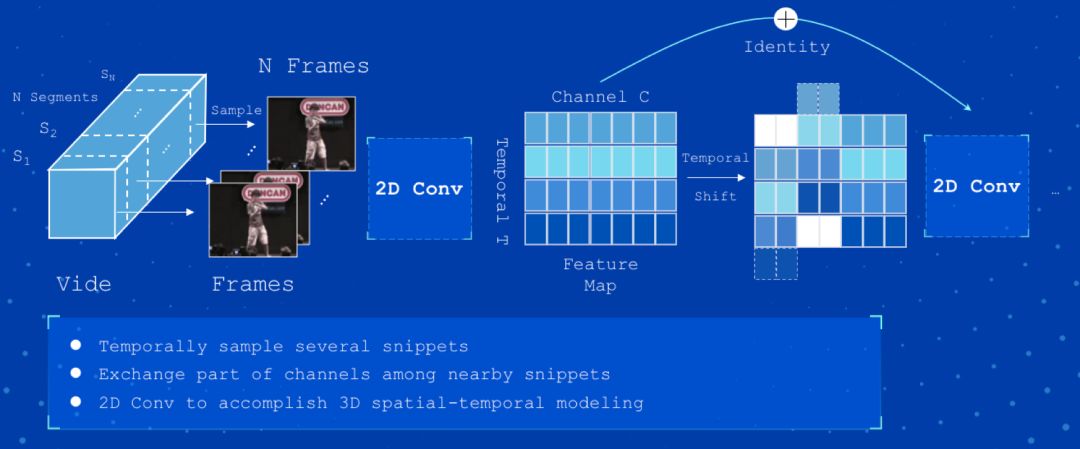
以下是基于 Kinetics 数据训练的 TSM 模型:https://paddlemodels.bj.bcebos.com/video_classification/tsm_kinetics.tar.gz
大家可以根据自己的需要,选择加载不同的模型。
这一部分,我们就以 StNet 网络模型来作为样例,教大家如何快速上手,而不只是停留在看和理解的境地。快速上手所获得成就感,才会帮助大家更好的使用 PaddlePaddle 视频识别工具集。
视频模型库提供通用的 train/test/infer 框架,通过 train.py/test.py/infer.py 指定模型名、模型配置文件等可一键式进行训练和预测。
以 StNet 模型为例:
单卡训练:

多卡训练:

同时我们也提供快速启动脚本(方法2):

可通过如下两种方式进行模型评估:
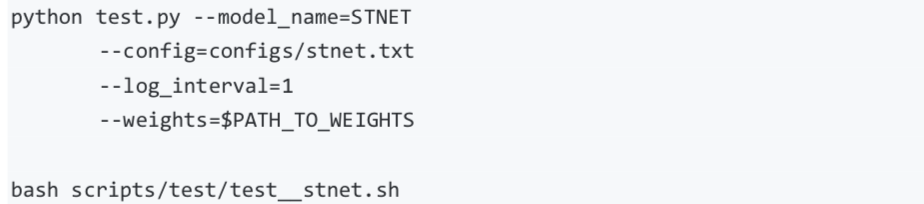
注 1:使用 scripts/test/test_stnet.sh 进行评估时,需要修改脚本中的 --weights 参数指定需要评估的权重。
2:若未指定 --weights 参数,脚本会下载已发布模型 model 进行评估
可通过如下两条命令进行模型推断:

注 1:模型推断结果存储于 STNET_infer_result 中,通过 pickle 格式存储。2:若未指定 --weights 参数,脚本会下载已发布模型 model 进行推断
大家可以用我们预训练好的模型去随意分类自己的视频,比比看谁更厉害哦!
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/video
Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification, Xiang Long, Chuang Gan, Gerard de Melo, Jiajun Wu, Xiao Liu, Shilei Wenhttps://arxiv.org/abs/1711.09550Beyond Short Snippets: Deep Networks for Video Classification Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, George Toderici
https://arxiv.org/abs/1503.08909
NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification, Rongcheng Lin, Jing Xiao, Jianping Fanhttps://arxiv.org/abs/1811.05014
StNet:Local and Global Spatial-Temporal Modeling for Human Action Recognition, Dongliang He, Zhichao Zhou, Chuang Gan, Fu Li, Xiao Liu, Yandong Li, Limin Wang, Shilei Wen
https://arxiv.org/abs/1811.01549
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition, Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, Luc Van Gool
https://arxiv.org/abs/1608.00859
Temporal Shift Module for Efficient Video Understanding, Ji Lin, Chuang Gan, Song Hanhttps://arxiv.org/abs/1811.08383v1
Non-local Neural Networks, Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He
https://arxiv.org/abs/1711.07971v1
想了解百度 PaddlePaddle 更多的开源项目么?点击 阅读原文 即可获得项目地址。
评论留言写下你的“深度学习学习心得”,优质留言点赞前三名的童鞋将每人获得深度学习书籍一本~



